




 本文介绍了Self-Supervised Learning的原理和应用,包括Denoising AutoEncoder、Language Model如GPT和BERT。同时讲解了Anomaly Detection的概念,强调其在欺诈检测、网络入侵和癌症检测等领域的应用。通过最大似然度法求解异常检测中的概率密度函数,并探讨了使用Auto-encoder进行异常侦测的可能性。
本文介绍了Self-Supervised Learning的原理和应用,包括Denoising AutoEncoder、Language Model如GPT和BERT。同时讲解了Anomaly Detection的概念,强调其在欺诈检测、网络入侵和癌症检测等领域的应用。通过最大似然度法求解异常检测中的概率密度函数,并探讨了使用Auto-encoder进行异常侦测的可能性。
- Self-Supervised Learning
- Anomaly Detection(异常检测)
- Maximum LikeLihood(最大似然度)
二十六、Self-Supervised Learning
Self-Supervised Learning其实是一种unsupervised learning,但是它更注重data本身的information。一般来说,训练的方法是舍弃一部分data,然后保留一部分data,再用保留的这一部分data去预测舍弃的data。
最终任务是:在学习下个任务之前找到好的represent。
举个例子说明Self-Supervised Learning怎么学习:(1)利用过去的时间预测未来发生的事;(2)用比较少部分的过去预测未来;(3)用现在去预测过去;(4)用bottom的部分去预测up的部分。
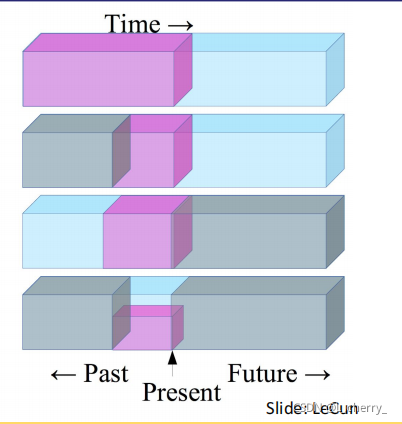
目前Self-Supervised Learning的方法大致可以分成:
(1)Reconstruct 一些被破坏的data;
(2)Visual common sense tasks(视觉常识任务),比如拼图或者旋转;
(3)contrastive learning(对比学习)。

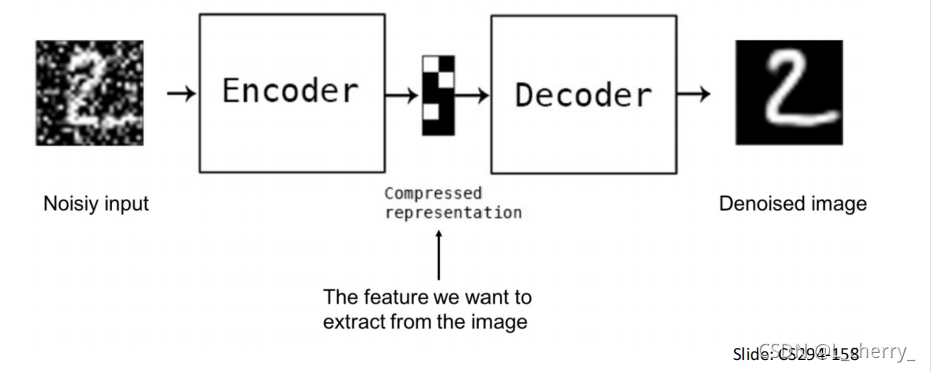
(一)Reconstruct from a corrupted data
本质上是一个Denoising AutoEncoder,不同的是在做Self-Supervised Learning时不仅看重encoder,也看重decoder,看重的是整个model本身,会拿整个model去下游任务做fitting。
Language Model:估计一串字出现的probability distribution到底是多少。常用的估计方法有两种:(1)n-gram model
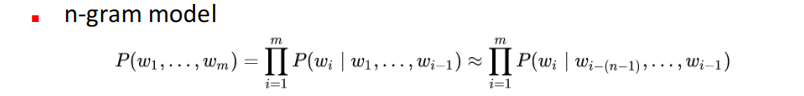
(2)neural network:
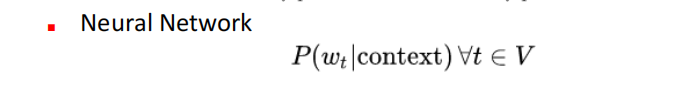
一些Language Model:
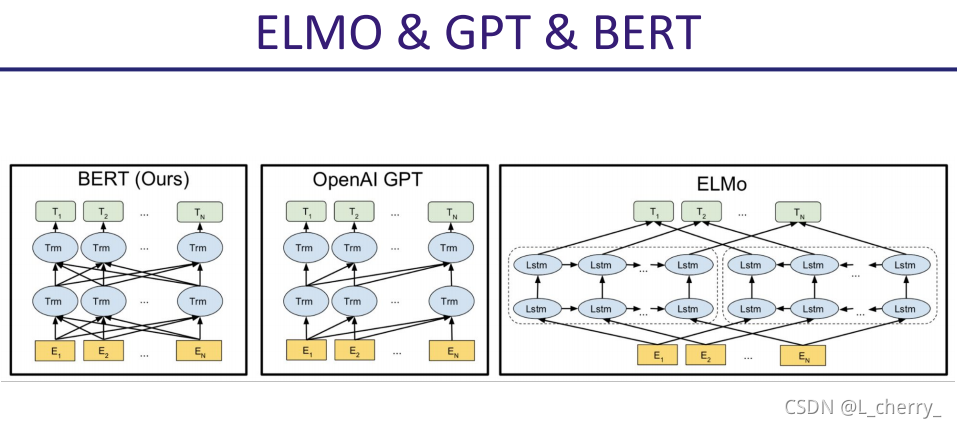
GPT是一个比较完整的Self-Supervised Learning的例子。

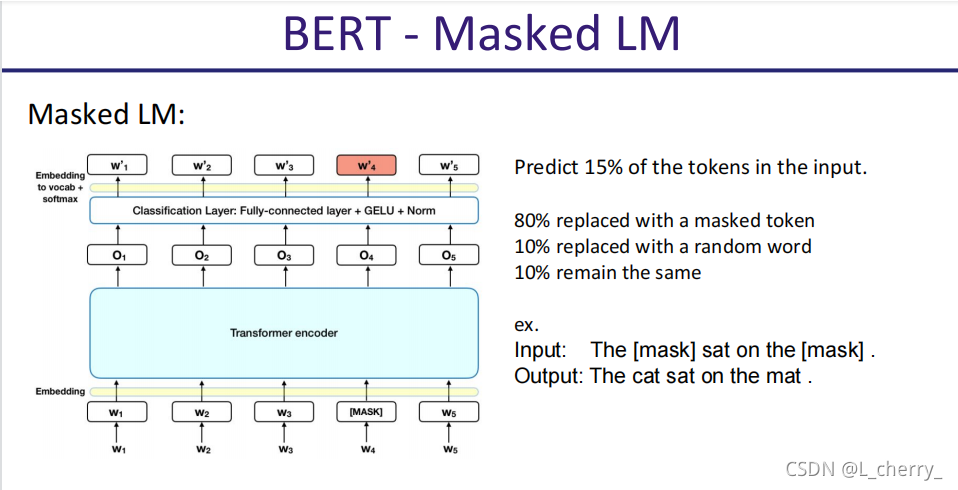
BERT和最主要就是使用了Masked LM:
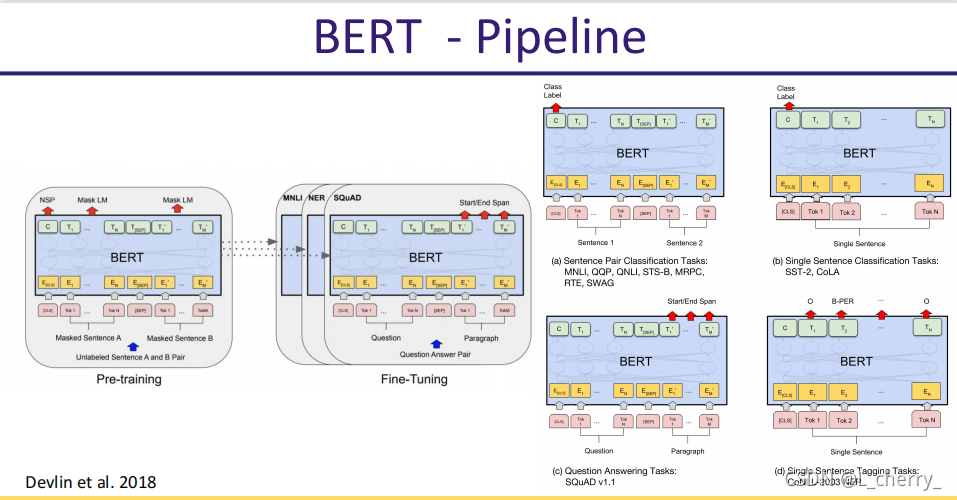
BERT下游任务:
ELMO、GPT叫做Autoregressive Language Model(ARLM);BERT叫做Autoencoding Language Model(AELM a.k.a MaskedML);

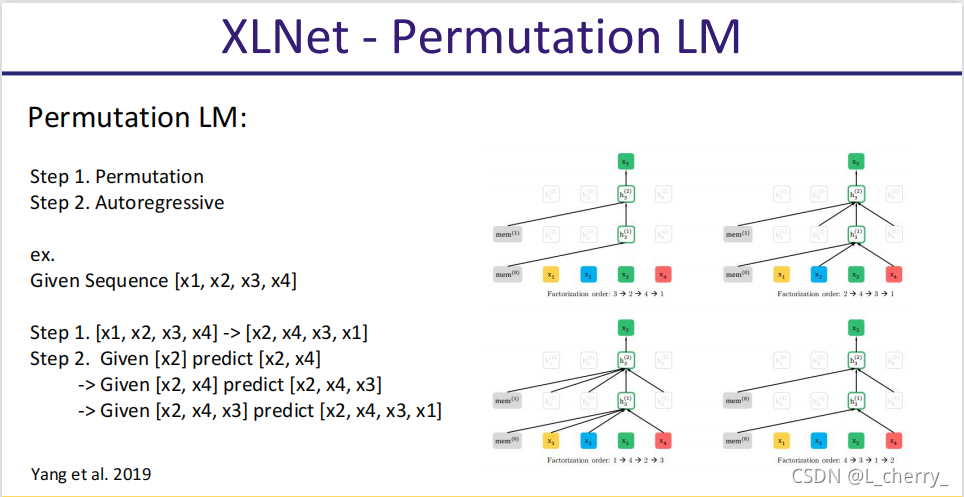
XLNet:
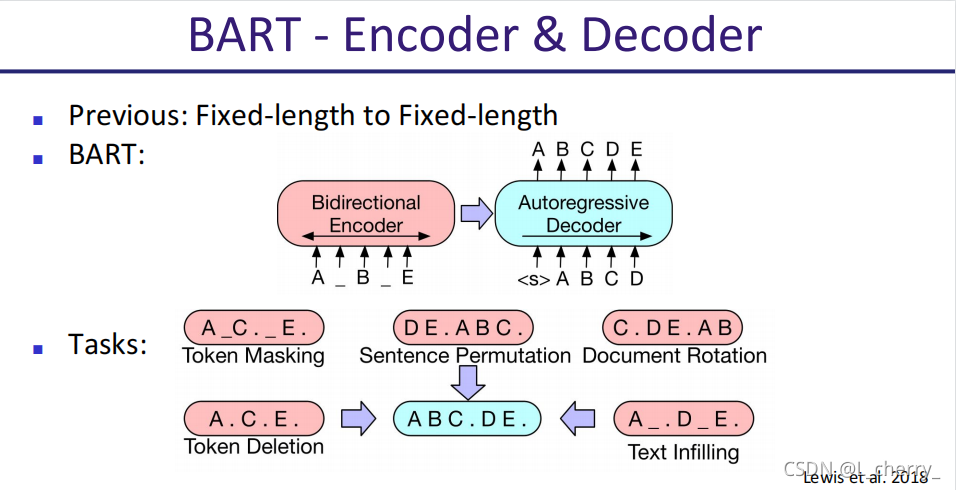
BERT - Enocder & Decoder:
ELECTRA - Discriminator:

Self-Supervised Learning在图片中的用法:
(1)在一张图片上随机选一处挖空,然后想办法预测挖空的这部分data。
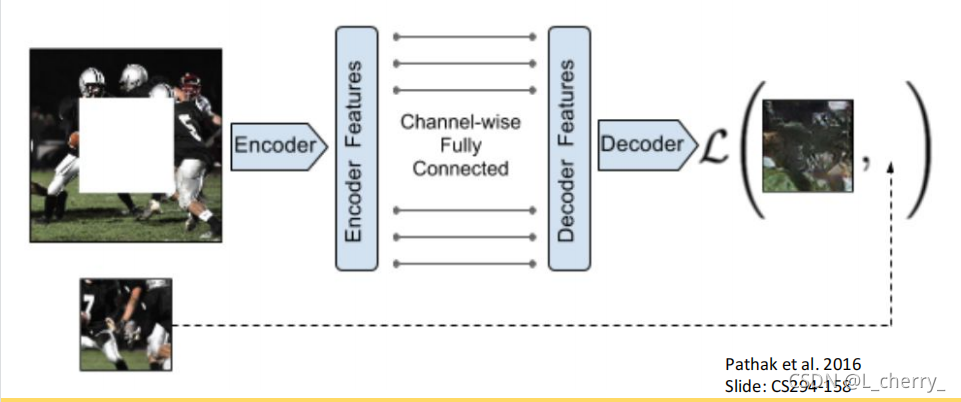
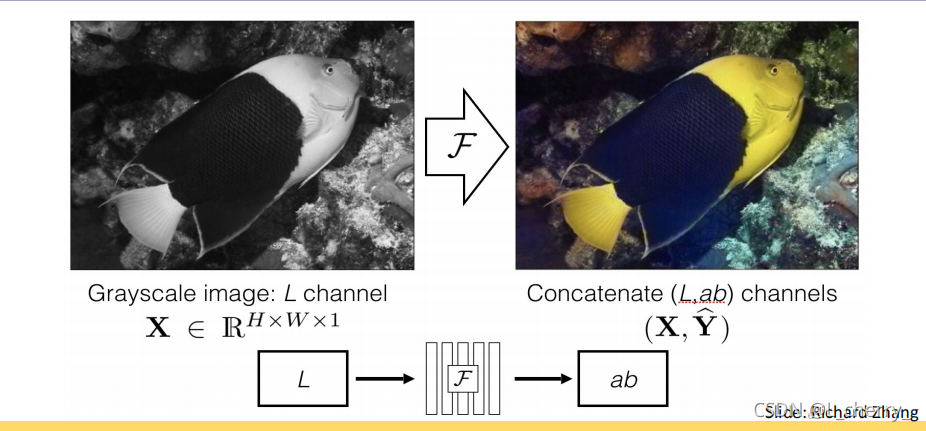
(2)把灰阶的图片复原成彩色的:
(3)复原拼图:

(4)旋转的图片判断它旋转了几度:


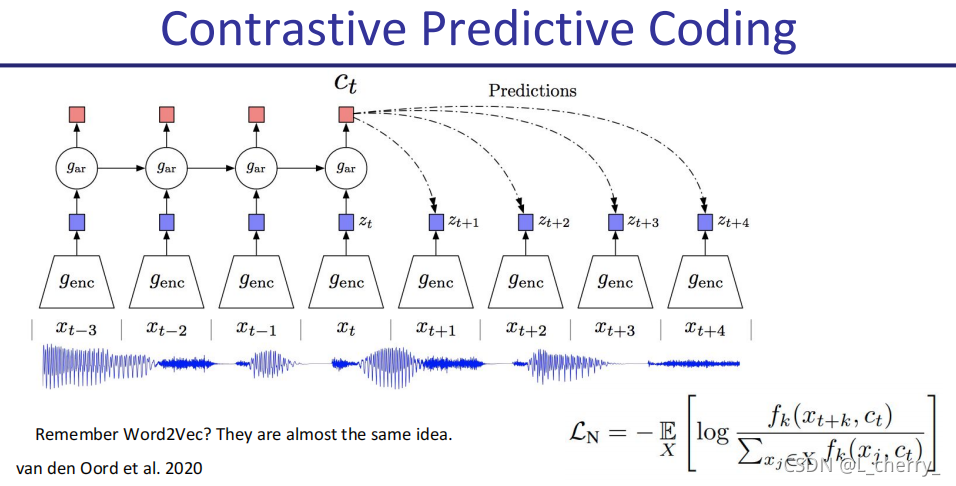
(5)Constrastive Predictive Coding
(6)SimCLR
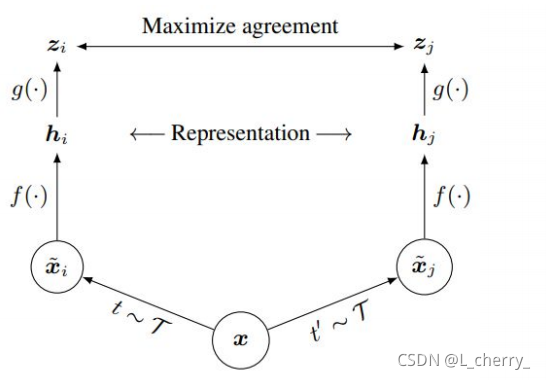
二十七、Anomaly Detection(异常检测)
就是让机器知道我不知道的事情。
problem formulation:有一堆训练数据{
x1,x2,...,xN}\begin{Bmatrix} x^1,x^2,...,x^N \end{Bmatrix}{
x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









