



 本文介绍了如何在MySQL中通过创建唯一索引和使用ON DUPLICATE KEY UPDATE语句实现批量插入数据时,遇到重复记录时进行更新,而非新增。示例中展示了创建学习成绩表、插入数据、添加唯一索引以及使用ON DUPLICATE KEY UPDATE更新的完整过程,适用于数据库管理和数据操作场景。
本文介绍了如何在MySQL中通过创建唯一索引和使用ON DUPLICATE KEY UPDATE语句实现批量插入数据时,遇到重复记录时进行更新,而非新增。示例中展示了创建学习成绩表、插入数据、添加唯一索引以及使用ON DUPLICATE KEY UPDATE更新的完整过程,适用于数据库管理和数据操作场景。
项目场景:在批量插入的同时,对于已存在的数据,做更新操作,不存在则新增;
1.新增一张学习成绩表;
CREATE TABLE `study_grades` (
`id` int(20) NOT NULL AUTO_INCREMENT,
`user_id` int(20) NOT NULL,
`subject_id` int(20) NOT NULL,
`grades` decimal(5,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
批量插入语句:
INSERT INTO study_grades (user_id, subject_id, grades)
VALUES
( 1001, 101, 89 ),
( 1002, 102, 88 ),
( 1003, 103, 87 );
执行结果为:
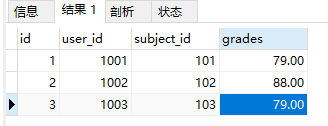
2.现在对这张表插入同样的数据,但是要求user_id 和 subject_id同时保持唯一,也就是用户id和科目id相同的只能存在一条记录,重复时更新,不重复时新增;
可以使用关键字 UNIQUE 创建唯一性索引的方法实现:
alter table study_grades add UNIQUE user_subject(user_id,subject_id);
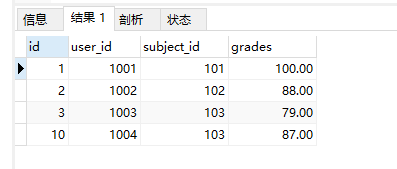
3.然后使用 ON DUPLICATE KEY UPDATE 来实现插入和更新;
说明:ON DUPLICATE KEY UPDATE的用法是基于索引冲突,当使用唯一索引或主键索引时,存在索引字段相同时更新,否则插入;
用法:
INSERT INTO study_grades
(user_id, subject_id, grades)
VALUES
( 1001, 101, 89 ),
( 1001, 101, 100 ),
( 1004, 103, 87 )
ON DUPLICATE KEY UPDATE grades = values(grades);
结果:
mybatis:
<insert id="insertGradesList">
INSERT INTO study_grades (user_id, subject_id, grades)
VALUES
<foreach collection ="list" item="item" separator =",">
(#{item.cuserId}, #{item.subjectId},#{item.grades})
</foreach>
ON DUPLICATE KEY UPDATE grades = values(grades)
</insert>

















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









