




在现代电子商务环境中,高效的搜索功能是提升用户体验、促进销售的关键。然而,随着商品种类和数据量的快速增长,单纯依赖关系型数据库(如 MySQL)进行全文检索已难以满足性能需求。本文将详细介绍如何设计并实现一个基于 Elasticsearch + MySQL 的高效搜索解决方案,并通过双写同步机制确保数据的一致性和最终一致性。
一、背景与挑战
1. 传统方案的局限性
传统的电商搜索系统通常直接使用 MySQL 进行全文搜索,但这种方式存在以下问题:
- 查询效率低:MySQL 不擅长处理复杂的全文检索,尤其是在数据量大时,响应时间会显著增加。
- 扩展性差:随着商品数量的增长,单台 MySQL 实例难以承载大规模并发查询。
- 灵活性不足:MySQL 对于复杂的查询条件(如多字段组合查询、模糊匹配等)支持有限。
2. 引入 Elasticsearch 的优势
Elasticsearch 是一款分布式搜索引擎,具备以下特点:
- 全文检索能力强:支持高效的全文搜索和复杂查询。
- 高可扩展性:可以通过水平扩展轻松应对海量数据和高并发请求。
- 实时性好:支持近实时的数据更新和查询。
因此,结合 MySQL 存储完整业务数据 和 Elasticsearch 存储检索字段 成为一种理想的解决方案。
二、系统架构设计
1. 数据存储策略
- MySQL:作为主数据存储,存放完整的商品信息(包括详情、库存、价格等),用于事务管理和复杂关联查询。
- Elasticsearch:作为搜索引擎,存放商品的关键检索字段(如名称、分类、价格等),用于快速检索和过滤。
2. 同步机制
为了保证数据一致性和最终一致性,采用 双写同步机制,即:
- MySQL 本地事务:确保每次增删改操作在 MySQL 中成功执行。
- 消息队列:异步将商品变更操作同步到 Elasticsearch,避免影响主业务流程的性能。
3. 查询逻辑优化
- Elasticsearch BoolQuery:用于实现多条件复合查询(关键词、价格区间、分类筛选等),提升搜索效率。
- MySQL 关联查询:补充完整商品详情,确保返回结果的完整性。
三、详细流程解析
1. 商品数据写入流程
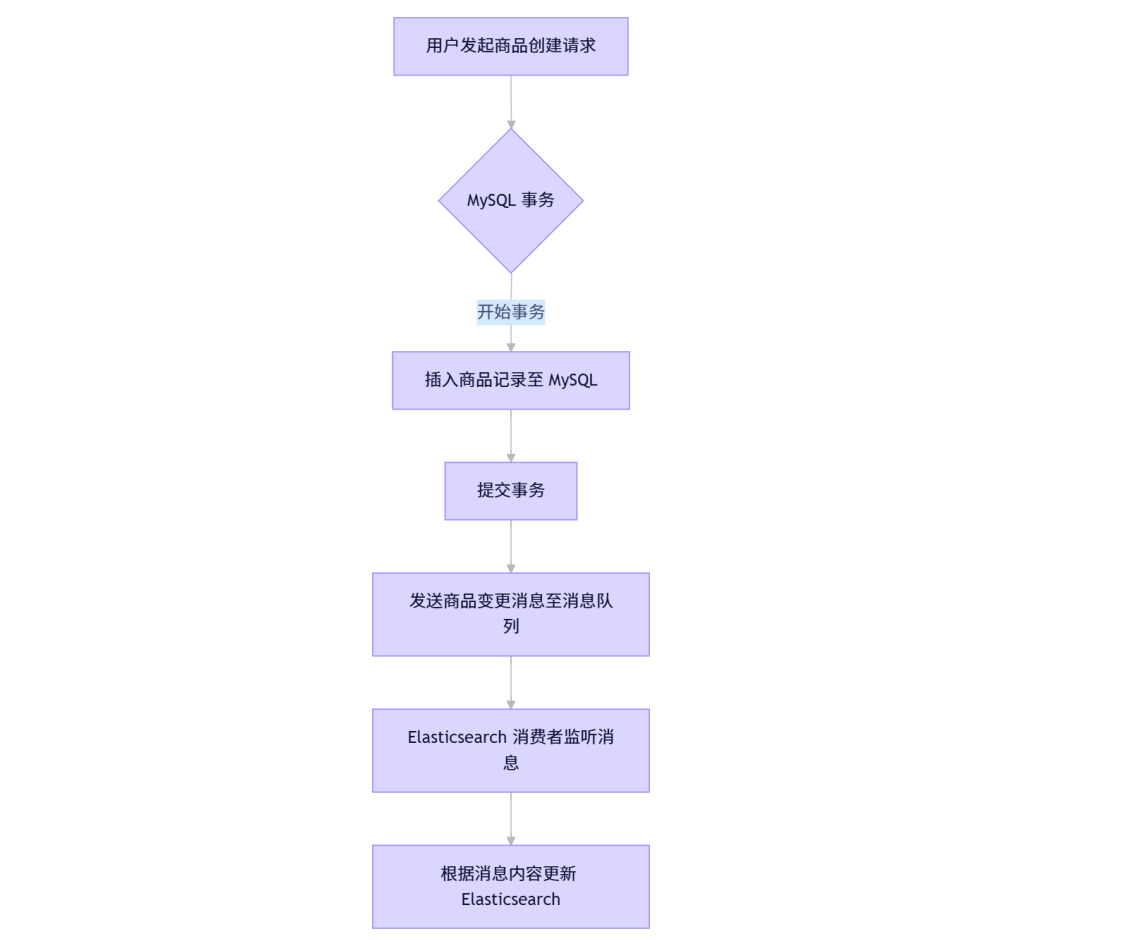
步骤详解:
- 用户发起商品创建请求:前端或后台管理系统发起商品创建请求。
- MySQL 事务:在 MySQL 中开启事务,确保商品信息的完整性和一致性。
- 插入商品记录至 MySQL。
- 提交事务,确保数据持久化。
- 发送商品变更消息:事务提交成功后,向消息队列发送一条包含商品 ID 和操作类型(新增、修改、删除)的消息。
- Elasticsearch 消费者监听消息:消费者监听消息队列中的商品变更消息,并根据消息内容更新 Elasticsearch 中的商品索引。
- 新增商品时,向 Elasticsearch 添加新文档。
- 修改商品时,更新现有文档。
- 删除商品时,从 Elasticsearch 中删除对应文档。
✅ 注意点:
- 确保消息队列的可靠性,避免消息丢失导致 ES 数据不一致。
- 在高并发场景下,可能需要引入幂等性设计,防止重复消费。
2. 商品搜索流程
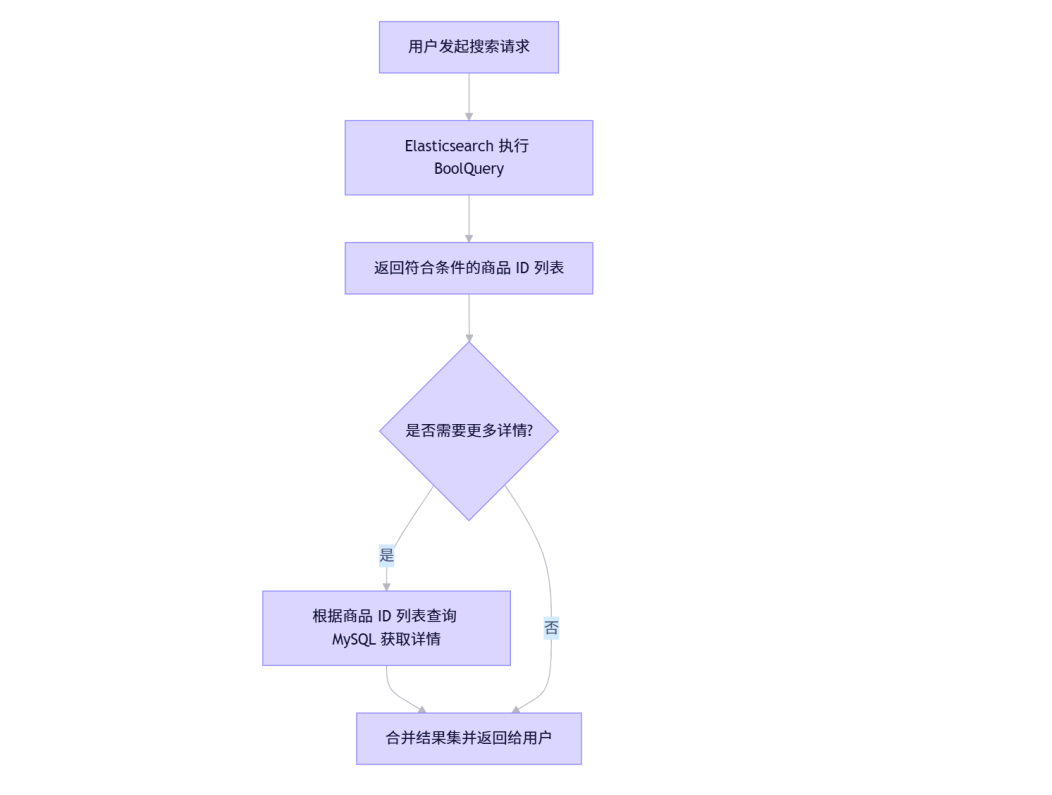
步骤详解:
- 用户发起搜索请求:用户输入关键词或其他查询条件,如价格区间、分类等。
- Elasticsearch 执行 BoolQuery:根据用户提供的查询条件,在 Elasticsearch 中执行 BoolQuery,快速定位符合条件的商品 ID 列表。
- 返回商品 ID 列表:Elasticsearch 返回符合条件的商品 ID 列表。
- 根据商品 ID 列表查询 MySQL:如果需要获取商品的详细信息(如描述、库存等),则根据商品 ID 列表查询 MySQL,补充完整商品详情。
- 合并结果集并返回给用户:将 Elasticsearch 返回的搜索结果与 MySQL 补充的详情合并,形成最终的结果集返回给用户。
✅ 优化建议:
- 预加载常用的商品详情字段到 Elasticsearch 中,减少对 MySQL 的依赖。
- 使用缓存机制(如 Redis)加速高频访问的商品详情查询。
四、技术亮点
1. 多条件复合查询
通过 Elasticsearch 的 BoolQuery 实现多条件复合查询,可以灵活地组合不同的查询条件(如关键词、价格区间、分类筛选等),提高搜索的准确性和灵活性。
{
"query": {
"bool": {
"must": [
{ "match": { "name": "手机" }},
{ "range": { "price": { "gte": 1000, "lte": 3000 }}},
{ "term": { "category": "电子产品" }}
]
}
}
}
2. 双写同步机制
- 事务提交后发送消息:确保只有在 MySQL 事务成功提交后才发送消息,避免 ES 中出现脏数据。
- 消息队列保障高可用性:利用消息队列的持久化和重试机制,确保即使在系统故障情况下也能保证数据的最终一致性。
3. 幂等性设计
为了防止重复消费导致的数据不一致,可以在消息中加入唯一标识符(如商品 ID 和操作类型),并在 ES 更新时检查该标识符,确保相同的操作不会被多次执行。
五、总结
通过结合 Elasticsearch + MySQL 的设计方案,我们不仅提升了搜索系统的响应速度,还确保了数据的一致性和最终一致性。这种架构模式特别适用于高并发、大数据量的电商应用场景,能够有效提升用户体验,助力业务增长。
📌 附录:Go 示例代码片段
1. 发送商品变更消息
func publishProductChange(productID string, operation string) error {
// 初始化消息队列客户端
mqClient := initializeMQ()
// 构建消息体
message := map[string]interface{}{
"product_id": productID,
"operation": operation,
}
// 发送消息
return mqClient.Publish("product_changes", message)
}
2. 监听消息并更新 Elasticsearch
func consumeProductChanges() {
mqClient := initializeMQ()
for {
msg, err := mqClient.Consume("product_changes")
if err != nil {
log.Printf("Failed to consume message: %v", err)
continue
}
// 解析消息
var payload map[string]interface{}
json.Unmarshal(msg.Body, &payload)
// 根据操作类型更新 Elasticsearch
switch payload["operation"].(string) {
case "create":
createOrUpdateESProduct(payload["product_id"].(string))
case "update":
createOrUpdateESProduct(payload["product_id"].(string))
case "delete":
deleteESProduct(payload["product_id"].(string))
}
}
}
希望这篇文章能帮助你深入理解基于 Elasticsearch + MySQL 的高效搜索系统的设计与实现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









