




在现代分布式微服务架构中,服务间的通信可靠性是保障系统稳定运行的关键。尽管 gRPC 凭借其高性能、强类型和跨语言特性成为服务间通信的首选协议,但在复杂的网络环境和动态的服务部署中,瞬时故障(Transient Failures) 依然不可避免。
为应对这些偶发性问题,引入 gRPC 重试机制 成为提升系统容错能力和最终一致性的核心手段。本文将深入探讨为何需要重试、如何配置以及其背后的合理性,并通过图示帮助理解其工作原理。
一、为什么需要 gRPC 重试机制?
在分布式系统中,一次成功的远程调用依赖于多个环节的正常运作:网络链路、服务实例健康状态、负载均衡、序列化/反序列化等。任何一个环节出现短暂异常都可能导致调用失败。
重试机制的核心价值在于:对可恢复的瞬时故障进行自动补偿,避免因短暂问题导致业务失败或数据不一致。
常见适用场景:
-
网络抖动
短时间内出现数据包丢失、延迟突增等情况,重试往往能在后续尝试中成功。 -
服务瞬时不可用
目标服务因自动扩缩容、健康检查失败重启、GC 停顿等原因短暂无法响应。 -
请求超时
单次请求因网络延迟或服务处理慢而超时,但服务本身仍在运行,重试可能更快完成。
举个例子: 在电商系统中,订单服务调用库存服务扣减库存。如果因为一次网络抖动导致调用失败,而没有重试机制,就可能出现“订单创建成功但库存未扣减”的严重一致性问题。通过合理配置重试,可以极大降低此类风险,减少人工干预成本。
二、gRPC 重试机制的实现原理(Mermaid 图解)
gRPC 的重试通常通过 拦截器(Interceptor) 实现。客户端在发起调用时,拦截器会捕获失败响应,并根据预设策略决定是否重新发起请求。
以下是典型的 gRPC 重试流程:
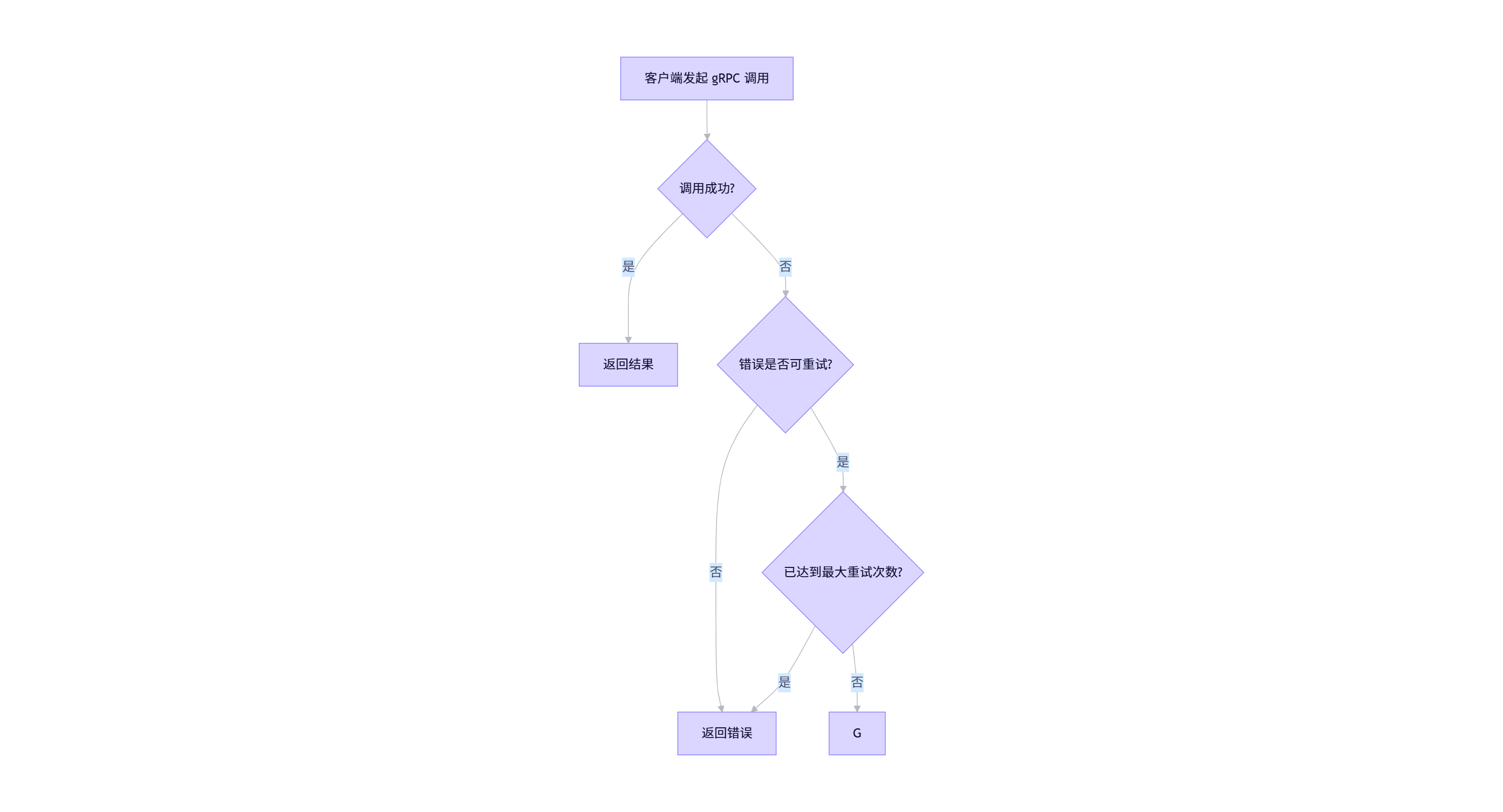
✅ 说明:
- 只有特定错误码(如
Unavailable,DeadlineExceeded)才会触发重试。- 每次重试都有独立的超时控制,避免阻塞整个请求链路。
- 重试次数有限,防止“重试风暴”耗尽资源。
三、代码中的 gRPC 重试配置逻辑
项目中基于 grpc-ecosystem/go-grpc-middleware/retry 包实现了重试功能,核心配置位于 grpc_interceptor/client/client.go 文件中。
// 定义重试参数
retryOpts := []grpc_retry.CallOption{
grpc_retry.WithMax(3), // 最大重试次数为 3 次(含首次请求共 4 次尝试)
grpc_retry.WithPerRetryTimeout(1 * time.Second), // 每次重试的超时时间为 1 秒
grpc_retry.WithCodes(
codes.Unknown,
codes.DeadlineExceeded,
codes.Unavailable,
), // 触发重试的错误码
}
// 将重试拦截器添加到 gRPC 客户端选项
opts = append(opts, grpc.WithUnaryInterceptor(grpc_retry.UnaryClientInterceptor(retryOpts...)))
关键配置项解析:
| 配置项 | 说明 |
|---|---|
WithMax(3) | 最多重试 3 次,加上首次请求,最多尝试 4 次 |
WithPerRetryTimeout(1s) | 每次调用(包括重试)最多等待 1 秒 |
WithCodes(...) | 仅当返回指定错误码时才触发重试 |
四、配置设计的合理性分析
✅ 1. 重试次数:3 次
选择 3 次是一个经验性的平衡点:
- 太少(如 1 次):难以覆盖多数瞬时故障,容错能力弱。
- 太多(如 5 次以上):增加服务负载,尤其在大规模并发下可能引发“重试风暴”,加剧系统压力。
结论: 3 次重试足以应对大多数网络波动和服务短暂不可用的情况,同时控制资源消耗。
✅ 2. 单次重试超时:1 秒
每次重试设置独立超时至关重要:
- 避免某次重试长时间挂起,导致整体响应延迟累积。
- 若服务能在 500ms 内恢复,重试可快速成功;若超过 1 秒仍未响应,则放弃本次尝试,及时释放资源。
对比: 如果使用总超时(如 4 秒),前几次重试耗时过长会压缩后续重试机会。
✅ 3. 触发重试的错误码
codes.Unknown,
codes.DeadlineExceeded,
codes.Unavailable
这些错误码代表的是可能恢复的临时性错误:
| 错误码 | 含义 | 是否应重试 |
|---|---|---|
Unknown | 未知错误(可能是临时故障) | ✅ 是 |
DeadlineExceeded | 请求超时 | ✅ 是 |
Unavailable | 服务不可用(如正在重启) | ✅ 是 |
PermissionDenied | 权限不足 | ❌ 否(永久性错误) |
NotFound | 资源不存在 | ❌ 否 |
⚠️ 重要原则: 永远不要对幂等性不强的操作(如创建订单)盲目重试,除非确保后端服务具备幂等处理能力。
五、重试机制在系统中的作用与边界
它解决了什么?
- 提升服务调用的可靠性和可用性
- 减少因瞬时故障导致的业务失败
- 降低运维人员处理偶发故障的人工成本
它不能解决什么?
- 持久性故障:如服务彻底宕机、数据库崩溃等,重试无意义。
- 数据一致性问题:重试本身不保证事务一致性,需结合幂等设计、分布式事务或最终一致性方案。
- 性能瓶颈:不当的重试策略反而会加重系统负担。
六、总结:构建健壮的微服务通信链路
gRPC 重试机制是构建高可用微服务不可或缺的一环。它通过拦截器方式优雅地实现了对瞬时故障的自动恢复,在可靠性与资源消耗之间取得了良好平衡。
在实际项目中,合理的重试配置应遵循以下原则:
- 明确目标:只为可恢复的临时错误重试。
- 控制频率:限制最大重试次数,避免雪崩。
- 设置超时:每次重试独立超时,防止阻塞。
- 结合幂等:确保重试不会引发副作用。
- 监控告警:记录重试日志,便于排查问题。
最终建议: 在订单、支付、库存等关键链路中启用重试机制,并结合熔断、限流等策略,打造一个真正 resilient(弹性)的分布式系统。

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









