







 本文深入探讨C语言中的内存区域,详细分析数据类型的本质、指针运算、函数调用模型和栈区特性。同时,介绍了指针在动态内存管理、二级指针、回调函数和字符串操作中的应用,以及结构体、宏定义和动态库封装的知识点。
本文深入探讨C语言中的内存区域,详细分析数据类型的本质、指针运算、函数调用模型和栈区特性。同时,介绍了指针在动态内存管理、二级指针、回调函数和字符串操作中的应用,以及结构体、宏定义和动态库封装的知识点。
- 面向过程:接口(api)、过程的封装和设计
内存中的四个区域

数据类型本质分析
- 数据类型的本质是一个固定内存块大小的别名
- sizeof是操作符,不是函数;sizeof测量的实体类型的大小为编译期间就已确定。
- 指针运算的步长和类型有关,比如:
int array[10] = {0};
printf("&array = %p, array = %p, &array+1 = %p, array+1 = %p\n", &array, array, &array+1, array+1);
//前两个输出地址相同,都是array首元素地址值
//第三个输出值比前两个输出地址值大40,因为&array的类型是(int[10])*
//最后一个输出值比前两个地址值大4,因为array的类型是int *
- void *是万能指针
- 栈区 vs. 栈:栈区不是栈,栈是一种数据结构,而栈区是一种内存,只不过栈区存放数据的方式是栈的方式(后进先出)。
- 通过指针在堆区开辟一块内存移动要结合NULL来操作,防止野指针问题。比如:
char *p = NULL;
p = (char *)malloc(100);
if(p == NULL) {
fprintf(stderr, "malloc error\n");
return;
}
函数的调用模型
- 函数调用变量传递分析:
以在main函数中调用子函数func1、func1中调用func2为例:
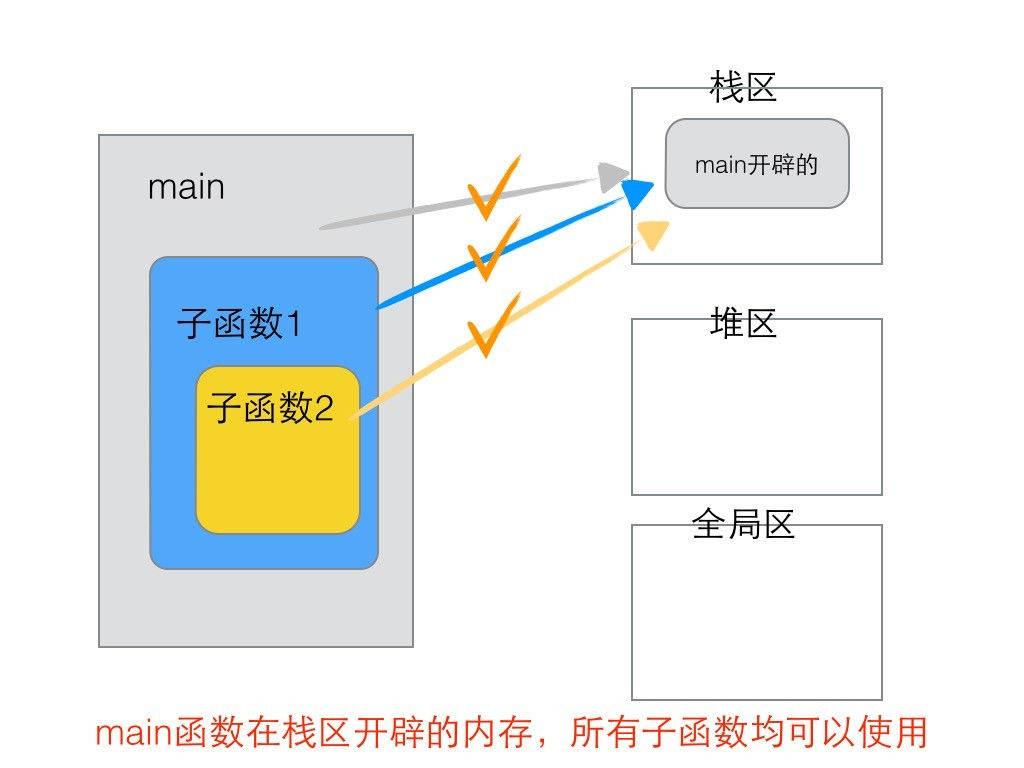
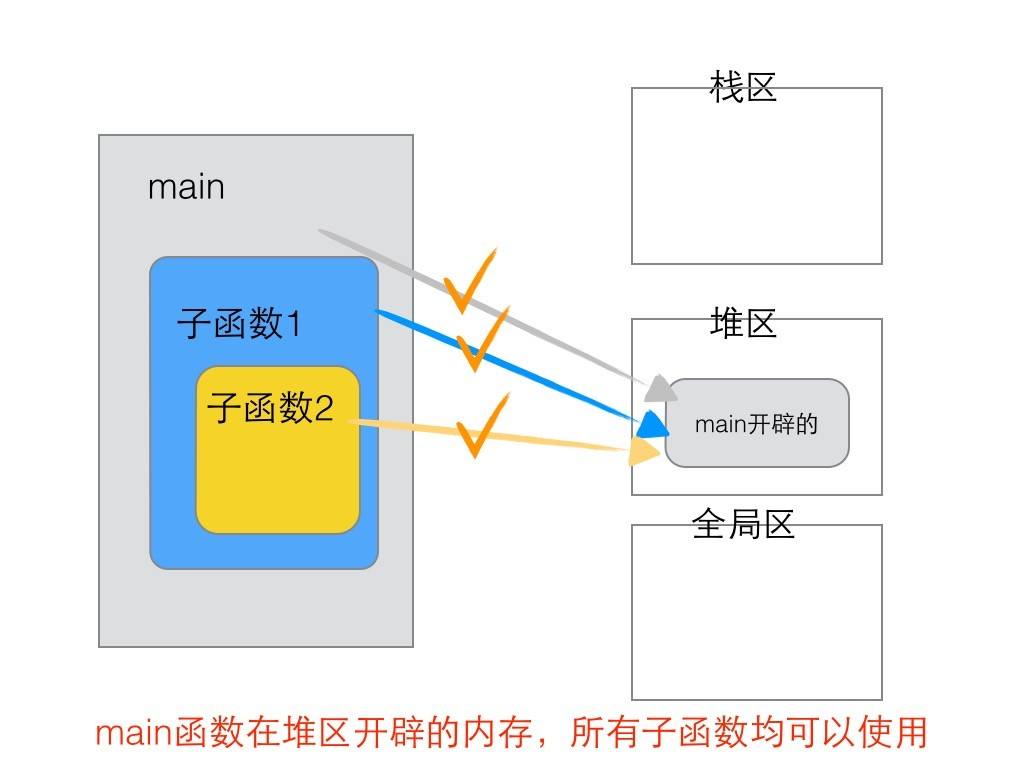
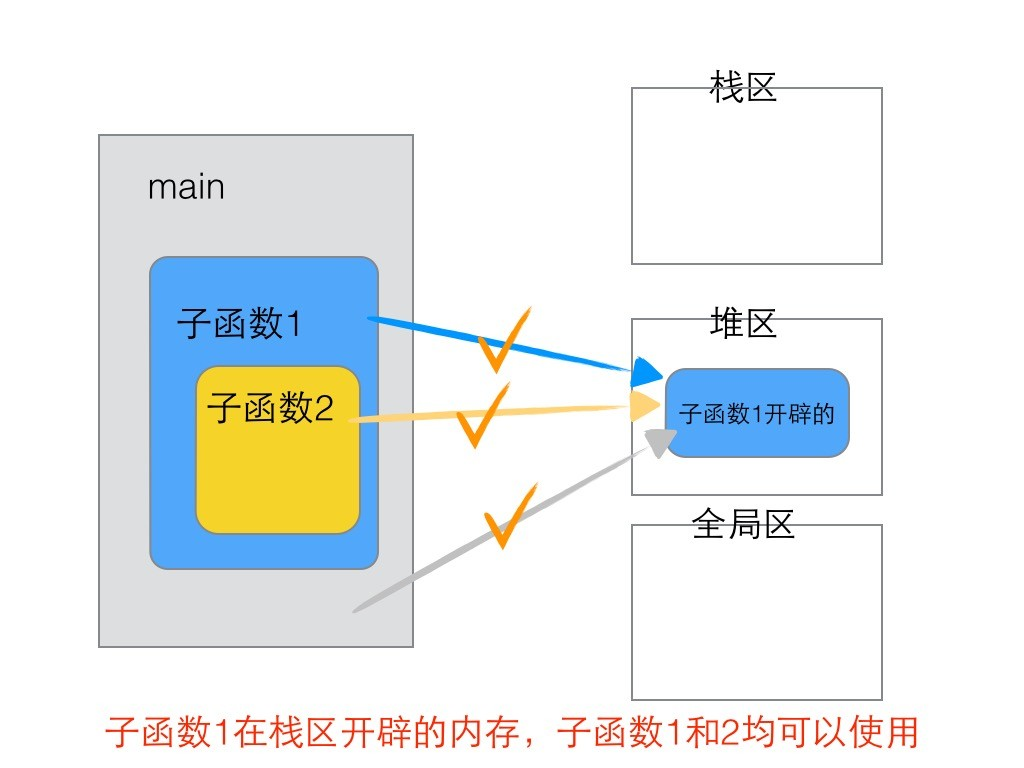

总结:
- main函数中可以在栈/堆/全局分配内存,都可以被func1和func2使用.
- func2在栈上分配的内存,不能被func1和main函数使用
- func2中malloc的内存(堆),可以被main和func1函数使用。
- func2中全局分配“abcdefg”(常量全局区)内存,可以被func1和main函数使用.
- 栈的开口方向(或增长方向):向低地址方向生长,即压栈时栈指针减小,退栈时栈指针增大。
指针的进一步理解
- 段错误(segmentation fault):
- 对只读区域进行写操作。比如:char *p = “hello”; p[0] = ‘H’;
- 对非访问区域进行读写操作。
- stack空间耗尽。 比如:函数内部 int arr[N]= {1}; #define N 100000000
- 如果要通过函数的参数传递来修改调用函数的变量,那么必须传地址而非传值,从而被调用的函数形参必须为相应类型的指针变量。这对于任意数据类型都成立。比如,要通过一个子函数为main函数动态申请一块堆内存:
int get_mem(int **pp1, int len1) { //在堆区申请一块内存供主函数main使用
*pp1 = malloc(len1);
if(*pp1) return 1;
return 0;
} //本来该函数可以没有返回值,之所以设置一个int型返回值并在结尾返回0是为了以后便于扩展,即可通过不同的返回值指定不同含义。此种用法很常见。
int main() {
int *p1 = NULL;
int len1 = 0;
printf("Enter the length of memory you want:\n");
scanf("%d", &len1);
int result = 0;
result = get_mem(&p1, len1);
return 0;
}
//上述程序也是通过调用子函数修改main函数中的变量值的例子,只不过此处修改的是main中一个指针变量的值,所以子函数中对应形参为一个二级指针。
- 二级指针:
作为输出参数:二级指针作为子函数的输出参数最常见的用法就是,在子函数中申请一块堆内存空间,然后传出去。见上例。后续还要释放这块在子函数中申请到的堆内存。见下例:
void free_mem(char **pp1) {
char *temp = *pp1;
if(pp1 != NULL) {
free(temp); //释放掉这块内存
}
*pp1 = NULL; //防止野指针
}
作为输入参数:
(1)作为指针数组,比如:
char *myArray[] = {"aaaaaa", "ccccc", "bbbbbb", "111111"};
//int len = sizeof(myArray)/sizeof(myArray[0]);//该形参数组长度
//若要对该数组元素指向的字符串进行排序,可通过一个临时指针变量char *temp
int sort_array(char *array[], int len)
{
int i = 0;
int j = 0;
char *temp = NULL;
for (i = 0; i < len; i++) {
for (j = i; j < len; j++) {
if (strcmp(array[i], array[j]) > 0) {
temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
}
return 0;
}
(2)作为二维数组,比如:
char my_array[5][6] = { "aaa", "ccc", "bbb", "111" };
//若要对每个一维数组中包含的字符串进行排序,不可再像(1)中那样借由一个指针变量,而应使用字符串拷贝函数strcpy
//因为此时是每个一维数组名指向每个字符串,而数组名是常量指针,其指向不可以改变
int sort_array(char array[][6], int num) //每个数组元素的类型为6个char的数组
//二维数组形参也可写为:int sort_array(char (*array)[6], int num)
{
char temp[6] = { 0 };//注意
int i = 0;
int j = 0;
for (i = 0; i < num; i++) {
for (j = i; j< num; j++) {
if (strcmp(array[i], array[j]) > 0) {
strcpy(temp, array[i]);
strcpy(array[i], array[j]);
strcpy(array[j], temp);
}
}
}
return 0;
}
(3)在堆上开辟多个堆内存,比如:
char ** get_mem(int num) {
char **array = NULL;
int i = 0;
array = (char**)malloc(sizeof(char*)* num);//在堆上开辟num个 char*指针
if (array == NULL) {
fprintf(stderr, "malloc char **array error\n");
return NULL;
}
memset(array, 0, sizeof(char*)*num); //开辟子堆内存之前先把每个指针变量的值清空
for (i = 0; i < num; i++) {
array[i] = (char*)malloc(64);
if (array[i] == NULL) {
fprintf(stderr, "maloc array[%d] error\n", i);
return NULL;
}
sprintf(array[i], "%d%d%d%d", 9-i, 9-i, 9-i, 9-i);//赋值
}
return array;
}
void free_mem(char **array, int num) { //释放堆内存,注意先后顺序
char **temp_array = array;
int i = 0;
if (array == NULL) {
return;
}
for (i = 0; i < num; i++) {
if (temp_array[i] != NULL) {
free(temp_array[i]);
temp_array[i] = NULL;
}
}
free(temp_array);
temp_array = NULL;
}
//交换两个子堆内存中的内容的方式和二级指针作为第一种输入参数时相同,即借由一个临时指针变量即可。
通过指针可以在子模块中将已经计算好的数据传出来,就完成主业务逻辑层和子模块的业务分离,是一种解耦合效果。目标是实现高内聚低耦合。
- 指针 vs. 数组名:数组名是一个常量地址,不能像指针变量那样自增或自减,也即不能改变数组名的值。栈是操作系统开辟和回收的,它根据数组名来找到该数组在内存中占用的一块连续内存,如果首地址变量改变了,该块内存将无法准确回收。
- 数组指针:一个数组指针指向比它低一维度的数组,比如:
typedef int (*INT_5)[5];
INT_5 p = NULL;//定义一个指向有5个整型元素数组的指针
int a[3][4];
typedef int (*INT_3_4)[3][4];
INT_3_4 q = &a; //定义一个指向二维数组int [3][4]的指针q并赋值为数组a的首地址
// a 是一个 指针, 指向 此二维数组首元素(int[4])的地址, int (*)[4] ==>二级指针 指向一维数组
// &a 也是一个指针, 指向 此二维数组(int[3][4])的地址, int(*p)[3][4] ---> 三级指针 指向一个二维数组
- 回调函数:形参中包含函数指针,即指向函数的指针,达到在一个函数中调用另一个函数的目的。函数指针不同于指向数组、结构体等的指针,它仅仅代表代码区中函数的指向入口,其值为函数在内存中的地址,而没有大小之分,即不可以对函数指针执行算术运算。
比如:
int func1(int a, int b) {
return a+b;
}
int (*p)(int, int) = NULL; //定义一个函数指针指向返回值为int并且有两个int形参的函数类型
typedef int(*FP)(int, int);//定义这种函数指针并取一个别名为FP
FP p = func1;//和上上句作用相同
int func2(int a, int b, FP p) { //int func2(int a, int b, int(*p)(int, int))
return p(a, b);//在func2中调用另一个函数
}
//主函数中,在func2中调用func1:
func2(11, 22, func1);
- 理解一个表达式:
(void(*)(void))0 //将内存中的0地址转换成一个函数指针void (*)(void)
//比如,知道某个函数
void func(void) {
......
}
知道这个函数体的入口是在内存中地址为0的地方,但函数名找不到了,可用如下的方式来调用这个函数:
(*(void(*)())0)() //将0地址转换成一个函数指针再调用,当然这种用法实际上很少用到,只是加深对函数指针的理解。
- 函数指针数组的定义,比如:
typedef int(*Fp)(int);
Fp a[10];//定义有10这种函数指针类型元素的数组
//另一种等价的定义
int(*ffp[10])(int);
字符串
- strstr函数:在一个字符串中查找某一个子串,若找到则返回该子串第一次出现的位置,若未找到则返回NULL。例如:
char *str = "************"; //某一个母字符串
char *sub_str = "----"; //某一个子串
char *p = str;
int cnt = 0;
while((p = strstr(p, sub_str)) != NULL) {
//找到了子串
cnt++; //统计子串在母串中出现的次数
p += strlen(sub_str);
if(*p == '\0') break;//如果子串恰好在母串的结尾,则此时p变为NULL,就不能再调用strstr函数了
}
- sizeof运算符和strlen函数的区别:
1, sizeof为一个操作符,执行sizeof的结果,在编译期间就已经确定;strlen是一个函数,是在程序执行的时候才确定结果。
2, sizeof和strlen对于求字符串来讲,sizeof() 字符串类型的大小,包括’\0’;strlen() 字符串的长度不包括’\0’。 - 逆置字符串的递归实现:
void inverseString(char *src, char *dst) {
if (*src != '\0') {
inverseString(src + 1, dst);
}
strncat(dst, src, 1);
}
//注意到这个函数中存储转换后的字符串的指针变量dst虽是一个局部变量,但在整个递归直至结束的过程中其值始终不变,有全局变量的效果
//另外要注意,在main函数中传入目的字符数组之前要先把它所有元素置为0,因为strncat每次在目的数组的结尾处也即\0处继续添加新内容,提前将其清空可防止目的数组中出现不想要的乱码
- C 语言中的 const关键字并不能起到常量的作用:可通过指针间接修改const限定的变量,也可以通过强制类型转换来修改。比如:
const int a = 10;
int *p = &a;//最新实测,本句在vs中编译不通过
*p = 20;//通过指针间接修改const变量
printf("a = %d\n", a); //输出为20
void const_test(const int *a) {
*((int *)a) = 30; //C语言中的强制类型转换是万能的,甚至可以修改变量的const属性
}
const int a = 10;
const_test(&a);
printf("a = %d\n", a); // 输出为30
//最新实测,在vs中改不了常量a的指,仍然是10.在其他环境中就不能保证了。
结构体
- 浅拷贝和深拷贝:见下例
//如果结构体中有指针 并且指向在堆上开辟的一块空间,那么直接在结构体之间赋值很可能会出现问题
void copy_teacher(struct teacher *to, struct teacher *from) { //浅拷贝
//结构体可以通过变量直接赋值, 但不要使用这种方法
*to = *from;
}
void copy_teacher_deep(struct teacher *to, struct teacher *from) { //深拷贝
//要给结构体中的成员一个一个拷贝
to->name = (char*)malloc(NAME_LEN);//给另一个结构体变量的指针变量开辟另一块堆空间
memset(to->name, 0, NAME_LEN);
strcpy(to->name, from->name); //复制堆空间的内容而非浅拷贝那样直接复制同一块堆内存的地址
to->id = from->id;
}
//当执行浅拷贝后,以下分别释放两个结构体变量中的指针成员指向的堆内存就会出问题
//因为浅拷贝是两个结构体变量的指针成员指向了同一块堆内存,造成多次释放,引起系统崩溃
if (tp1.name != NULL) {
free(tp1.name);
tp1.name = NULL;
}
if (tp2.name != NULL) {
free(tp2.name);
tp2.name = NULL;
}
所以,虽然结构体变量之间可以通过直接赋值达到拷贝效果,但当有指针成员时,不建议这么做。
宏定义
-
宏函数和普通函数的区别:
宏函数是由预处理器简单地对代码的替换,没有语法校验;而函数是由编译器调用的,会对参数的类型和语法进行校验。另外,定义宏函数时一定要给每个参数加括号,以免在代码替换时和其他操作符连在一起时出现意外的作用。也不要给宏函数传带有副作用的参数,比如自增或自减。 -
宏函数的另一个注意事项:
若定义的宏函数中有不止一条语句时,要用大括号把它们括起来,而且最后的分号也要注意。比如:
//'\'为续行符,注意每个续行符后面什么都不要加,包括空格也不行!
#define FREE(p) \
{\
free(p); \
p = NULL; \
}
//接下来在主函数中使用这个宏函数:
if(p != NULL)
FREE(p);
else
printf("p == NULL\n");
//会出现问题
//if(p != NULL)
{
free(p);
p = NULL;
}; //多了一个分号
else
printf("p == NULL\n");
//因为习惯在函数中每条语句末尾会加分号,所以可按如下方式改进:
//改进:宏函数的do-while(0)用法
#define FREE(p) \
do{\
free(p); \
p = NULL; \
}while(0)
//这个do-while循环的循环体只会执行一次
//FREE(p);这种写法就正确了,因为do-while循环的结尾本来就是一个分号
- 用宏函数封装debug接口:
//宏定义中参数前若有一个#,表示将后面的参数转为字符串;若有两个##,表示拼接字符
//__VA_ARGS__表示可变参数
#define DEBUG(format, ...) \
fprintf(stderr, "[DEBUG][%s:%d][%s][%s]"format, __FUNCTION__, __LINE__, __DATE__, __TIME__, ##__VA_ARGS__);//__VA_ARGS__ === a,b
#define ERROR(format, ...)\
fprintf(stderr, "[ERROR][%s:%d][%s][%s]"format, __FUNCTION__, __LINE__, __DATE__, __TIME__, ##__VA_ARGS__);
#define LOG(format, ...)\
fprintf(stderr, "[LOG][%s:%d][%s][%s]"format, __FUNCTION__, __LINE__, __DATE__, __TIME__, ##__VA_ARGS__);
//在实际项目开发中,上述这三条宏定义很重要,记录的是程序的运行信息,通常把它们的输出信息写进日志文件中便于程序的后期维护。
//例如,可以在链表接口的头文件中插入这一段宏定义,那么在定义文件和主函数中就可以使用这些宏定义输出必要的运行信息了。
//在主函数中的用法:
char *p = NULL;
p = malloc(100);
if (p != NULL) {
ERROR("malloc p error\n"); //打印出:[ERROR][main:83][Mar 21 2018][12:44:42]malloc p error
}
DEBUG("a= %d, b = %d\n", a, b); //打印出:[DEBUG][main:86][Mar 21 2018][12:44:42]a= 10, b = 20
LOG("a = %d, b = %d\n", a, b); //打印出:[LOG][main:89][Mar 21 2018][12:44:42]a = 10, b = 20
//注意,格式符中两个用双引号包含的相邻的字符串会自动拼接成一个字符串。
Windows下动态库的封装
- 动态库即提供给别人使用的第三方库,相当于C标准库提供的libc动态库。Windows下动态库的后缀名为.dll,而Linux下为.so。动态库是一个二进制文件,看不到源代码,但可使用里面的接口函数。不过C标准库开源了其源文件。
- 在源文件中通过include预编译指令引入动态库的头文件,然后在编译完成之后的链接阶段会把.dll二进制文件链接进来形成完整的可执行程序。(注意:需要把.lib文件手动添加到链接器的输入中。以vs2013为例,项目属性->配置属性->链接器->输入->附加依赖项:输入.lib文件名)
- Windows下的动态库还要伴随另一个后缀名为.lib的文件才能找到.dll文件来执行它(Linux下只需要.so文件即可)。
- 当发现Windows下动态库没有.lib文件生成时,需要在动态库中每个函数(包括在头文件和实现文件中)的头部之前添加如下的一个宏:
__declspec(dllexport)
- 接下来编译定义源文件,注意只有执行才会生成.dll文件,尽管执行会出错,因为没有主函数main.
- 最终提供给别人使用的动态库包括头文件、.lib文件和.dll文件。

















 8090
8090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









