







目录
一、背景
YOLO(
You Only Look Once
)是一种目标检测算法,由Joseph Redmon等人在
2015
年提出。它的主要思想是将目标检测任务看作是一个回归问题,并且可以在一个神经网络中同时预测目标的位置和类别。该算法被命名为YOLOv1
。其中在2016年,
YOLOv2
发布,
YOLOv3
在2018年发布。
优势:
YOLO
非常快,因为将物体检测定义为回归问题,
所以检测也不需要复杂的组件。并且
YOLO
基于全图进行检测,所以不像滑动窗口和预
选区技术,
YOLO
中隐含着隐式编码的上下文信息。
缺点:
YOLO
准确率不够高;
YOLO
在定位物体,尤其是小物体上表现差;
可以检测到的目标物体较少。
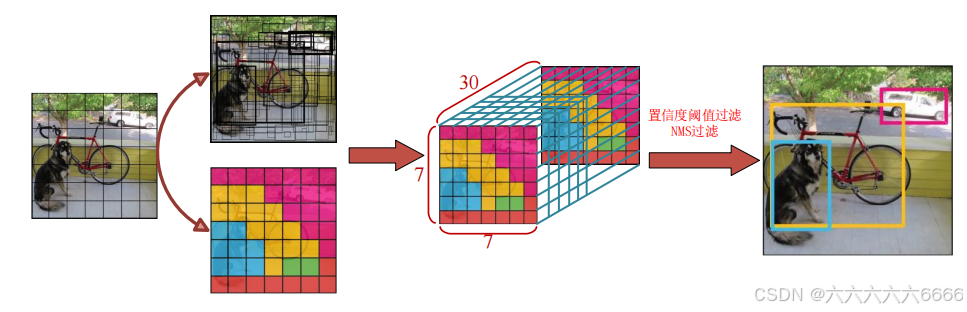
YOLOv1的思想十分简洁:仅使用一个卷积神经网络来端到端地检测目标。这一思想是对应当时主流的以R-CNN系列为代表的two-stage流派。从网络结构上来看,YOLOv1仿照GoogLeNet网络来设计主干网络,但没有采用GoogLeNet的Inception模块,而是使用串联的 1 x 1 卷积和3 x 3卷积所组成的模块,所以它的主干网络的结构非常简单。下图展示了YOLOv1的网络结构。
在深度学习中,通常三维及三维以上的矩阵都称为张量(tensor)。
在YOLO所处的年代,图像分类网络都会将特征图展平(flatten),得到一个一维特征向量,然后连接全连接层去做预测。YOLOv1继承了这个思想,将主干网络最后输出的特征图![]() 调整为一维向量
调整为一维向量![]() ,其中
,其中![]() 。然后,YOLOv1部署若干全连接层(fully connected layer)来处理该特征向量。
。然后,YOLOv1部署若干全连接层(fully connected layer)来处理该特征向量。
这里需要做一个简单的计算,从特征图被展平,再到连接4096的全连接层时,可以用以下算式很容易估算出其中的参数量:
![]()
显然,仅这一层的参数量就已经达到了十的八次方级,虽然如此之多的参数并不意味着模型推理速度一定会很慢,但必然会对内存产生巨大的压力。
YOLOv1在VOC数据集上与其他模型的性能对比。我们主要关注其中的两个指标,一个是衡量模型检测性能的平均精度(mean average precision,mAP),另一个是衡量模型检测速度的每秒帧数(frames per second,FPS)。迄今为止,mAP是目标检测领域常用的性能评价指标,其数值越高,意味着模型的检测性能越好。简单地说,mAP的计算思路是先计算每个类别的AP,然后把所有类别的AP加和并求平均值。
二、Yolov1网络
1.Yolov1网络结构
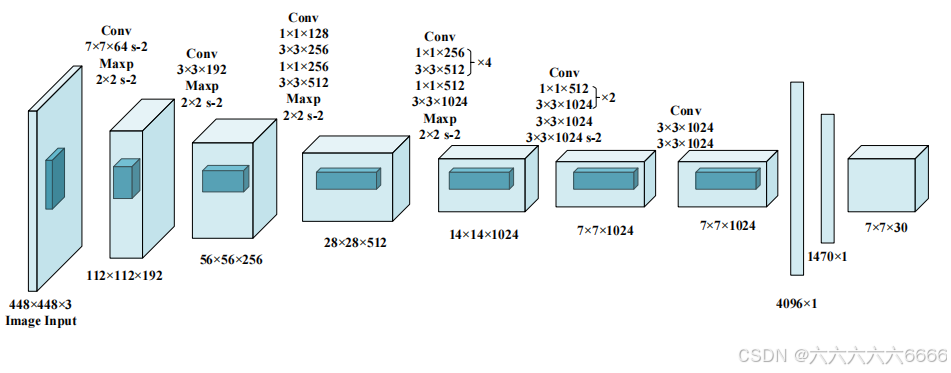
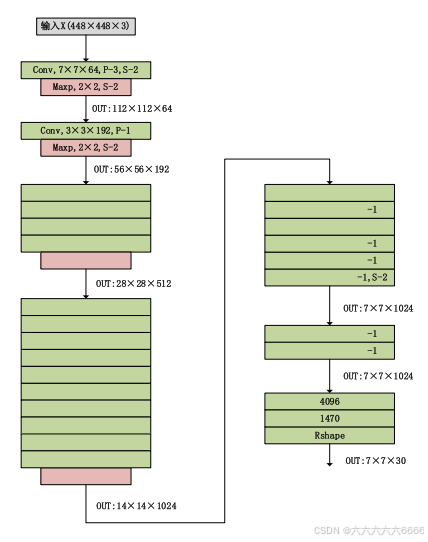
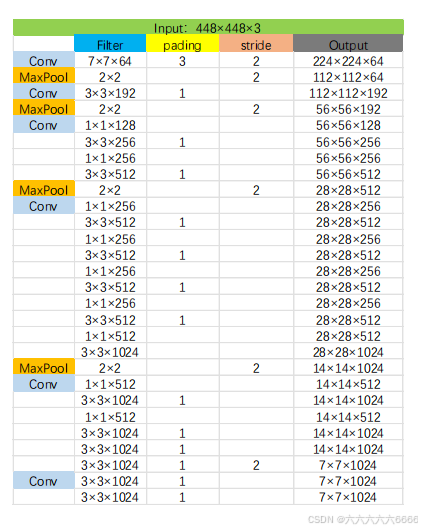
- 输入图像大小为448*448,经过若干个卷积层与池化层,变为7*7*1024 张量。
- 最后经过两层全连接层,输出张量维度为7*7*30,(即经由主干网络处理后输出一个空间大小被降采样64倍的特征图)这就是Yolov1的整个神经网络结构,和一般的卷积分类网络没有太多区别。
2.Yolov1网络参数
- 除了最后一层(即1470 x 1)使用了线性激活函数外,其余层的激活函数为 Leaky ReLU 。
- 在训练中使用了 Dropout 与数据增强的方法来防止过拟合。
- 对于最后一个卷积层,它输出一个形状为 (7, 7, 1024) 的张量。 然后张量展开。使用2个全连接层作为一种线性回归的形式,它输出1470个参数,然后reshape为 (7, 7, 30) 。
三、Yolov1模型检测原理
1.Yolov1的总体概述
通过前面的分析,目标检测模型和图像分类模型并没有太大的区别,都是输入图像,经过模型,输出结
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8715
8715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









