







 本文深入探讨了Twitter的Snowflake算法,一种用于生成分布式系统中全局唯一ID的高效解决方案。介绍了其64位ID的结构,包括时间戳、工作进程ID和序列号,并讨论了其优点和缺点。此外,还提到了其他分布式ID生成器如UidGenerator和美团点评的方案,以及在MySQL中的应用考虑和优化策略。
本文深入探讨了Twitter的Snowflake算法,一种用于生成分布式系统中全局唯一ID的高效解决方案。介绍了其64位ID的结构,包括时间戳、工作进程ID和序列号,并讨论了其优点和缺点。此外,还提到了其他分布式ID生成器如UidGenerator和美团点评的方案,以及在MySQL中的应用考虑和优化策略。
雪花算法的诞生?
Twitter的分布式自增ID算法snowflake,每秒能产生26万个自增可排序ID
- twitter的SnowFlake生成ID能够按照时间有序生成
- SnowFlake算法生成id的结果是一个64bit大小的整数,为一个Long类型
- 分布式系统内不会产生ID碰撞并且效率较高
分布式系统中,有些需要使用全局唯一ID的场景,生成ID的基本要求
- 在分布式的环境下必须全局唯一
- 一般需要单调递增,因为一般唯一ID都会存到数据库,而Innodb的特性就是将内容存储在主键索引树的叶子节点,而且是从左到右递增的,所以考虑到数据库的性能,一般生成的id也最好是单调递增。为防止ID冲突可以使用36位的UUID,但是UUID一般是无序的并且相对较长
组成结构:
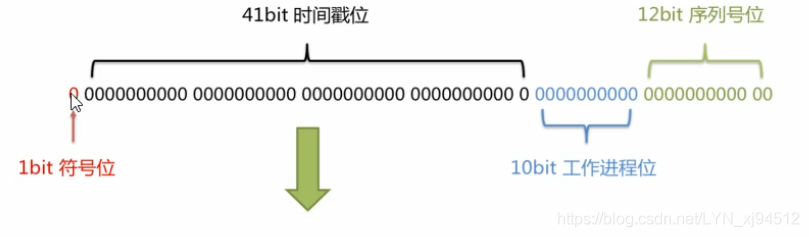
时间范围:2^41/365 * 24 * 60 * 60 * 1000L)=69.72年
工作进程数:2^10=1024
生成不碰撞序列的TPS:2^12 * 1000=409.6万
1bit符号位:永远不用,因为二进制中最高位是符号位,1表示负数,0表示正数,由于生成的id一般都是用正数,所以最高位一般固定为0
41bit-时间戳:用来记录时间戳,毫秒级别
41位可以表示2^41-1 个数字
如果只用来表示正整数,可以表示的数字范围是0~2^41-1
10bit-工作机器id,用来记录工作机器id
可以部署在1024个结点,包括5位datacenterId和5位workerId
5位可以表示的最大正整数是2^5-1=31,可以表示不同的datacenterId和workerId
12bit-序列号,用来记录同毫秒内产生的不同id
12bit可以表示最大正整数是2^12-1=4095,表示同一机器同一时间戳内产生的4095个ID序号
SnowFlake可以保证:
所有的生成的id按时间趋势递增
整个分布式系统内不会产生重复ID
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性能高,生成ID的性能也是非常高的
- 可以分局自身业务特性分配bit位,非常灵活
缺点:
- 依赖机器的时间,如果机器时间回拨,会导致重复ID生成
- 在单机上是递增的,但是由于设计到分布式环境,每台机器上时钟可能完全同步,有时会出现不同全局递增的情况
优化:
百度开源的分布式唯一ID生成器UidGenerator
美团点评分布式ID生成系统
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









