




 该博客详细解析了《ImageNet Classification with Deep Convolutional Neural Network》论文,重点介绍了网络架构的创新点,包括ReLU非线性、多GPU训练、局部响应归一化和重叠池化的应用。ReLU因其非饱和性质加速了训练,多GPU训练提高了效率,局部响应归一化模拟神经元竞争,重叠池化提升了模型的预测精度并缓解过拟合。此外,文章还概述了整体网络结构,包括5个卷积层和3个全连接层。
该博客详细解析了《ImageNet Classification with Deep Convolutional Neural Network》论文,重点介绍了网络架构的创新点,包括ReLU非线性、多GPU训练、局部响应归一化和重叠池化的应用。ReLU因其非饱和性质加速了训练,多GPU训练提高了效率,局部响应归一化模拟神经元竞争,重叠池化提升了模型的预测精度并缓解过拟合。此外,文章还概述了整体网络结构,包括5个卷积层和3个全连接层。
- 结构
我们的网络架构概括为图2。
它包含八个学习层--5个卷积层和3个全连接层。
下面,我们将描述我们网络结构中的一些新奇的不寻常的特性。
3.1-3.4小节按照我们对它们评估的重要性进行排序,最重要的最优先。
3.1 ReLU Nonlinearity(ReLU非线性 最优先)
将神经元输出f建模为输入x的函数的标准方式是用f(x) = tanh(x)或f(x) = (1 + e−x)−1。考虑到梯度下降的训练时间,这些饱和的非线性*比非饱和非线性*f(x) = max(0,x)更慢。
饱和的非线性*比非饱和非线性
(1)直观理解
饱和激活函数会压缩输入值。
(2)定义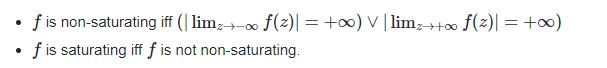
(3)举例
对于Rectified Linear Unit (ReLU)激活函数f(x) = max(0, x),当x趋于正无穷则f(x)也趋于正无穷。所以该函数是非饱和的。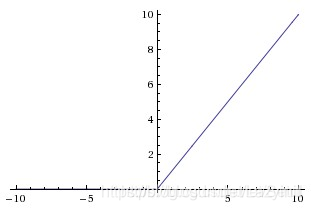
sigmoid函数的范围是[0, 1]所以是饱和的。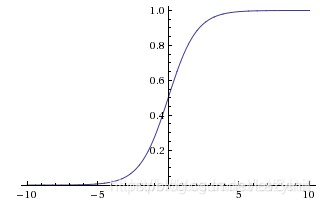
tanh函数也是饱和的,因为其取值范围为[-1,1]。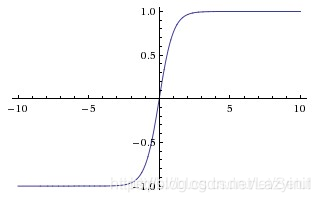
标准的L-P神经元的输出一般使用tanh 或 sigmoid作为激活函数, ![]() 。但是这些饱和的非线性函数在计算梯度的时候都要比非饱和的现行函数
。但是这些饱和的非线性函数在计算梯度的时候都要比非饱和的现行函数![]() 慢很多,在这里称为 Rectified Linear Units(ReLUs)。
慢很多,在这里称为 Rectified Linear Units(ReLUs)。
在深度学习中使用ReLUs要比等价的tanh快很多。
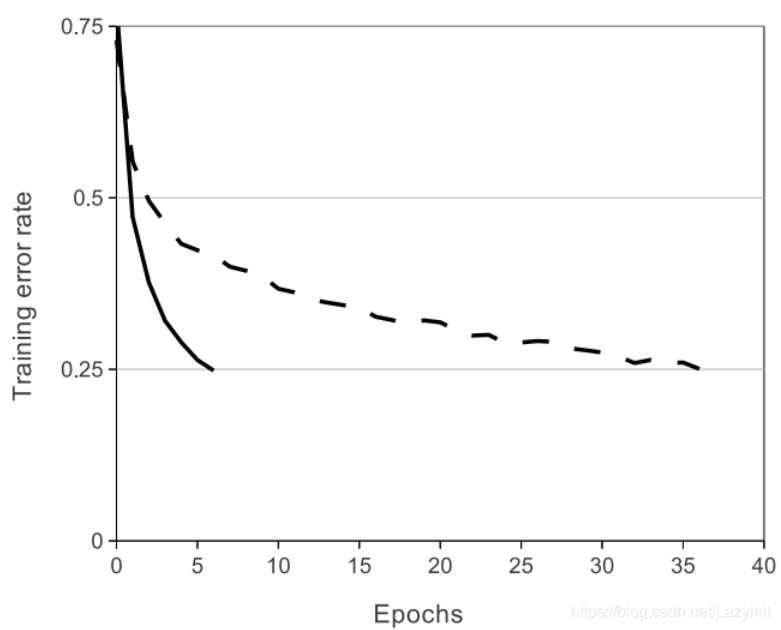
上图是使用ReLUs和tanh作为激活函数的典型四层网络的在数据集CIFAR-10s实验中,error rate收敛到0.25时的收敛曲线,可以很明显的看到收敛速度的差距。
虚线为tanh,实线是ReLUs;
3.2 Training on Multiple GPUs
GPU:图形处理单元,是一种单芯片处理器,主要用于提高视频和图形性能;
本文使用多GPU训练的方式提高效率,这里只做简单了解;
3.3 Local Response Normalization局部响应归一化
响应归一化的顺序实现了一种侧抑制形式,灵感来自于真实神经元中发现的类型,为使用不同核进行神经元输出计算的较大活动创造了竞争。
我是没理解这是啥意思。---理解了已经!
侧抑制:

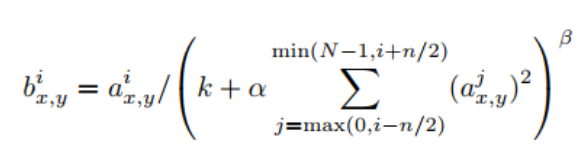
公式看上去比较复杂,但理解起来非常简单。i表示第i个核在位置(x,y)运用激活函数ReLU后的输出,n是同一位置上临近的kernal map的数目,N是kernal的总数。参数K,n,alpha,belta都是超参数,一般设置k=2,n=5,aloha=1*e-4,beta=0.75。
3.4 Overlapping Pooling
CNN中的池化层归纳了同一核映射上相邻组神经元的输出。习惯上,相邻池化单元归纳的区域是不重叠的(例如[17, 11, 4])。更确切的说,池化层可看作由池化单元网格组成,网格间距为ss ss个像素,每个网格归纳池化单元中心位置z×z大小的邻居。如果设置s=z,我们会得到通常在CNN中采用的传统局部池化。如果设置s<z,我们会得到重叠池化。这就是我们网络中使用的方法,设置s=2s=2 s = 2s=2,z=3z=3 z = 3z=3。这个方案分别降低了top-1 0.4%,top-5 0.3%的错误率,与非重叠方案s=2,z=2相比,输出的维度是相等的。我们在训练过程中通常观察采用重叠池化的模型,发现它更难过拟合。
相对于传统的no-overlapping pooling,采用Overlapping Pooling不仅可以提升预测精度,同时一定程度上可以减缓过拟合。
相比于正常池化(步长s=2,窗口z=2) 重叠池化(步长s=2,窗口z=3) 可以减少top-1, top-5分别为0.4% 和0.3%;重叠池化可以避免过拟合。
3.5 Overall Architecture 整体结构
待详解…………..
8个带权重的层,前5层是卷积层,剩下3层是全连接层。最后一层是1000维softmax输入


完整的AlexNet网络结构如下:
[227x227x3] INPUT
[55x55x96] CONV1: 96 11x11 filters at stride 4, pad 0 注:(227 - 11)/ 4 + 1 = 55
[55x55x96] RELU1: activation
[27x27x96] MAX POOL1: 3x3 filters at stride 2 注:(55 - 3)/ 2 + 1 = 27
[27x27x96] NORM1: Normalization layer
[27x27x256] CONV2: 256 5x5 filters at stride 1, pad 2 注:(27+2x2-5)/ 1 + 1 = 27
[27x27x256] RELU2: activation
[13x13x256] MAX POOL2: 3x3 filters at stride 2 注:(27-3)/ 2 + 1 = 13
[13x13x256] NORM2: Normalization layer
[13x13x384] CONV3: 384 3x3 filters at stride 1, pad 1 注:(13+1x2-3)/ 1 + 1 = 13
[13x13x384] RELU3: activation
[13x13x384] CONV4: 384 3x3 filters at stride 1, pad 1 注:(13+1x2-3)/ 1 + 1 = 13
[13x13x384] RELU4: activation
[13x13x256] CONV5: 256 3x3 filters at stride 1, pad 1 注:(13+1x2-3)/ 1 + 1 = 13
[13x13x256] RELU5: activation
[6x6x256] MAX POOL3: 3x3 filters at stride 2 注:(13-3)/ 2 + 1 = 6
[4096] FC6: 4096 neurons
[4096] RELU6: activation
[4096] DROPOUT
[4096] FC7: 4096 neurons
[4096] RELU7: activation
[4096] DROPOUT
[1000] FC8: 1000 neurons (class scores)


















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









