






1介绍一下信号和槽
信号和槽是qt中用于代码解耦的一种回调机制,用于对象之间的事件触发,默认支持信息的跨线程传递
实现依托于原对象系统和事件队列(loop)
2说一下你经常使用的设计模式
观察者模式:回调函数,用于代码之间的解耦,可以把逻辑细分成不同的逻辑块
工厂模式:把构建对象的过程通过一个类实现,对代码解耦,
单例模式:保证一个类只存在对象
策略模式:根据当前的需要,动态选择不同的的函数实现
3说一下什么是mvc架构
把用户界面和用户数据的处理逻辑分离,视图传递用户操作给控制层,控制层使用模型层获取结果,更新视图。
4什么是自定义控件
继承原先存在的控件类,并对这个类进行重写,从而实现不同的控件效果
5 进程和线程之间的区别
1. 内存空间:• 进程拥有自己独立的内存空间,包括代码段、数据段、堆和栈等。进程之间的内存是隔离的。• 线程共享所属进程的内存空间,线程之间的通信可以通过共享内存快速实现。
2. 安全性:• 进程之间的隔离性较高,一个进程的崩溃通常不会影响其他进程。但如果父进程终止,可能会导致子进程被清理。• 线程之间共享内存,线程的崩溃可能会导致整个进程崩溃。线程之间的通信和同步需要谨慎处理,否则可能会引发数据竞争或死锁。
3. CPU资源消耗:• 进程的创建和切换开销较大,因为操作系统需要分配和回收资源。• 线程的创建和切换开销较小,因为线程共享进程的资源。
4. 应用场景:• 进程适用于独立任务,尤其是需要隔离的场景,如不同的应用程序。• 线程适用于CPU密集型任务和I/O密集型任务,可以充分利用多核CPU的优势,提高程序的并发性能。
5. 通信方式:• 进程间通信需要通过管道、消息队列、共享内存或套接字等机制。• 线程间通信可以通过共享内存直接进行,也可以使用同步机制来协调。
6. 并发能力:• 进程的并发能力受限于系统的资源分配能力。• 线程的并发能力更强,但过多的线程可能会导致上下文切换频繁,降低性能。
6:如何优化多线程程序的性能?
• 合理控制线程数量:根据系统资源和任务类型,合理控制线程的数量。
• 减少锁的使用:尽量减少锁的使用范围,避免不必要的锁竞争。
• 使用线程池:通过线程池复用线程,减少线程的创建和销毁开销。
• 优化算法:优化算法逻辑,减少线程间的依赖和同步操作。
7进程和线程之间的通信方式
线程同步方式:共享变量,锁,条件变量,原子操作
进程:套接字,管道,信号量,信号,共享内存,消息队列
8.tcp和udp的区别
速度方面:tcp速度比udp慢
准确性方面:tcp比udp可靠
功能:tcp提供流量控制和拥塞控制
应用场景:tcp适合数据传输量少,udp适合数据实时性要求高的场景,比如音视频方面
9介绍一下http协议
它是一种基于文本的应用层协议。HTTP协议由请求和响应两部分组成。请求由请求行、请求头和请求体组成,常见的请求方法有 GET 、 POST 等。响应由状态行、响应头和响应体组成,状态码如 200 OK 、 404 Not Found 等。HTTP的工作过程包括建立连接、发送请求、处理请求、返回响应和关闭连接。HTTP/1.1支持持久连接和管道化,而HTTP/2引入了二进制分帧、多路复用和服务器推送等特性
应用场景
Web浏览:浏览器通过HTTP协议请求服务器上的网页资源。
• API通信:客户端通过HTTP请求与服务器上的API进行交互。
• 文件传输:通过HTTP协议下载或上传文件。
• Web应用:支持各种Web应用的交互,如表单提交、用户认证等。
10socket的网络编程
TCP套接字编程
1. 创建套接字 2. 绑定地址信息3. 监听连接请求 4. 接受客户端连接 5. 数据传输和 write() 或 send() 和 recv() 6. 关闭套接字
客户端:1. 创建套接字2. 连接到服务器3. 数据传输send() 和 recv() 4. 关闭套接字
UDP套接字编程
1. 创建套接字2. 绑定地址信息 3. 数据传输recvfrom() 和 sendto() 4. 关闭套接字:
客户端:
1. 创建套接字 2. 数据传输sendto() 和 recvfrom() 3. 关闭套接字
11介绍一下epoll和iocp网络模型
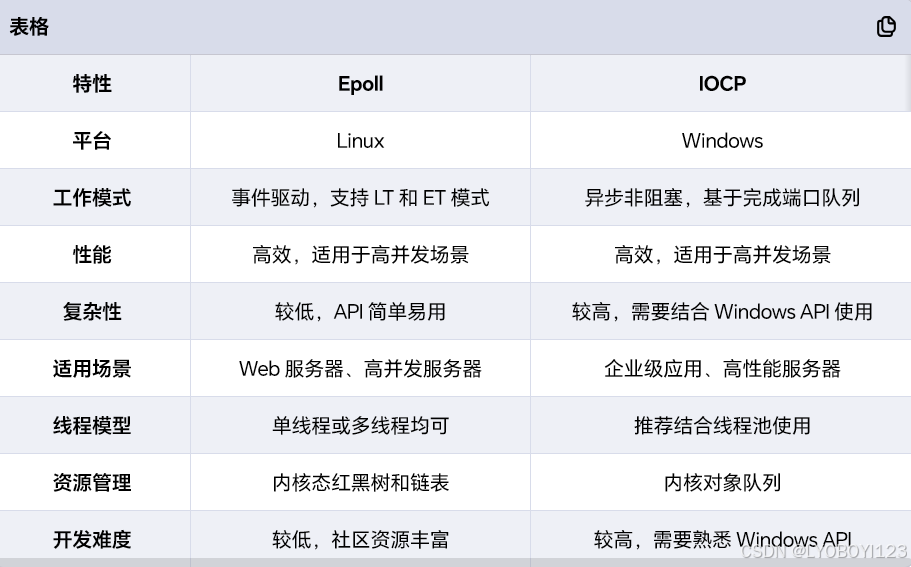
12介绍一下Reactor 和 Proactor
Reactor 和 Proactor 是两种常见的网络编程模型,都基于事件驱动机制,但实现方式和适用场景有所不同。Reactor 模型 是一种同步 I/O 模型,基于事件循环和事件分发机制。它通过 I/O 多路复用(如 epoll 、 poll )监控文件描述符的状态,当有事件发生时,事件循环会将事件分发给对应的处理器。Reactor 模型适用于高并发场景,如 Web 服务器和聊天服务器。它的实现较为简单,社区资源丰富。Proactor 模型 是一种异步 I/O 模型,基于完成事件驱动。它通过异步 I/O 操作(如 readv 、 writev )和完成端口(如 Windows 的 IOCP)管理 I/O 请求。当异步操作完成后,完成事件会被放入完成端口,事件循环会获取这些事件并分发给处理器。Proactor 模型适用于高性能服务器和企业级应用,性能更高,但实现复杂,需要结合操作系统提供的异步 I/O 接口。总结来说,Reactor 模型更适合简单的高并发场景,而 Proactor 模型更适合对性能要求极高的场景。选择哪种模型取决于具体的应用需求和开发环境。
13介绍一下boost库中的asio
Boost.Asio 是一个跨平台的 C++ 库,用于网络和低级别 I/O 编程。它提供了一个基于事件的编程模型和异步 I/O 操作,支持同步和异步操作,适用于基于 TCP/UDP 的网络通信。
14介绍一下常用的stl容器
std::vector :动态数组,支持随机访问,动态扩展,适合需要频繁随机访问的场景。例如,存储不确定数量的元素或作为函数返回值。
2. std::map :基于红黑树的关联容器,存储键值对,按键的顺序排列,查找效率高(O(log n)),适合需要按键排序的场景,如字典实现和索引映射。
3. std::set :基于红黑树的有序集合,存储唯一元素,按键的顺序排列,查找效率高(O(log n)),适合去重和排序存储。
4. std::list :双向链表,支持在任意位置快速插入和删除元素(O(1)),但不支持随机访问,适合需要频繁插入和删除的场景,如任务队列和缓存管理。
5. std::unordered_map :基于哈希表的关联容器,存储键值对,查找效率高(平均 O(1)),不保证顺序,适合快速查找的场景,如字典实现和缓存。
6. std::unordered_set :基于哈希表的集合,存储唯一元素,查找效率高(平均 O(1)),不保证顺序,适合去重和快速查找。
15介绍一下cmake
Make 是一个跨平台的自动化构建系统,用于管理和生成项目的构建文件。它通过 CMakeLists.txt 文件定义项目的构建规则,并生成适用于不同编译器和操作系统的本地构建文件,如 Makefile 或 Visual Studio 项目文件。CMake 的主要功能包括:• 跨平台支持:支持多种操作系统和编译器。• 灵活的构建系统:支持 Makefile、Visual Studio、Xcode 和 Ninja 等。• 依赖管理:通过 find_package 查找系统库,或通过 FetchContent 嵌入依赖项。• 测试和打包:提供测试框架(CTest)和打包工具(CPack)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









