







在学习网页信息爬取的时候发现按照教学少了点什么
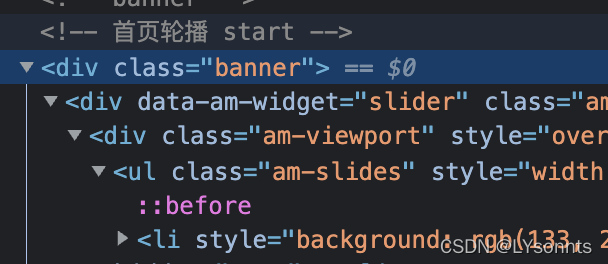
图片中自己的注释已经说明了,原网页中标签<div>需要放到BeautifulSoup.find方法中的最前面,bs4的新要求(或许看老的教材也会遇到的问题)
Error Type:AttributeError: 'NoneType' object has no attribute 'text'
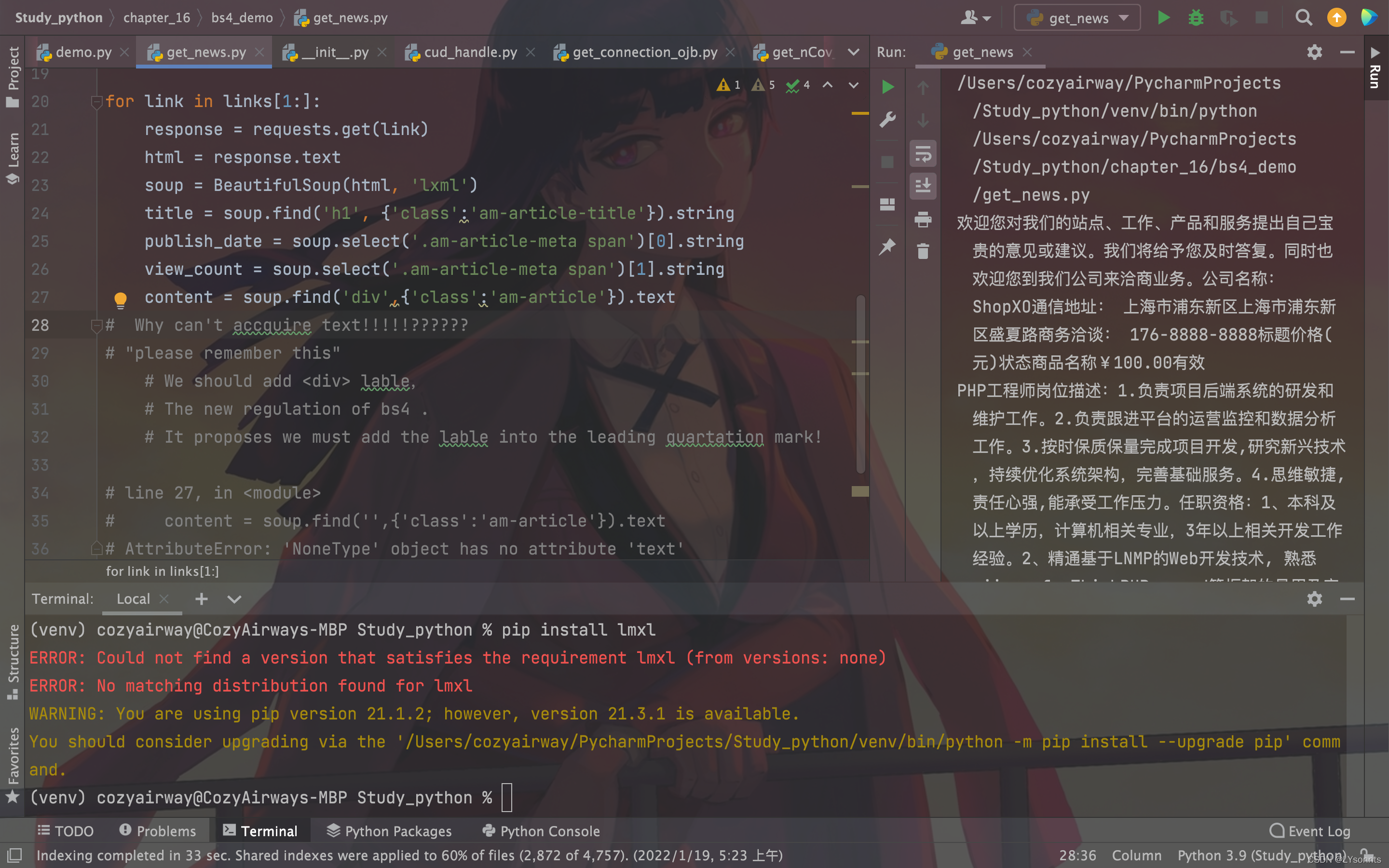
如果漏了的话报错页面是这样
 b
b
爬取信息页面是自己用mamp pro部署的 shopxo 网页
需要的lable标签取决于自己需要查找的elements接受的最上面的标签
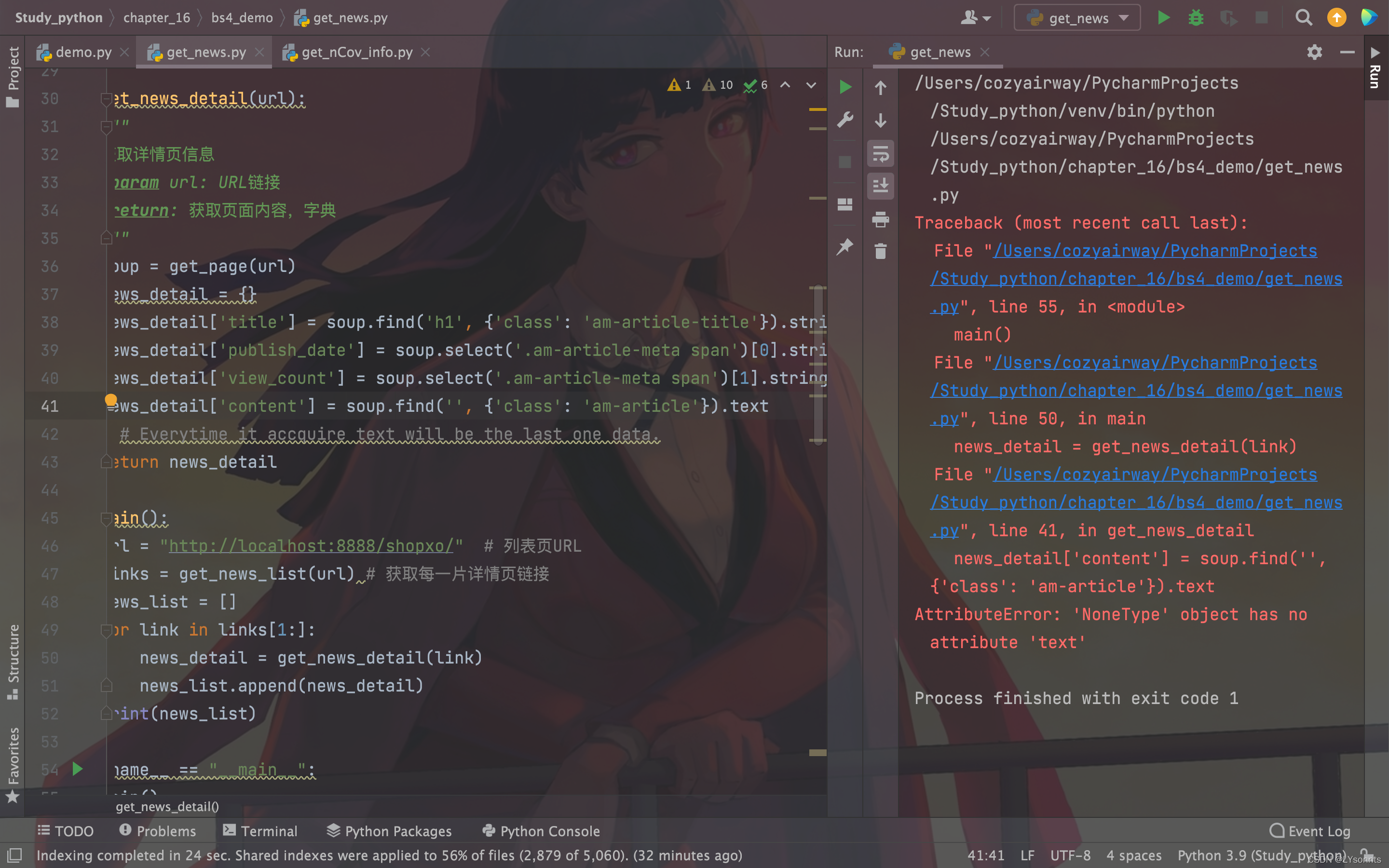
Traceback (most recent call last):
File "/Users/cozyairway/PycharmProjects/Study_python/chapter_16/bs4_demo/get_news.py", line 55, in <module>
main()
File "/Users/cozyairway/PycharmProjects/Study_python/chapter_16/bs4_demo/get_news.py", line 50, in main
news_detail = get_news_detail(link)
File "/Users/cozyairway/PycharmProjects/Study_python/chapter_16/bs4_demo/get_news.py", line 41, in get_news_detail
news_detail['content'] = soup.find('', {'class': 'am-article'}).text
AttributeError: 'NoneType' object has no attribute 'text'


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









