




- RNN
- LSTM
- Attention-based Model
十一、Recurrent Neural Network(RNN)(循环神经网络)
1、Slot Filling
智慧客服,订票系统,需要Slot Filling(槽位填充)这项技术,假设现在有人说“我要买11月2日去上海的票”,比如在订票系统的Slot分为Destination和time of arrival,系统需要自动辨别每一个词汇属于哪个Slot。
如何解决slot filling呢?
可以使用Feedforward network:input是一个词汇,变成一个vector,丢到这个network中去,output应该是一个Probability distribution(代表input中的词汇属于每一个slot的几率)。
那么怎么把词汇变成一个vector呢?
使用1-of-N encoding(方法很多,这是其中之一):

或者是Beyond 1-of-N encoding的方法:方法(1)需要在1-of-N encoding*中多加一个dimension,叫做“other”,不是词典里有的词汇就归类到“other”中去;方法(2)用某一个词汇的字母来表示它的vector,比如apple这个词汇,里面有“app”、“ppl”、“ple”,那么对应到这三种表达的dimension就是1,其它都为0:
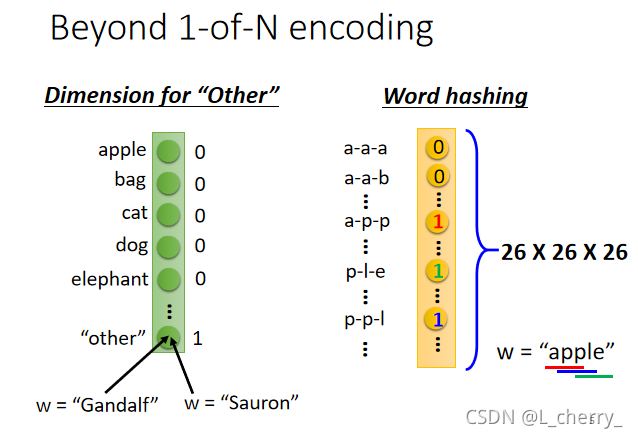
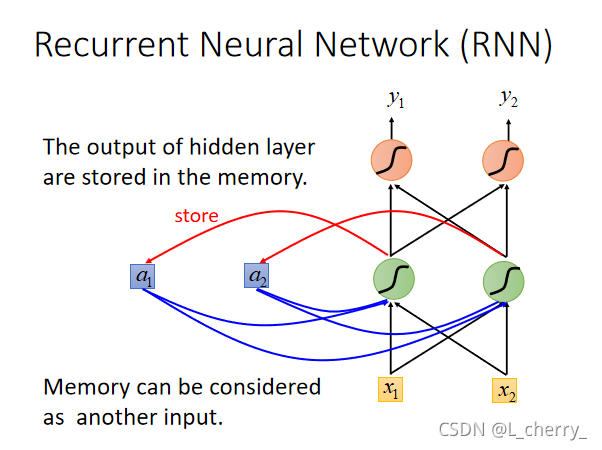
假如现在,一个人说“arrive Shanghai on November 2nd”,可以确定,“arrive”、“on"都为"other”,“Shanghai"为destination,“November”、“2nd"为"time”;但是另一个说"leave Shanghai on November 2nd”,这个时候的"Shanghai"就为"place of departure"(出发地点),但是对network来说,input是一样的,output就是一样的,这个时候就希望我们的network是有记忆的,这个有记忆的network就叫做Recurrent Neural Network(RNN):
每一次hidden layer里面的neural产生output的时候,output就会被存到memory里面去;下一次,当有input时,hidden layer 的neural不仅会考虑输入的input,还会考虑存储在memory里的。
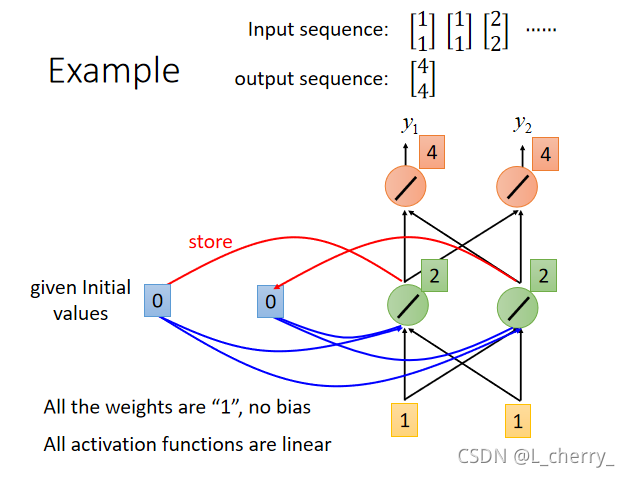
举例:假设现有network,所有的neural的weight都是1,并且没有bias,所有的激活函数都是linear,现在的input sequence(输入序列):[11][11][22]\begin{bmatrix} 1\\ 1 \end{bmatrix}\begin{bmatrix} 1\\ 1 \end{bmatrix}\begin{bmatrix} 2\\ 2 \end{bmatrix}[11][11][22]…要把它们输入这个network,在这之前必须给memory一个起始值,假设这里在没存任何东西设置memory得初始值为0,然后输入第一个序列,得到得output为[44]\begin{bmatrix} 4\\ 4 \end{bmatrix}[44]$ (1x1+1x1=4),并且把绿色的neural得到的output(2 2)存入memory:
现在输入第二个input序列,经过一个neural得到的output为6(1x1+1x1+2+2=6,这里的2和2也变成input),最后再经过红色的neural得到的output为12(6x1+6x1=12):
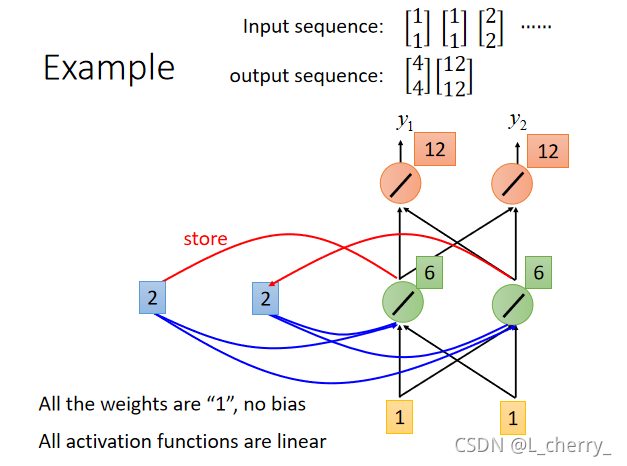
这里说明,即使给RNN一样的input,得到的output也是可能不一样的。
接下来继续输入input的第三个序列:
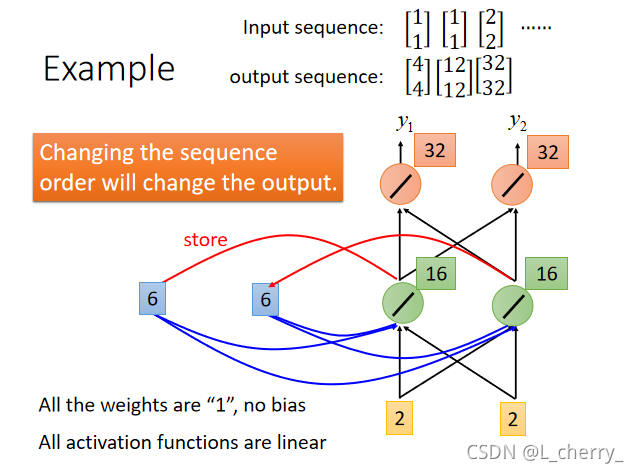
发现:RNN考虑input sequence的时候并不是independent的,如果改变input序列的顺序,output可能是会完全不一样的。
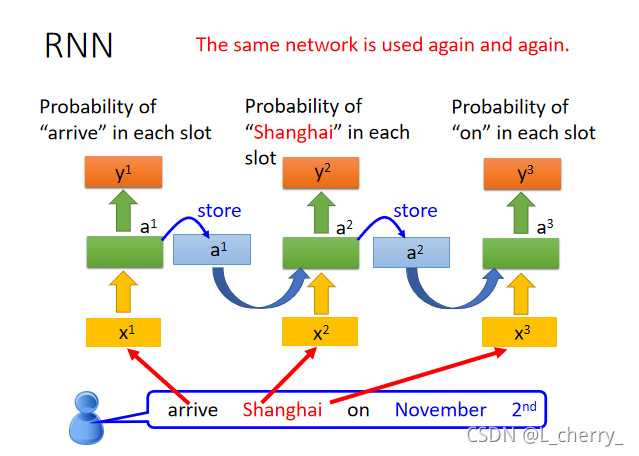
现在用RNN处理slot filling,举例:“arrive Shanghai on November 2nd”,然后把"arrive"变成vector丢到neural network中,neural network的hidden layer的output写成a1a^1a1,根据这个a1a^1a1得到y1y^1y1,这个y1y^1y1就是"arrive"属于每一个slot的几率;接下来a1a^1a1会被存到memory中去,input变为"Shanghai",此时的neural network的hidden layer会同时考虑memory和input,得到a2a^2a2,以此类推…(这里的neural network是同一个,在不同的时间点使用了三次):
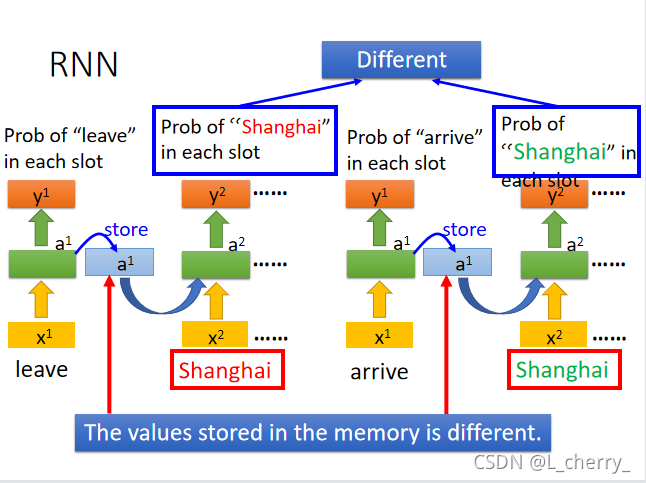
有了memory之后,输入同一个词汇希望得到不同的output的问题可以被解决,现在同样输入"Shanghai",一个前面接的"leave",另一个前面接的"arrive",因为它们两个的vector不同,就会导致存储hidden layer的memory值不同,所以最后的output值不同。
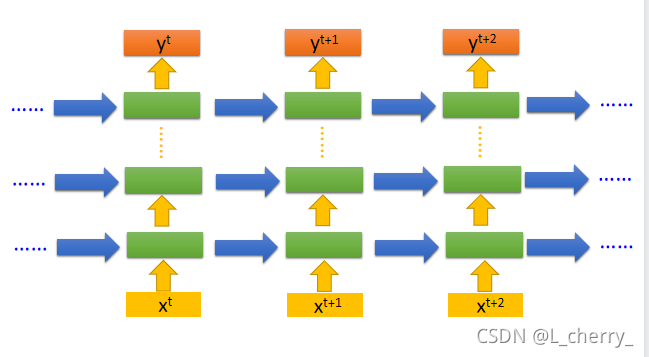
以上的RNN只有一层hidden layer,但它当然也可以是deep的:
这种把hidden layer的值存起来,再读出来的network叫做Elman Network(埃尔曼网络);有另一种network存的是整个network的output的值,在下一个时间点再读进来,这个network叫做Jordan Network(因为output是有target的,所以有更好的performance)。
RNN也可以是双向的,句子中的每个词汇可以从句首读到句尾,但也可以反过来,从句尾读到句首,也就是说,可以同时train一个正向的RNN,又同时train一个逆向的RNN,把同一个词汇的hidden layer拿出来都接给一个output layer:
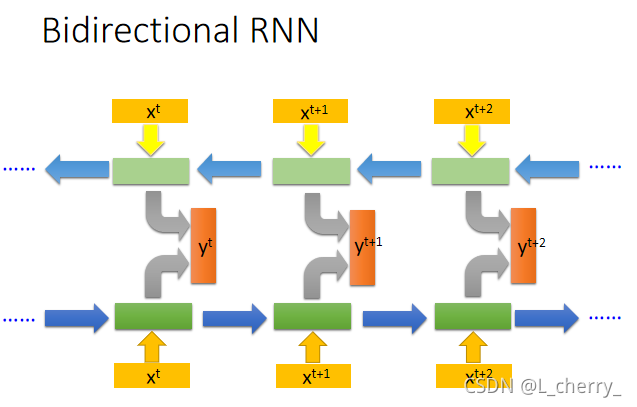
这样做的好处是,产生output时这个neural network看的范围比较广。
2、LSTM
现在比较常用的memory称之为Long Short-term Memory(LSTM):
有三个gate:(1)当neural network的其它部分想要被写到memory cell里面的时候,必须先通过一个闸门–Input gate,这个Input gate被打开的时候才能把值写到Memory Cell中,如果 Input gate关闭,其它neural 就不能把值写进去,这个Input gate是打开还是关闭,是neural network自己学的;(2)输出的地方也有一个Output Gate,它决定外界其它部分可不可以从Memory把值拿出来,同样,Output Gate什么时候打开或关闭,也是neural network自己学到的;(3)第三个gate叫做Forget Gate,它决定Memory Cell什么时候把存在里面的东西忘掉,同样也是neural network自学的。
整个LSTM可以看成有4个input,1个output,4个input为(1)想要被存到Memory Cell里面的值(不一定存的进去);(2)操控input gate的信号;(3)操控output gate的信号;(4)操控forget gate的信号。
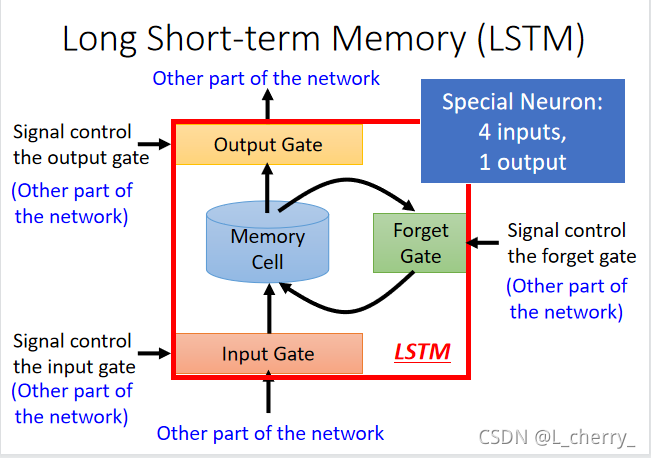
如下图是一个Memory Cell,假设想存到Memory Cell里的input为zzz,操控Input Gate的signal叫做ziz_izi(scalar,数值),操控Forget Gate的signal叫做zfz_fzf,操控Output Gate的signal叫做zoz_ozo,最后得到的output叫做aaa。假设现在Memory Cell在输入这些之前里面已经存了值C,那么得到的output(如下图):
(1)把zzz通过Activation function得到g(z)g(z)g(z),把ziz_izi通过另外的Activation function得到f(zi)f(z_i)f(zi)(三个gate通过的Activation function通常会选择sigmoid function,它的值介于0~1之间,如果Activation function的output是1,说明这个gate是被打开的状态,如果是0,说明是关闭的状态)
(2)接下来把得到的g(z)g(z)g(z)和f(zi)f(z_i)f(zi)相乘,得到g(z)f(zi)g(z)f(z_i)g(z)f(zi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3791
3791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









