







CAS(compareAndSwap):比较并替换
在具体了解cas机制之前,我们先来看两个案例:
(1)示例:启动两个线程,每个线程中让静态变量count循环累加100次。
那么最终count结果是多少?一定是200吗?
public static int count = 0;
public static void main(String[] args){
// 开启两个线程
for(int i = 0;i < 2;i++){
new Thread(
new Runable(){
public void run(){
try{
Thread.sleep(10);
} catch (InterruptedException e){
e.printStackTrace();
}
for(int j = 0;j < 100;j++){
count++;
}
}
}
).start();
}
try{
Thread.sleep(2000);
} catch(InterruptedException e){
e.printStackTrace();
}
System.out.println("count = " + count);
}
这段代码并不是线程安全的,所以结果count有可能是小于200的
为了保证count输出结果是200,我们可以加上Synchronuzed同步锁
public static int count = 0;
public static void main(String[] args){
// 开启两个线程
for(int i = 0;i < 2;i++){
new Thread(
new Runable(){
public void run(){
try{
Thread.sleep(10);
} catch (InterruptedException e){
e.printStackTrace();
}
for(int j = 0;j < 100;j++){
Synchronized(当前类.class){
count++;
}
}
}
}
).start();
}
try{
Thread.sleep(2000);
} catch(InterruptedException e){
e.printStackTrace();
}
System.out.println("count = " + count);
}
加入同步锁之后,count自增就变成了原子性操作,所以最终输出的结果一定是200,代码实现了线程安全。
但是Synchronized关键字会让没有得到锁资源的线程进入BLOCKED状态,在争夺到锁资源后恢复为runnable状态,这个过程之后牺牲的性格比较大,尽管java1.6对其进行了优化(偏向锁->轻量级锁->重量级锁),但是Synchronized仍然存在性能较低的情况
(2)我们经常使用volatile关键字修饰某一个变量,表明这个变量是全局共享的一个变量,同时具有了可见性和有序性。但是却没有原子性。比如说一个常见的操作a++。这个操作其实可以细分成三个步骤:
(1)从内存中读取a
(2)对a进行加1操作
(3)将a的值重新写入内存中
在单线程状态下这个操作没有问题,但是在多线程中就会出现各种各样的问题。因为可能一个线程对a进行了加1操作,还没来得及写入内存,其他的线程就读取了旧值。造成了线程的不安全现象。如何去解决这个问题呢?
解决办法:
通过java中的原子操作类:
所谓原子操作类,指的是java.util.concurrent.atomic包下,一系列以atomic开头的包装类,例如AtomicBoolean,AtomicInteger,AtomicLong。它们分别用于boolean,integer,long类型的原子性操作。
通过原子操作类,我们可以将案例1中的代码修改为
public static AtomicInteger count = new AtomicInteger(0);
public static void main(String[] args){
// 开启两个线程
for(int i = 0;i < 2;i++){
new Thread(
new Runable(){
public void run(){
try{
Thread.sleep(10);
} catch (InterruptedException e){
e.printStackTrace();
}
for(int j = 0;j < 100;j++){
count.incrementAndGet();
}
}
}
).start();
}
try{
Thread.sleep(2000);
} catch(InterruptedException e){
e.printStackTrace();
}
System.out.println("count = " + count);
}
这样最终count的输出结果同样可以保证是200,而且性能比Synchronized要高。
incrementAndGet方法底层
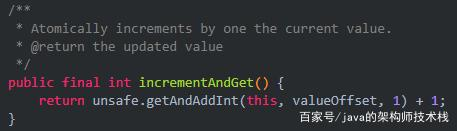
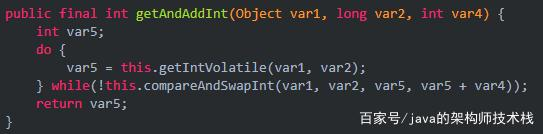
Atomic操作类的底层,compareAndSwapInt方法其实就是CAS机制
分析CAS
cas包含 3 个参数 CAS(V,A,B),V表示内存地址,A表示旧的预期值(可以理解为原值),B表示要修改的新值(更改成功后的值)。仅当 V值等于A值时(内存地址中对应的值与原值相同),才会将V的值设为B,如果V值和A值不同,则说明已经有其他线程做了更新,则当前线程则什么都不做。最后,CAS 返回当前V的真实值(其实此时内存地地址存储的已经是其他线程更改之后的最新值)。
示例:
V = 1,A = 1,B = 2
1.线程1想要将原有值+1,即A = 2,在提交更新之前
2.此时线程2抢先一步,将V中的值率先更新为2(其实线程1要做的事)
3.线程1提交更新失败,因为此时V = 2,A = 1,A != V;
4.接下来线程1重新获取V值,并计算想要修改的新值,此时对于线程1来说,V=2,A=2,B=3,这个重新尝试的过程称为自旋
5.这时没有其他线程抢先更新,V = A ,线程1成功提交更新,最终V = 3;
Synchronized属于悲观锁,CAS属于乐观锁
在java中,Atomic系列类,Lock系列类的底层实现都采用了CAS机制
java1.6以上版本,Synchronized转变为重量级锁之前,也会采用CAS机制
CAS优点
cas是一种非阻塞的轻量级的乐观锁,什么是非阻塞式的呢?其实就是一个线程想要获得锁,对方会给一个回应表示这个锁能不能获得。在资源竞争不激烈的情况下性能高,相比synchronized重量锁,synchronized会进行比较复杂的加锁,解锁和唤醒操作。
CAS缺点
1:cpu开销比较大
在并发量比较大的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,会给cpu带来较大的压力
在某些并发量较大的场景,synchronized反而效率更高
2:不能保证代码块的原子性
CAS机制保证的只是一个变量的原子性操作,并不能保证代码块的原子性,如果需要多变量同时进行原子性的更新,需要使用synchronized
3:ABA问题
假设一个变量 A ,修改为 B之后又修改为 A,CAS 的机制是无法察觉的,但实际上已经被修改过了
示例:老王有100元存款,需要使用一个提款机来提取50元
提款机年久失修,将提款操作提交了两次,开启了两个线程
线程1:获取当前值100元->更新为50元 V = 100,A = 100,B = 50
线程2:获取当前值100元->更新为50元 V = 100,A = 100,B = 50
正常情况下线程1成功后,线程2会失败,因为此时 V = 50,A = 100;
现在线程1执行成功了,但是线程2在获取到V = 100 后阻塞了,在线程2阻塞的同时,老王的媳妇刚好给老王汇款50元
线程3:获取当前值50->更新为100元。 V = 50,A = 50,B = 100
在现成执行成功后,线程2突然不阻塞了,但是由于阻塞之前获取的V=100,而此时A刚好也是100,所以把老王的余额更新为50。
老王回家之后跟媳妇已对账发现钱不对,挨了一顿毒打,这就是ABA问题引起的
解决办法:添加版本号
线程1:获取当前值100元->更新为50元 V = 100,A = 100,B = 50; verson = 01
线程2:获取当前值100元->更新为50元 V = 100,A = 100,B = 50; verson = 01
线程3:获取当前值50->更新为100元。 V = 50,A = 50,B = 100
线程1跟线程2初始版本号都为01,线程1提交成功,变量版本号变为02,
线程2阻塞,版本号为01
线程3提交成功,变量版本号变成03
线程2阻塞恢复,想要更新变量,变量版本号01!=03,更新失败
java中,AtomicStampedReference类实现了采用版本号作比较的CAS机制

















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









