







 本文介绍使用NodeJS、request、fs及cheerio模块进行网页数据爬取的方法。通过实例展示如何抓取商品信息,包括图片下载和数据保存至本地json文件。
本文介绍使用NodeJS、request、fs及cheerio模块进行网页数据爬取的方法。通过实例展示如何抓取商品信息,包括图片下载和数据保存至本地json文件。
NodeJS简单爬虫数据
做假数据是不是很麻烦,直接自己爬就好了。
//test.js
// 要先npm安装这些第三方模块
const request = require('request');
const fs = require('fs');
const cheerio = require('cheerio');
//爬取 http://b.boshiying.com/mobile/ 的数据
request('http://b.boshiying.com/mobile/', (error, response, body) => {
let $ = cheerio.load(body);
let goodsList = [];
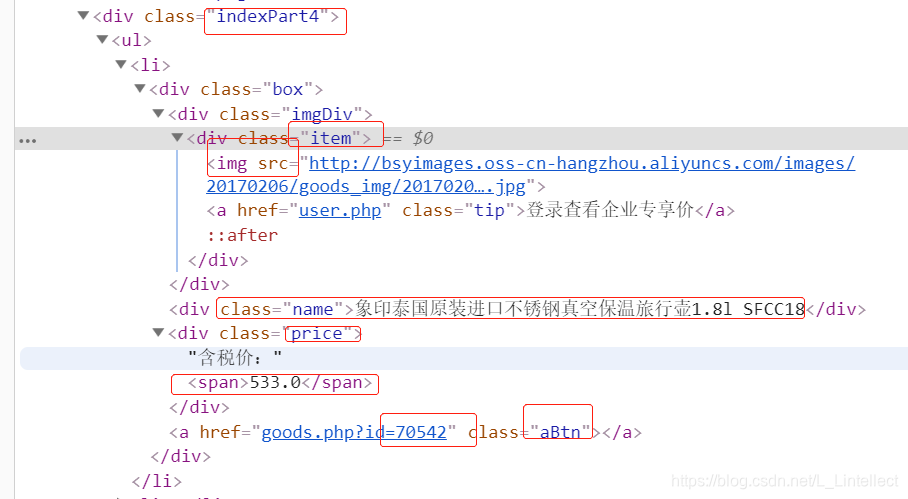
//以下需要分析 html结构,定位到对象的数据即可
$('.indexPart4 ul li').each((idx, li) => {
let $li = $(li);
//图片路径
let imgURL = $li.find('.item img').attr('src');
// console.log(imgURL)
//商品描述
let name = $li.find('.name').text();
// console.log(name)
//价格
let price = $li.find(".price span").text()
// console.log(price)
//商品id
let gid = $li.find(".aBtn").prop('href').split("=")[1];
// console.log(gid)
let goods = {
gid: gid,
imgURL: imgURL,
name: name,
price: price
}
//下载图片到本地,imgs 文件夹不会自动穿件
request(imgURL).pipe(fs.createWriteStream(`./imgs/${gid}.png`))
//数据保存起来 ,json格式
goodsList.push(goods);
//fs写入只识别二进制或者字符串,data.json 需要手动创建
let str = JSON.stringify(goodsList);
//将数据写入外部文件,覆盖形式,
fs.writeFile('./data.json', str, (error) => {
if (error)
console.log("写入失败", error)
})
})
})
//终端打开,再 node test 即可
分析该网站的html结构;

















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









