



前言
本文章是结合网上资料和自己的工程代码分析写出,由于写的时间较长了,已经不记得参考了哪些文章,如果有侵权,请练习删除,不做商业用途
surfaceflinger(显示合成系统)是一个系统服务。显示合成分为两种,一种是硬件融合,一种是软件融合,硬件融合是Overlay,由硬件驱动负责merge Overlay buffer和主屏buffer中的内容。主要是使用在视频播放和Camwera preview等方式,硬件实现也有两种方式:一种是在SurfaceFlinger中实现Overlay hal,,另一种是在驱动中直接将信息发送到Overlay Buffer,直接绕过android上层,速度会很快。
软件融合是SurfaceFlinger,主要实现surface的建立、控制、管理等功能。surface就是window。首先明确,SurfaceFlinger只是负责merge Surface的控制,比如计算两个Surface的重叠部分的区域。至于Surface显示的内容,则是通过其他的skia,opengl等来计算,因此在学习SurfaceFlinger框架要先忽略显示的内容,
一、Surface创建
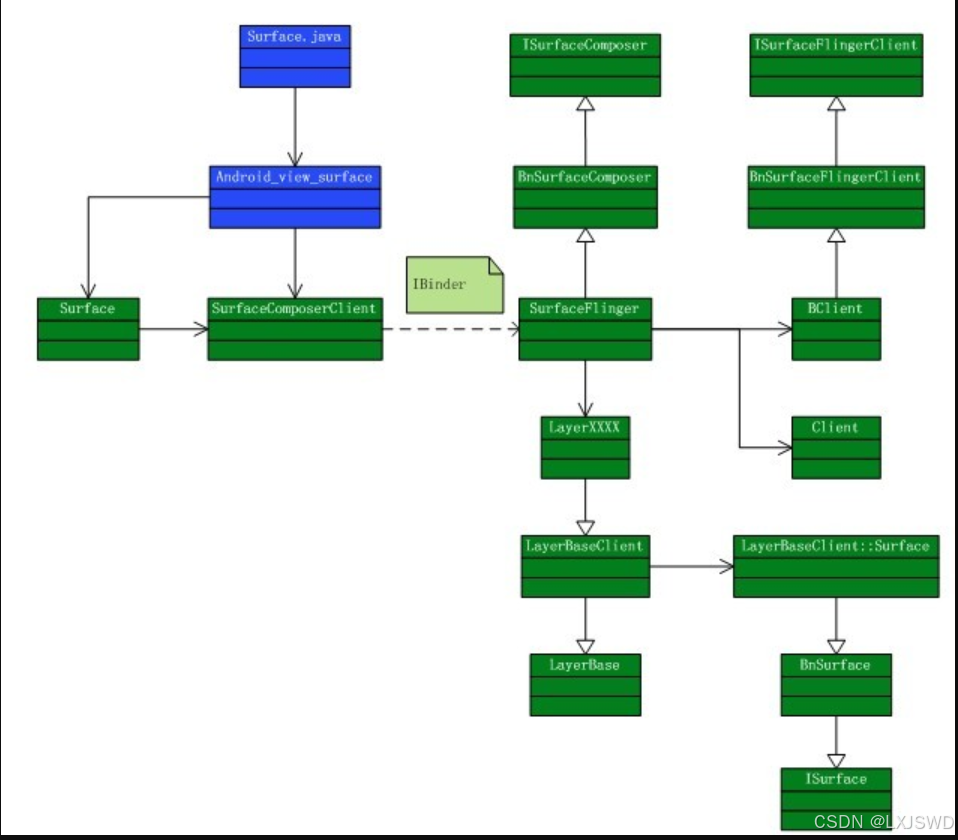
每个应用存在一个或者多个Surface,我们需要一些数据结构来储存窗口信息和buffer来存储窗口的内容,上图是Surface创建的过程的类图。
在IBinder的左边就是客户端的部分,右边就是Surface Flinger service,创建一个surface分为两个过程,一个,是在SurfaceFlinger这边为每个程序创建一个管理结构,另一个就是创建存储的内容的buffer,以及这个buffer上的一系列画图之类的操作,SurfaceFlinger为管理多个surface提供了一个Client类,每个请求服务的程序就对应了一个Client,因为surface是在SurfaceFlinger创建的,因此必须返回一个结构让应用程序知道自己申请的surface信息,因此SurfaceFlinger将Client创建的控制结构per_client_cblk_t经过BClient的封装后返回给SurfaceComposerClient,并行应用程序提供一组创建和销毁surface的操作。
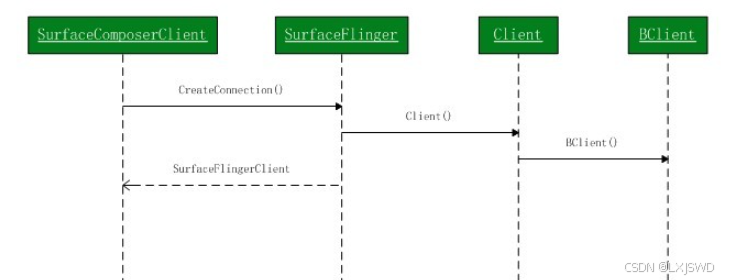
SurfaceFliner控制什么时候应该进行这些信息的处理和处理过程,所有实际的处理是在Layer中,创建一个Surface就创建了一个Layer,Android提供了,四种Layer,Layer , LayerBlur , LayerBuffer ,LayerDim 。
常用的是LayerBuffer和Norm Layer,
Norm Layer是Android中最常用的Layer,一般的应用程序在创建 surface 的时候都是采用的这样的 layer ,了解 Normal Layer 可以让我们知道 Android 进行 display 过程中的一些基础原理。 Normal Layer 为每个 Surface 分配两个 buffer : front buffer 和 back buffer ,这个前后是相对的概念,他们是可以进行 Flip 的。 Front buffer 用于 SurfaceFlinger 进行显示,而 Back buffer 用于应用程序进行画图,当 Back buffer 填满数据 (dirty) 以后,就会 flip, back buffer 就变成了 front buffer 用于显示,而 front buffer 就变成了 back buffer 用来画图,这两个 buffer 的大小是根据 surface 的大小格式动态变化的。这个动态变化的实现我没仔细看,可以参照 : /frameworks/base/lib/surfaceflinger/layer.cpp 中的 setbuffers() 。
两个 buffer flip 的方式是 Android display 中的一个重要实现方式,不只是每个 Surface 这么实现,最后写入 FB 的 main surface 也是采用的这种方式。
LayerBuffer 也是将来必定会用到的一个 Layer ,个人觉得也是最复杂的一个 layer ,它不具备 render buffer ,主要用在 camera preview / video playback 上。它提供了两种实现方式,一种就是 post buffer ,另外一种就是我们前面提到的 overlay , Overlay 的接口实际上就是在这个 layer 上实现的。不管是 overlay 还是 post buffer 都是指这个 layer 的数据来源自其他地方,只是 post buffer 是通过软件的方式最后还是将这个 layer merge 主的 FB,而 overlay 则是通过硬件 merge 的方式来实现。与这个 layer 紧密联系在一起的是 ISurface 这个接口,通过它来注册数据来源,例如:
// 要使用 Surfaceflinger 的服务必须先创建一个 client
sp client = new SurfaceComposerClient();
// 然后向 Surfaceflinger 申请一个 Surface , surface 类型为 PushBuffers
sp surface = client->createSurface(getpid(), 0, 320, 240, PIXEL_FORMAT_UNKNOWN, ISurfaceComposer::ePushBuffers);
// 然后取得 ISurface 这个接口, getISurface() 这个函数的调用时具有权限限制的,必须在Surface.h 中打开: /framewoks/base/include/ui/Surface.h
sp isurface = Test::getISurface(surface);
//overlay 方式下就创建 overlay ,然后就可以使用 overlay 的接口了
sp ref = isurface->createOverlay(320, 240, PIXEL_FORMAT_RGB_565);
sp verlay = new Overlay(ref);
//post buffer 方式下,首先要创建一个 buffer ,然后将 buffer 注册到 ISurface 上
ISurface::BufferHeap buffers(w, h, w, h, PIXEL_FORMAT_YCbCr_420_SP,transform,0,mHardware->getPreviewHeap());
mSurface->registerBuffers(buffers);
二、应用程序对窗口的控制和画图
Surface创建后,应用程序即可在Buffer中画图了,因此,其中我们需要面临几个问题
1、程序怎么知道在哪个Buffer上画图的。
2、画图后如何通知Surface Flinger来进行flip。
3、除了画图,如果我们移动了窗口或改变了窗口大小的时候,SuferFlinger是如何来处理的。
从类图中可以看到 SurfaceFlinger 是一个线程类,它继承了 Thread 类。当创建 SurfaceFlinger这个服务的时候会启动一个 SurfaceFlinger 监听线程,这个线程会一直等待事件的发生,比如说需要进行 sruface flip ,或者说窗口位置大小发生了变化等等,一旦产生这些事件,SurfaceComposerClient 就会通过 IBinder 发出信号,这个线程就会结束等待处理这些事件,处理完成以后会继续等待,如此循环。
SurfaceComposerClient 和 SurfaceFlinger 是通过 SurfaceFlingerSynchro 这个类来同步信号的,其实说穿了就是一个条件变量。监听线程等待条件的值变成 OPEN ,一旦变成 OPEN 就结束等待并将条件置成 CLOSE 然后进行事件处理,处理完成以后再继续等待条件的值变成 OPEN ,而 Client 的Surface 一旦改变就通过 IBinder 通知 SurfaceFlinger 将条件变量的值变成 OPEN ,并唤醒等待的线程,这样就通过线程类和条件变量实现了一个动态处理机制。
了解了 SurfaceFlinger 的事件机制我们再回头看看前面提到的问题了。首先在对 Surface 进行画图之前必须锁定 Surface 的 layer ,实际上就是锁定了 Layer_cblk_t 里的 swapstate 这个变量。SurfaceComposerClient 通过 swapstate 的值来确定要使用哪个 buffer 画图,如果 swapstate 是下面的值就会阻塞Client :
// We block the client if:
// eNextFlipPending: we've used both buffers already, so we need to
// wait for one to become availlable.
// eResizeRequested: the buffer we're going to acquire is being
// resized. Block until it is done.
// eFlipRequested && eBusy: the buffer we're going to acquire is
// currently in use by the server.
// eInvalidSurface: this is a special case, we don't block in this
// case, we just return an error.
所以应用程序先调用 lockSurface() 锁定 layer 的 swapstate ,并获得画图的 buffer 然后就可以在上面进行画图了,完成以后就会调用unlockSurfaceAndPost() 来通知 SurfaceFlinger 进行 Flip。或者仅仅调用 unlockSurface() 而不通知 SurfaceFlinger 。
一般来说画图的过程需要重绘 Surface 上的所有像素,因为一般情况下显示过后的像素是不做保存的,不过也可以通过设定来保存一些像素,而只绘制部分像素,这里就涉及到像素的拷贝了,需要将 Front buffer 的内容拷贝到 Back buffer 。在 SurfaceFlinger 服务实现中像素的拷贝是经常需要进行的操作,而且还可能涉及拷贝过程的转换,比如说屏幕的旋转,翻转等一系列操作。因此 Android 提供了拷贝像素的 hal ,这个也可能是我们将来需要实现的,因为用硬件完成像素的拷贝,以及拷贝过程中可能的矩阵变换等操作,比用 memcpy 要有效率而且节省资源。这个 HAL 头文件 在:/hardware/libhardware/hardware/include/copybit.h,但是我的工程里没有。
窗口状态变化的处理是一个很复杂的过程, SurfaceFlinger 只是执行 Windows manager 的指令,由 Windows manager 来决定什么是偶改变大小,位置,设置 透明度,以及如何调整 layer 之间的顺序, SurfaceFlinger 仅仅只是执行它的指令。PS : Windows Manager 是java层的一个服务,提供对所有窗口的管理功能。以后需要具体学习。
窗口状态的变化包括位置的移动,窗口大小,透明度, z-order 等等,首先我们来了解一下SurfaceComposerClient 是如何和 SurfaceFlinger 来交互这些信息的。当应用程序需要改变窗口状态的时候它将所有的状态改变信息打包,然后一起发送给 SurfaceFlinger , SurfaceFlinger 改变这些状态信息以后,就会唤醒等待的监听线程,并设置一个标志位告诉监听线程窗口的状态已经改变了,必须要进行处理,在 Android 的实现中,这个打包的过程就是一个 Transaction ,所有对窗口状态(layer_state_t) 的改变都必须在一个 Transaction 中。
到这里应用程序客户端的处理过程已经说完了,基本分为两个部分,一个就是在窗口画图,还一个就是窗口状态改变的处理。
三、SurfaceFlinger的处理过程,
了解了 Flinger 和客户端的交互,我们再来仔细看看 SurfaceFlinger 的处理过程,前面已经说过了SurfaceFlinger 这个服务在创建的时候会启动一个监听的线程,这个线程负责每次窗口更新时候的处理,下面我们来仔细看看这个线程的事件的处理,大致就是下面的这个图:
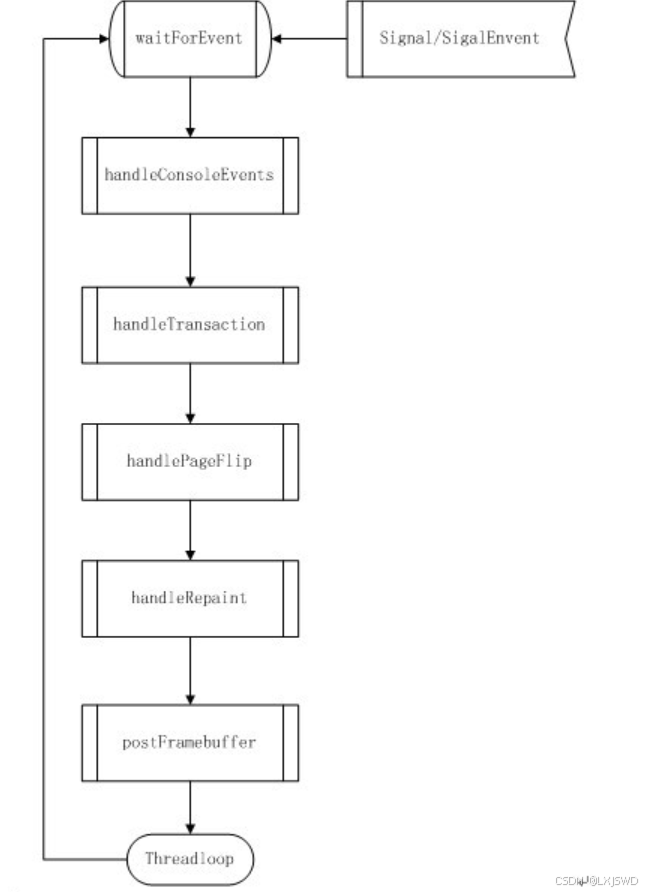
再此,说明一下Android组合各个窗口的原理:Android实际通过计算各个窗口的可见区域,就是我们在屏幕上可见的窗口区域( 用 Android的词汇来说就是 visibleRegionScreen ) ,然后将各个窗口的可见区域画到一个主 layer 的相应部分,最后就拼接成了一个完整的屏幕,然后将主 layer 输送到 FB 显示。在将各个窗口可见区域画到主 layer 过程中涉及到一个硬件实现和一个软件实现的问题,如果是软件实现则通过 Opengl 重新画图,其中还包括存在透明度的 alpha 计算;如果实现了 copybit hal 的话,可以直接将窗口的这部分数据 直接拷贝过来,并完成可能的旋转,翻转,以及 alhpa 计算等。
1、handleConsoleEvent
当接收到 signal 或者 singalEvent 事件以后,线程就停止等待开始对 Client 的请求进行处理,第一个步骤是 handleConsoleEvent ,这个步骤和 /dev/console 这个设备有关,它会取得屏幕或者释放屏幕,只有取得屏幕的时候才能够在屏幕上画图。
2、handleTransaction
前面提到过,窗口状态的改变只能在一个 Transaction 中进行。因为窗口状态的改变可能造成本窗口和其他窗口的可见区域变化,所以就必须重新来计算窗口的可见区域。在这个处理子过程中 Android 会根据标志位来对所有 layer 进行遍历,一旦发现哪个窗口的状态发生了变化就设置标志位以在将来重新计算这个窗口的可见区域。在完成所有子 layer 的遍历以后, Android 还会根据标志位来处理主 layer ,举个例子,比如说传感器感应到手机横过来了,会将窗口横向显示,此时就要重新设置主 layer 的方向。
3、handlePageFlip
这里会处理每个窗口 surface buffer 之间的翻转,根据 layer_state_t 的 swapsate 来决定是否要翻转,当 swapsate 的值是 eNextFlipPending 是就会翻转。处理完翻转以后它会重新计算每个 layer的可见区域,计算的大致是一个这么的过程:
从 Z 值最大的 layer 开始计算,也就是说从最上层的 layer 计算,去掉本身的透明区域和覆盖在它上面的不透明区域,得到的就是这个 layer 的可见区域。然后这个 layer 的不透明区域就会累加到不透明覆盖区域,这个 layer 的可见区域会放入到主 layer 的可见区域,然后计算下一个 layer ,直到计算完所有的 layer 的可见区域。这中间的计算是通过定义在 skia 中的一种与或非的图形逻辑运算实现的,类似我们数学中的与或非逻辑图。
4、handleRepaint
计算出每个 layer 的可见区域以后,这一步就是将所有可见区域的内容画到主 layer 的相应部分了,也就是说将各个 surface buffer 里面相应的内容拷贝到主 layer 相应的 buffer ,其中可能还涉及到alpha 运算,像素的翻转,旋转等等操作,这里就像我前面说的可以用硬件来实现也可以用软件来实现。在使用软件的 opengl 做计算的过程中还会用到 PixFlinger 来做像素的合成。
5、postFrameBuffer
最后的任务就是翻转主 layer 的两个 buffer ,将刚刚写入的内容放入 FB 内显示了。
四、HAL层–HWComposer
硬件抽象层,android的HAL层提供了Gralloc,包括了fb和gralloc两个设备,前者是负责打开内核中的framebuffer,初始化配置,后者是股那里缓冲帧的分配和释放。
在HAL层中存在一个重要的模块"Composer",他魏厂商定制UI合成提供接口,Composer的直接使用者是SurfaceFlinger中的HWCposer。
1、Gralloc模块
对应接口结构体源码如下
hardware\libhardware\include\hardware\gralloc.h
typedef struct gralloc_module_t {
struct hw_module_t common;//每个硬件模块对应的结构都需要hw_module_t这个抽象模块
int (*registerBuffer)(struct gralloc_module_t const* module,
buffer_handle_t handle);
int (*unregisterBuffer)(struct gralloc_module_t const* module,
buffer_handle_t handle);
int (*lock)(struct gralloc_module_t const* module,
buffer_handle_t handle, int usage,
int l, int t, int w, int h,
void** vaddr);
int (*unlock)(struct gralloc_module_t const* module,
buffer_handle_t handle);
……………
void* reserved_proc[3];
} gralloc_module_t;
Gralloc模块负责管理gralloc设备和fb设备,它是处于HAL层的,向上提供了这个两个设备的功能。其中最主要的两个接口分别为gralloc_device_open和gralloc_alloc。
我们先看gralloc_device_open,这个方法负责打开gralloc或者fb设备的。
//gralloc模块的打开设备方法
int gralloc_device_open(const hw_module_t* module, const char* name,
hw_device_t** device)
{
int status = -EINVAL;
if (!strcmp(name, GRALLOC_HARDWARE_GPU0)) {//打开GPU
gralloc_context_t *dev;
dev = (gralloc_context_t*)malloc(sizeof(*dev));
/* initialize our state here */
memset(dev, 0, sizeof(*dev));
/* initialize the procs */
dev->device.common.tag = HARDWARE_DEVICE_TAG;
dev->device.common.version = 0;
dev->device.common.module = const_cast<hw_module_t*>(module);
dev->device.common.close = gralloc_close;
dev->device.alloc = gralloc_alloc;
dev->device.free = gralloc_free;
*device = &dev->device.common;
status = 0;
} else {//打开fb设备
status = fb_device_open(module, name, device);
}
return status;
}
参数name指定了要打开的模块,Name为GRALLOC_HARDWARE_GPU0说明打开的是GPU,否则打开fb设备。
另一个方法gralloc_alloc 负责为上层分配缓冲区,注意这里的缓冲区既可以是内存缓冲区,也可以是fb的帧缓冲区。
//对外的分配缓冲区的方法
static int gralloc_alloc(alloc_device_t* dev,
int width, int height, int format, int usage,
buffer_handle_t* pHandle, int* pStride)
{
if (!pHandle || !pStride)
return -EINVAL;
int bytesPerPixel = 0;
switch (format) {//指定的缓冲区像素格式
case HAL_PIXEL_FORMAT_RGBA_FP16:
bytesPerPixel = 8;
break;
case HAL_PIXEL_FORMAT_RGBA_8888:
case HAL_PIXEL_FORMAT_RGBX_8888:
case HAL_PIXEL_FORMAT_BGRA_8888:
bytesPerPixel = 4;
break;
case HAL_PIXEL_FORMAT_RGB_888:
bytesPerPixel = 3;
break;
case HAL_PIXEL_FORMAT_RGB_565:
case HAL_PIXEL_FORMAT_RAW16:
bytesPerPixel = 2;
break;
default:
return -EINVAL;
}
const size_t tileWidth = 2;
const size_t tileHeight = 2;
size_t stride = align(width, tileWidth);
size_t size = align(height, tileHeight) * stride * bytesPerPixel + 4;
int err;
if (usage & GRALLOC_USAGE_HW_FB) {//在FB设备中分配帧缓冲区
err = gralloc_alloc_framebuffer(dev, size, usage, pHandle);
} else {//在内存中分配图形缓冲区
err = gralloc_alloc_buffer(dev, size, usage, pHandle);
}
if (err < 0) {
return err;
}
*pStride = stride;
return 0;
}
这分别是通过gralloc_alloc_buffer 和 gralloc_alloc_framebuffer来实现的。在内存中创建缓冲区是基于asheme的方式来创建一块匿名共享内存来作为缓冲区的,而如果是从fb中分配则只需要将fb的帧缓冲区映射到当前进程来即可。具体可以参见famebuffer.cpp中的mapFrameBufferLocked方法。
关于fb设备 其最重要的功能是将上层缓冲区的内容通过交换显示在屏幕上,这个功能是通过fb_post来实现的,在这之前我们看看如何打开fb设备
//打开fb设备 这个方法通过HAL层的Gralloc模块提供给上层接口
int fb_device_open(hw_module_t const* module, const char* name,
hw_device_t** device)
{
int status = -EINVAL;
if (!strcmp(name, GRALLOC_HARDWARE_FB0)) {//打开的是Fb设备
/* initialize our state here */
fb_context_t *dev = (fb_context_t*)malloc(sizeof(*dev));//分配fb_context_t 结构
memset(dev, 0, sizeof(*dev));
/* initialize the procs */
dev->device.common.tag = HARDWARE_DEVICE_TAG;
dev->device.common.version = 0;
dev->device.common.module = const_cast<hw_module_t*>(module);
dev->device.common.close = fb_close;
dev->device.setSwapInterval = fb_setSwapInterval;
dev->device.post = fb_post;//设置设备post回调接口,这个接口将缓冲区的内容显示在屏幕上
dev->device.setUpdateRect = 0;
private_module_t* m = (private_module_t*)module;
status = mapFrameBuffer(m);//对fb设备进行映射 其实是调用mapFrameBufferLocked
if (status >= 0) {
int stride = m->finfo.line_length / (m->info.bits_per_pixel >> 3);
int format = (m->info.bits_per_pixel == 32)
? (m->info.red.offset ? HAL_PIXEL_FORMAT_BGRA_8888 : HAL_PIXEL_FORMAT_RGBX_8888)
: HAL_PIXEL_FORMAT_RGB_565;
const_cast<uint32_t&>(dev->device.flags) = 0;
const_cast<uint32_t&>(dev->device.width) = m->info.xres;
const_cast<uint32_t&>(dev->device.height) = m->info.yres;
const_cast<int&>(dev->device.stride) = stride;
const_cast<int&>(dev->device.format) = format;
const_cast<float&>(dev->device.xdpi) = m->xdpi;
const_cast<float&>(dev->device.ydpi) = m->ydpi;
const_cast<float&>(dev->device.fps) = m->fps;
const_cast<int&>(dev->device.minSwapInterval) = 1;
const_cast<int&>(dev->device.maxSwapInterval) = 1;
*device = &dev->device.common;
}
}
return status;
}
//将缓冲区的内容显示在屏幕上
static int fb_post(struct framebuffer_device_t* dev, buffer_handle_t buffer)
{
if (private_handle_t::validate(buffer) < 0)
return -EINVAL;
fb_context_t* ctx = (fb_context_t*)dev;
private_handle_t const* hnd = reinterpret_cast<private_handle_t const*>(buffer);
private_module_t* m = reinterpret_cast<private_module_t*>(
dev->common.module);
if (hnd->flags & private_handle_t::PRIV_FLAGS_FRAMEBUFFER) { //如果缓冲区是来自于fb设备的帧缓冲区
const size_t offset = hnd->base - m->framebuffer->base;
m->info.activate = FB_ACTIVATE_VBL;
m->info.yoffset = offset / m->finfo.line_length;//直接调整y方向的分辨率偏移既可,不需要做任何拷贝
if (ioctl(m->framebuffer->fd, FBIOPUT_VSCREENINFO, &m->info) == -1) {//通过FBIOPUT_VSCREENINFO命令
ALOGE("FBIOPUT_VSCREENINFO failed"); //显示在屏幕上
m->base.unlock(&m->base, buffer);
return -errno;
}
m->currentBuffer = buffer;
} else { //否则是来自内存的缓冲区
// If we can't do the page_flip, just copy the buffer to the front
// FIXME: use copybit HAL instead of memcpy
void* fb_vaddr;
void* buffer_vaddr;
m->base.lock(&m->base, m->framebuffer,
GRALLOC_USAGE_SW_WRITE_RARELY,
0, 0, m->info.xres, m->info.yres,
&fb_vaddr);//对帧缓冲区加锁
m->base.lock(&m->base, buffer,
GRALLOC_USAGE_SW_READ_RARELY,
0, 0, m->info.xres, m->info.yres,
&buffer_vaddr);//对内存缓冲区加锁
memcpy(fb_vaddr, buffer_vaddr, m->finfo.line_length * m->info.yres);//需要将内存的缓冲区拷贝到fb的帧 缓冲中
m->base.unlock(&m->base, buffer);
m->base.unlock(&m->base, m->framebuffer);
}
return 0;
}
HAL层就到这儿,下一节为VSYNC信号
五、VSYNC信号的产生和处理
SurfaceFlinger(简称SF)的绘制合成过程是在VSYNC信号(即垂直同步信号)的控制下同步进行的,所以VSYNC信号可以说是SF的指挥官,它的协调同步控制对于界面绘制效率至关重要。本篇将介绍VYSNC信号在SF服务中是如何发挥这个指挥官的角色。
SufaceFlinger的初始化是在init方法中进行的,这个方法中关于VYSNC信号有两个DispSyncSource,分别为App绘制延时源和SF合成延时源,这两个信号源基于同一个VSYNC信号模型mPrimaryDispSync,它是一个DispSync对象,DispSync是对硬件Hwc垂直信号的同步模型,那么为什么在有硬件VSYNC信号的情况下还需要一个这样的同步模型呢?实际上,这个是Android系统的一种优化策略,因为在VYSNC信号到来后,App绘制和SF合成过程如果此时同时进行,可能会竞争CPU,从而会影响绘制效率,为了避免竞争引入了VYSNC同步模型DispSync,该模型会根据需要打开硬件的VYSNC信号进行采样,然后同步VSYNC信号模型,从而为上层的绘制延时源和合成延时源提供VYSNC信号,基于该同步模型,绘制延时源和合成延时源可以分别在此基础上添加一个相位偏移量(vsyncPhaseOffsetNs和sfVsyncPhaseOffsetNs),以此错开绘制和合成在VYSNC信号到来后的执行。
void SurfaceFlinger::init() {
...
//创建合成对象HWComposer,这里会打开fb和hwc硬件设备,HWComposer代表的不一定就是实际的底层硬件设备
mHwc = new HWComposer(this,
*static_cast<HWComposer::EventHandler *>(this));
……
// start the EventThread
sp<VSyncSource> vsyncSrc = new DispSyncSource(&mPrimaryDispSync,
vsyncPhaseOffsetNs, true);//App绘制延时 绘制垂直同步源
mEventThread = new EventThread(vsyncSrc);//这个EventThread负责管理绘制的Vsync同步源
sp<VSyncSource> sfVsyncSrc = new DispSyncSource(&mPrimaryDispSync,
sfVsyncPhaseOffsetNs, false);//SF合成延时 由于延时的不同,渲染和合成在收到真正的VSync信号之后错开执行。
mSFEventThread = new EventThread(sfVsyncSrc);//这个EventThread负责管理合成的Vsync同步源
mEventQueue.setEventThread(mSFEventThread);//这里会建立一个EventConnection,实际上就是注册成为了一个监听者,这样当有vsync信号时可以通知给MessageQueue
……
//给HWC硬件发送消息,用来控制打开关闭Vsync信号
mEventControlThread = new EventControlThread(this);
mEventControlThread->run("EventControl", PRIORITY_URGENT_DISPLAY);
……
// set initial conditions (e.g. unblank default device)
initializeDisplays();//初始化显示器,这里会重新打开Vsync信号,默认它在EventControlThread中设置是关闭的。
...
}
1、硬件VSYNC信号的产生
VSYNC是由硬件设备产生,通过HAL层的HWComposer将硬件的VSYNC信号发送给SF
//frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp
HWComposer::HWComposer(
const sp<SurfaceFlinger>& flinger,
EventHandler& handler)
: mFlinger(flinger),
mFbDev(0), mHwc(0), mNumDisplays(1),
mCBContext(new cb_context),
mEventHandler(handler),
mDebugForceFakeVSync(false)
{
...
int fberr = loadFbHalModule();//打开fb设备
loadHwcModule();//打开hwc模块
if (mHwc) {//支持硬件合成
if (mHwc->registerProcs) {
mCBContext->hwc = this;
mCBContext->procs.invalidate = &hook_invalidate;
mCBContext->procs.vsync = &hook_vsync;//硬件垂直信号的回调
if (hwcHasApiVersion(mHwc, HWC_DEVICE_API_VERSION_1_1))//1.1版本支持热插拔
mCBContext->procs.hotplug = &hook_hotplug;
else
mCBContext->procs.hotplug = NULL;
memset(mCBContext->procs.zero, 0, sizeof(mCBContext->procs.zero));
mHwc->registerProcs(mHwc, &mCBContext->procs);//注册回调
}
// don't need a vsync thread if we have a hardware composer
needVSyncThread = false;//支持硬件合成的话就不需要软件进行模拟了
// always turn vsync off when we start
//先关闭VSYNC,后面会重新打开
eventControl(HWC_DISPLAY_PRIMARY, HWC_EVENT_VSYNC, 0);
……
}
if (mFbDev) {//fb设备已经打开
DisplayData& disp(mDisplayData[HWC_DISPLAY_PRIMARY]);
disp.connected = true;
//设置主屏幕的参数,包括显示参数包括宽度、高度,像素格式以及刷新频率
disp.width = mFbDev->width;
disp.height = mFbDev->height;
disp.format = mFbDev->format;
disp.xdpi = mFbDev->xdpi;
disp.ydpi = mFbDev->ydpi;
if (disp.refresh == 0) {
disp.refresh = nsecs_t(1e9 / mFbDev->fps);
}
if (disp.refresh == 0) {
disp.refresh = nsecs_t(1e9 / 60.0);
}
}
//需要通过软件模拟Vsync信号
if (needVSyncThread) {
// we don't have VSYNC support, we need to fake it
mVSyncThread = new VSyncThread(*this);
}
}
HWComposer对象负责SF的硬件合成,理所当然VSYNC信号也应该由其提供,在其构造方法中,会加载hwc设备模块,并将VSYNC信号的回调hook_vsync注册到hwc设备中这样硬件产生的VSYNC信号就可以回调给HWCoposer对象的hook_vsync。需要注意的是HWComposer并不一定就是底层存在的硬件设备,它也可以代表一个虚拟设备,这样VSYNC信号就是通过一个VSyncThread线程模拟硬件产生的。
//通知HWComposer垂直事件到达
void HWComposer::hook_vsync(const struct hwc_procs* procs, int disp,
int64_t timestamp) {
cb_context* ctx = reinterpret_cast<cb_context*>(
const_cast<hwc_procs_t*>(procs));
ctx->hwc->vsync(disp, timestamp);
}
//VSYNC事件到达
void HWComposer::vsync(int disp, int64_t timestamp) {
if (uint32_t(disp) < HWC_NUM_PHYSICAL_DISPLAY_TYPES) {
{
Mutex::Autolock _l(mLock);
// There have been reports of HWCs that signal several vsync events
// with the same timestamp when turning the display off and on. This
// is a bug in the HWC implementation, but filter the extra events
// out here so they don't cause havoc downstream.
if (timestamp == mLastHwVSync[disp]) {
ALOGW("Ignoring duplicate VSYNC event from HWC (t=%lld)",
timestamp);
return;
}
mLastHwVSync[disp] = timestamp;
}
……
mEventHandler.onVSyncReceived(disp, timestamp);//sf回调 将vsync消息通告给sf
}
}
在hook_vsync方法中进一步调用HWComposer的vsync方法通知VSYNC信号事件,在vsync方法中,最终是通过EventHandler的onVsyncReceived方法通知给SF的,这个EventHandler是在构造HWComposer时由SF提供的,实际上SF本身就是继承自HWComposer::EventHandler,而HWComposer::EventHandler的定义如下:
class HWComposer
{
public:
class EventHandler {
friend class HWComposer;
virtual void onVSyncReceived(int disp, nsecs_t timestamp) = 0;//vynsc消息回调
virtual void onHotplugReceived(int disp, bool connected) = 0;
protected:
virtual ~EventHandler() {}
};
}
六、源码分析
SurfaceFlinger,合成抛射机,它在Android系统是一个独立的服务进程
它的作用是接受多个来源的图形显示数据,将他们合成,然后发送到显示设备。
它的工作内容主要包括合成的创建和管理、Vsync信号的处理
1、启动流程
SurfaceFlinger 进程是由 init 进程创建的,运行在独立的 SurfaceFlinger 进程中。init 进程读取 init.rc 文件启动 SurfaceFlinger。首先来看main方法
(1)、main方法
- 设定线程池上线4,并启动binder线程池
- 创建SF对象
- 初始化SF
- 执行SF的run方法
/surfaceflinger/main_surfaceflinger.cpp
int main(int, char**) {
//设定surfaceflinger进程的binder线程池个数上限为4,并启动binder线程池
ProcessState::self()->setThreadPoolMaxThreadCount(4);
sp<ProcessState> ps(ProcessState::self());
ps->startThreadPool();
//实例化surfaceflinger
sp<SurfaceFlinger> flinger = DisplayUtils::getInstance()->getSFInstance();
setpriority(PRIO_PROCESS, 0, PRIORITY_URGENT_DISPLAY);
set_sched_policy(0, SP_FOREGROUND);
//初始化
flinger->init();
//将服务注册到Service Manager
sp<IServiceManager> sm(defaultServiceManager());
sm->addService(String16(SurfaceFlinger::getServiceName()), flinger, false);
// 运行在当前线程
flinger->run();
return 0;
}
2、构造方法
继承BnSurfaceCompose
构造过程仅仅初始化了SurfaceFlinger的成员变量,同时调用了父类BnSurfaceComposer的构造函数。最后执行onFirstRef 走init方法来作一些初始化工作
/framewoek/native/services/surfaceflinger/SurfaceFlinger.cpp
SurfaceFlinger::SurfaceFlinger()
: BnSurfaceComposer(),
mTransactionFlags(0),
mTransactionPending(false),
mAnimTransactionPending(false),
mLayersRemoved(false),
mRepaintEverything(0),
mRenderEngine(NULL),
mBootTime(systemTime()),
mVisibleRegionsDirty(false),
mHwWorkListDirty(false),
mAnimCompositionPending(false),
mDebugRegion(0),
mDebugDDMS(0),
mDebugDisableHWC(0),
mDebugDisableTransformHint(0),
mDebugInSwapBuffers(0),
mLastSwapBufferTime(0),
mDebugInTransaction(0),
mLastTransactionTime(0),
mBootFinished(false),
mForceFullDamage(false),
mPrimaryHWVsyncEnabled(false),
mHWVsyncAvailable(false),
mDaltonize(false),
mHasColorMatrix(false),
mHasPoweredOff(false),
mFrameBuckets(),
mTotalTime(0),
mLastSwapTime(0)
{
ALOGI("SurfaceFlinger is starting");
char value[PROPERTY_VALUE_MAX];
property_get("ro.bq.gpu_to_cpu_unsupported", value, "0");
mGpuToCpuSupported = !atoi(value);
property_get("debug.sf.showupdates", value, "0");
mDebugRegion = atoi(value);
property_get("debug.sf.ddms", value, "0");
mDebugDDMS = atoi(value);
}
SF.onFirstRef
由于SurfaceFlinger继承于RefBase类,同时实现了RefBase的onFirstRef()方法,因此在第一次引用SurfaceFlinger对象时,onFirstRef()函数自动被调用。onFirstRef() 中会创建 Handler 并初始化: /frameworks/native/services/surfaceflinger/Scheduler/MessageQueue.cpp初始化MessageQueu
/framewoek/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::onFirstRef()
{
mEventQueue.init(this);
}
messageQueue对象的创建
void MessageQueue::init(const sp<SurfaceFlinger>& flinger)
{
mFlinger = flinger;
mLooper = new Looper(true);
mHandler = new Handler(*this);
}
class MessageQueue {
class Handler : public MessageHandler {
enum {
eventMaskInvalidate = 0x1,
eventMaskRefresh = 0x2,
eventMaskTransaction = 0x4
};
MessageQueue& mQueue;
int32_t mEventMask;
public:
Handler(MessageQueue& queue) : mQueue(queue), mEventMask(0) { }
virtual void handleMessage(const Message& message);
void dispatchRefresh();
void dispatchInvalidate();
void dispatchTransaction();
};
...
}
SurfaceFlinger.init
- 初始化 EGL
- 创建 HWComposer
- 初始化非虚拟显示屏
- 启动 EventThread 线程
- 启动开机动画
注:EGL 是渲染 API(如 OpenGL ES)和原生窗口系统之间的接口。
通常来说,OpenGL 是一个操作 GPU 的 API,它通过驱动向 GPU 发送相关指令,控制图形渲染管线状态机的运行状态,但是当涉及到与本地窗口系统进行交互时,就需要这么一个中间层,且它最好是与平台无关的。
因此 EGL 被设计出来,作为 OpenGL 和原生窗口系统之间的桥梁
/framewoek/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::init() {
Mutex::Autolock _l(mStateLock);
//初始化EGL,作为默认的显示
mEGLDisplay = eglGetDisplay(EGL_DEFAULT_DISPLAY);
eglInitialize(mEGLDisplay, NULL, NULL);
// 初始化硬件composer对象
mHwc = new HWComposer(this, *static_cast<HWComposer::EventHandler *>(this));
//获取RenderEngine引擎
mRenderEngine = RenderEngine::create(mEGLDisplay, mHwc->getVisualID());
//创建的EGL上下文
mEGLContext = mRenderEngine->getEGLContext();
//初始化非虚拟显示屏
for (size_t i=0 ; i<DisplayDevice::NUM_BUILTIN_DISPLAY_TYPES ; i++) {
DisplayDevice::DisplayType type((DisplayDevice::DisplayType)i);
//建立已连接的显示设备
if (mHwc->isConnected(i) || type==DisplayDevice::DISPLAY_PRIMARY) {
bool isSecure = true;
createBuiltinDisplayLocked(type);
wp<IBinder> token = mBuiltinDisplays[i];
sp<IGraphicBufferProducer> producer;
sp<IGraphicBufferConsumer> consumer;
//创建BufferQueue的生产者和消费者
BufferQueue::createBufferQueue(&producer, &consumer,
new GraphicBufferAlloc());
sp<FramebufferSurface> fbs = new FramebufferSurface(*mHwc, i, consumer);
int32_t hwcId = allocateHwcDisplayId(type);
//创建显示设备
sp<DisplayDevice> hw = new DisplayDevice(this,
type, hwcId, mHwc->getFormat(hwcId), isSecure, token,
fbs, producer,
mRenderEngine->getEGLConfig());
if (i > DisplayDevice::DISPLAY_PRIMARY) {
hw->setPowerMode(HWC_POWER_MODE_NORMAL);
}
mDisplays.add(token, hw);
}
}
getDefaultDisplayDevice()->makeCurrent(mEGLDisplay, mEGLContext);
//当应用和sf的vsync偏移量一致时,则只创建一个EventThread线程
if (vsyncPhaseOffsetNs != sfVsyncPhaseOffsetNs) {
sp<VSyncSource> vsyncSrc = new DispSyncSource(&mPrimaryDispSync,
vsyncPhaseOffsetNs, true, "app");
mEventThread = new EventThread(vsyncSrc);
sp<VSyncSource> sfVsyncSrc = new DispSyncSource(&mPrimaryDispSync,
sfVsyncPhaseOffsetNs, true, "sf");
mSFEventThread = new EventThread(sfVsyncSrc);
mEventQueue.setEventThread(mSFEventThread);
} else {
//创建DispSyncSource对象
sp<VSyncSource> vsyncSrc = new DispSyncSource(&mPrimaryDispSync,
vsyncPhaseOffsetNs, true, "sf-app");
//创建线程EventThread
mEventThread = new EventThread(vsyncSrc);
//设置EventThread
mEventQueue.setEventThread(mEventThread);
}
// 创建EventControl
mEventControlThread = new EventControlThread(this);
mEventControlThread->run("EventControl", PRIORITY_URGENT_DISPLAY);
//当不存在HWComposer时,则设置软件vsync
if (mHwc->initCheck() != NO_ERROR) {
mPrimaryDispSync.setPeriod(16666667);
}
//初始化绘图状态
mDrawingState = mCurrentState;
//初始化显示设备
initializeDisplays();
//启动开机动画
startBootAnim();
}
HWComposer构建
HWComposer代表着硬件显示设备,注册了VSYNC信号的回调。VSYNC信号本身是由显示驱动产生的, 在不支持硬件的VSYNC,则会创建“VSyncThread”线程来模拟定时VSYNC信号
HWComposer::HWComposer(
const sp<SurfaceFlinger>& flinger,
EventHandler& handler)
: mFlinger(flinger),
mFbDev(0), mHwc(0), mNumDisplays(1),
mCBContext(new cb_context),
mEventHandler(handler),
mDebugForceFakeVSync(false)
{
...
bool needVSyncThread = true;
int fberr = loadFbHalModule(); //加载framebuffer的HAL层模块
loadHwcModule(); //加载HWComposer模块
//标记已分配的display ID
for (size_t i=0 ; i<NUM_BUILTIN_DISPLAYS ; i++) {
mAllocatedDisplayIDs.markBit(i);
}
if (mHwc) {
if (mHwc->registerProcs) {
mCBContext->hwc = this;
mCBContext->procs.invalidate = &hook_invalidate;
//VSYNC信号的回调方法
mCBContext->procs.vsync = &hook_vsync;
if (hwcHasApiVersion(mHwc, HWC_DEVICE_API_VERSION_1_1))
mCBContext->procs.hotplug = &hook_hotplug;
else
mCBContext->procs.hotplug = NULL;
memset(mCBContext->procs.zero, 0, sizeof(mCBContext->procs.zero));
//注册回调函数
mHwc->registerProcs(mHwc, &mCBContext->procs);
}
//进入此处,说明已成功打开硬件composer设备,则不再需要vsync线程
needVSyncThread = false;
eventControl(HWC_DISPLAY_PRIMARY, HWC_EVENT_VSYNC, 0);
...
}
...
if (needVSyncThread) {
//不支持硬件的VSYNC,则会创建线程来模拟定时VSYNC信号
mVSyncThread = new VSyncThread(*this);
}
}
初始化显示设备
创建IGraphicBufferProducer和IGraphicBufferConsumer,以及FramebufferSurface,DisplayDevice对象。另外, 显示设备有3类:主设备,扩展设备,虚拟设备。其中前两个都是内置显示设备,故NUM_BUILTIN_DISPLAY_TYPES=2,
void SurfaceFlinger::init() {
...
for (size_t i=0 ; i<DisplayDevice::NUM_BUILTIN_DISPLAY_TYPES ; i++) {
DisplayDevice::DisplayType type((DisplayDevice::DisplayType)i);
//建立已连接的显示设备
if (mHwc->isConnected(i) || type==DisplayDevice::DISPLAY_PRIMARY) {
bool isSecure = true;
createBuiltinDisplayLocked(type);
wp<IBinder> token = mBuiltinDisplays[i];
sp<IGraphicBufferProducer> producer;
sp<IGraphicBufferConsumer> consumer;
//创建BufferQueue的生产者和消费者
BufferQueue::createBufferQueue(&producer, &consumer,
new GraphicBufferAlloc());
sp<FramebufferSurface> fbs = new FramebufferSurface(*mHwc, i, consumer);
int32_t hwcId = allocateHwcDisplayId(type);
//创建显示设备
sp<DisplayDevice> hw = new DisplayDevice(this,
type, hwcId, mHwc->getFormat(hwcId), isSecure, token,
fbs, producer,
mRenderEngine->getEGLConfig());
if (i > DisplayDevice::DISPLAY_PRIMARY) {
hw->setPowerMode(HWC_POWER_MODE_NORMAL);
}
mDisplays.add(token, hw);
}
}
...
}
EventThread构造方法
EventThread::EventThread(const sp<VSyncSource>& src)
: mVSyncSource(src),
mUseSoftwareVSync(false),
mVsyncEnabled(false),
mDebugVsyncEnabled(false),
mVsyncHintSent(false) {
for (int32_t i=0 ; i<DisplayDevice::NUM_BUILTIN_DISPLAY_TYPES ; i++) {
mVSyncEvent[i].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
mVSyncEvent[i].header.id = 0;
mVSyncEvent[i].header.timestamp = 0;
mVSyncEvent[i].vsync.count = 0;
}
struct sigevent se;
se.sigev_notify = SIGEV_THREAD;
se.sigev_value.sival_ptr = this;
se.sigev_notify_function = vsyncOffCallback;
se.sigev_notify_attributes = NULL;
timer_create(CLOCK_MONOTONIC, &se, &mTimerId);
}
void EventThread::onFirstRef() {
//运行EventThread线程
run("EventThread", PRIORITY_URGENT_DISPLAY + PRIORITY_MORE_FAVORABLE);
}
ET.threadLoop
bool EventThread::threadLoop() {
DisplayEventReceiver::Event event;
Vector< sp<EventThread::Connection> > signalConnections;
// 等待事件
signalConnections = waitForEvent(&event);
//分发事件给所有的监听者
const size_t count = signalConnections.size();
for (size_t i=0 ; i<count ; i++) {
const sp<Connection>& conn(signalConnections[i]);
//传递事件
status_t err = conn->postEvent(event);
if (err == -EAGAIN || err == -EWOULDBLOCK) {
//可能此时connection已满,则直接抛弃事件
ALOGW("EventThread: dropping event (%08x) for connection %p",
event.header.type, conn.get());
} else if (err < 0) {
//发生致命错误,则清理该连接
removeDisplayEventConnection(signalConnections[i]);
}
}
return true;
}
ET.waitForEvent
EventThread线程,进入mCondition的wait()方法,等待唤醒
Vector< sp<EventThread::Connection> > EventThread::waitForEvent(
DisplayEventReceiver::Event* event)
{
Mutex::Autolock _l(mLock);
Vector< sp<EventThread::Connection> > signalConnections;
do {
bool eventPending = false;
bool waitForVSync = false;
size_t vsyncCount = 0;
nsecs_t timestamp = 0;
for (int32_t i=0 ; i<DisplayDevice::NUM_BUILTIN_DISPLAY_TYPES ; i++) {
timestamp = mVSyncEvent[i].header.timestamp;
if (timestamp) {
*event = mVSyncEvent[i];
mVSyncEvent[i].header.timestamp = 0;
vsyncCount = mVSyncEvent[i].vsync.count;
break;
}
}
if (!timestamp) {
//没有vsync事件,则查看其它事件
eventPending = !mPendingEvents.isEmpty();
if (eventPending) {
//存在其它事件可用于分发
*event = mPendingEvents[0];
mPendingEvents.removeAt(0);
}
}
//查找正在等待事件的连接
size_t count = mDisplayEventConnections.size();
for (size_t i=0 ; i<count ; i++) {
sp<Connection> connection(mDisplayEventConnections[i].promote());
if (connection != NULL) {
bool added = false;
if (connection->count >= 0) {
//需要vsync事件,由于至少存在一个连接正在等待vsync
waitForVSync = true;
if (timestamp) {
if (connection->count == 0) {
connection->count = -1;
signalConnections.add(connection);
added = true;
} else if (connection->count == 1 ||
(vsyncCount % connection->count) == 0) {
signalConnections.add(connection);
added = true;
}
}
}
if (eventPending && !timestamp && !added) {
//没有vsync事件需要处理(timestamp==0),但存在pending消息
signalConnections.add(connection);
}
} else {
//该连接已死亡,则直接清理
mDisplayEventConnections.removeAt(i);
--i; --count;
}
}
if (timestamp && !waitForVSync) {
//接收到VSYNC,但没有client需要它,则直接关闭VSYNC
disableVSyncLocked();
} else if (!timestamp && waitForVSync) {
//至少存在一个client,则需要使能VSYNC
enableVSyncLocked();
}
if (!timestamp && !eventPending) {
if (waitForVSync) {
bool softwareSync = mUseSoftwareVSync;
nsecs_t timeout = softwareSync ? ms2ns(16) : ms2ns(1000);
if (mCondition.waitRelative(mLock, timeout) == TIMED_OUT) {
mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
mVSyncEvent[0].header.id = DisplayDevice::DISPLAY_PRIMARY;
mVSyncEvent[0].header.timestamp = systemTime(SYSTEM_TIME_MONOTONIC);
mVSyncEvent[0].vsync.count++;
}
} else {
//不存在对vsync感兴趣的连接,即将要进入休眠
mCondition.wait(mLock);
}
}
} while (signalConnections.isEmpty());
//到此处,则保证存在timestamp以及连接
return signalConnections;
}
MQ.setEvenetThread
设置EventThread,并监听BitTube
创建一个BitTube对象mEventTube
创建一个EventConnection
void MessageQueue::setEventThread(const sp<EventThread>& eventThread)
{
mEventThread = eventThread;
//创建连接
mEvents = eventThread->createEventConnection();
//获取BitTube对象
mEventTube = mEvents->getDataChannel();
//监听BitTube,一旦有数据到来则调用cb_eventReceiver()
mLooper->addFd(mEventTube->getFd(), 0, Looper::EVENT_INPUT,
MessageQueue::cb_eventReceiver, this);
}
SF.run
主线程进入waitMessage状态
void SurfaceFlinger::run() {
do {
//不断循环地等待事件
waitForEvent();
} while (true);
}
void SurfaceFlinger::waitForEvent() {
mEventQueue.waitMessage();
}
void MessageQueue::waitMessage() {
do {
IPCThreadState::self()->flushCommands();
int32_t ret = mLooper->pollOnce(-1);
...
} while (true);
}
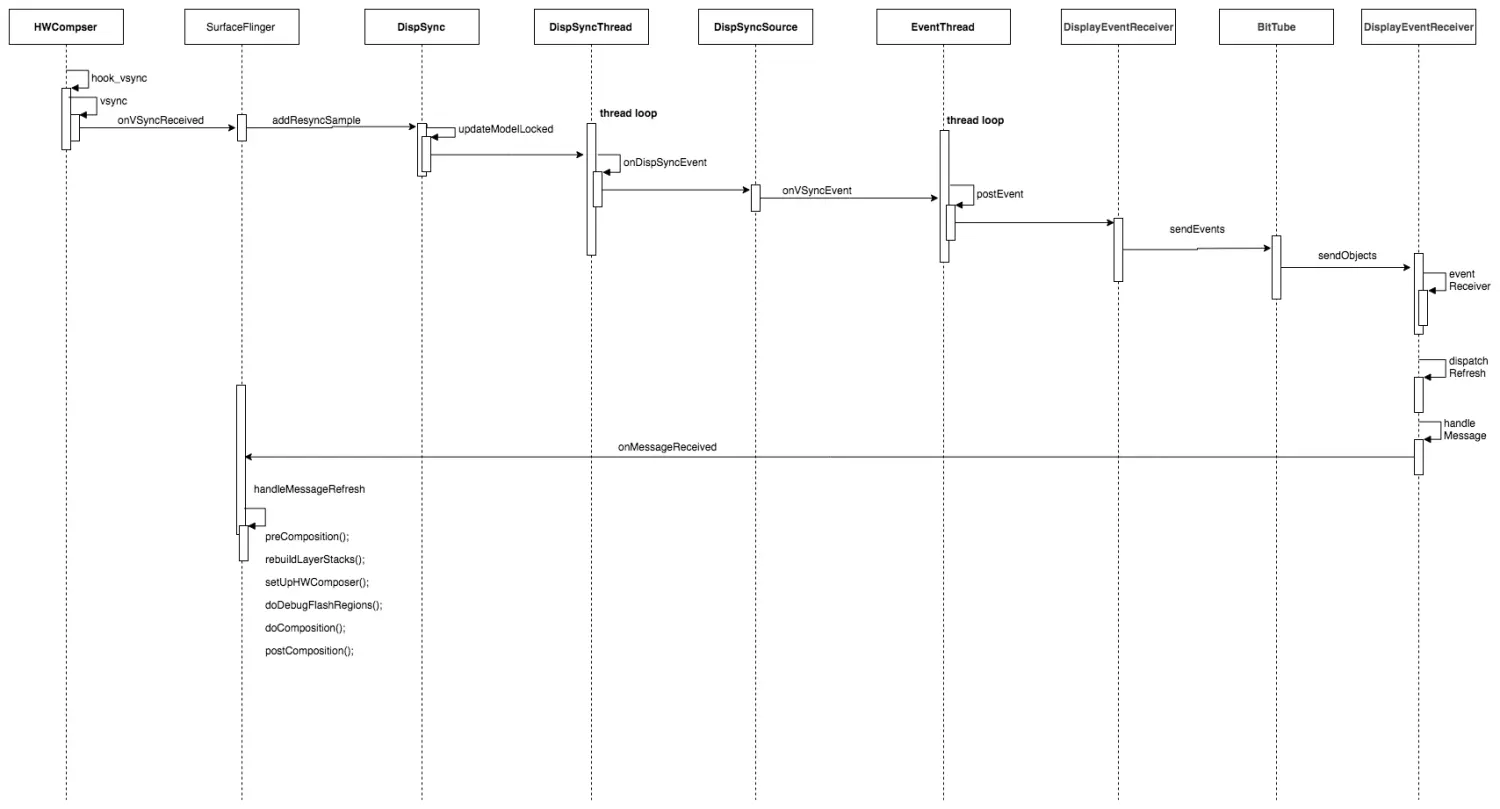
Vsync信号处理
HWComposer对象创建过程,会注册一些回调方法,当硬件产生VSYNC信号时,则会回调hook_vsync()方法。
HWComposer.hook_vsync
hook 监听Vysnc
void HWComposer::hook_vsync(const struct hwc_procs* procs, int disp,
int64_t timestamp) {
cb_context* ctx = reinterpret_cast<cb_context*>(
const_cast<hwc_procs_t*>(procs));
ctx->hwc->vsync(disp, timestamp); 】
}
HWComposer.vsync
Vsync信号回调,执行SF的onVSyncReceived方法
void HWComposer::vsync(int disp, int64_t timestamp) {
if (uint32_t(disp) < HWC_NUM_PHYSICAL_DISPLAY_TYPES) {
{
Mutex::Autolock _l(mLock);
if (timestamp == mLastHwVSync[disp]) {
return; //忽略重复的VSYNC信号
}
mLastHwVSync[disp] = timestamp;
}
//
mEventHandler.onVSyncReceived(disp, timestamp);
}
}
SF.onVSyncReceived
void SurfaceFlinger::onVSyncReceived(int type, nsecs_t timestamp) {
bool needsHwVsync = false;
{
Mutex::Autolock _l(mHWVsyncLock);
if (type == 0 && mPrimaryHWVsyncEnabled) {
// 此处mPrimaryDispSync为DispSync类 kai是分析DispSync
needsHwVsync = mPrimaryDispSync.addResyncSample(timestamp);
}
}
if (needsHwVsync) {
enableHardwareVsync();
} else {
disableHardwareVsync(false);
}
}
DispSync构建
DispSync::DispSync() :
mRefreshSkipCount(0),
mThread(new DispSyncThread()) {
// 运行在DispSync线程
mThread->run("DispSync", PRIORITY_URGENT_DISPLAY + PRIORITY_MORE_FAVORABLE);
reset();
beginResync();
...
}
DispSyncThread线程
线程”DispSync”停留在mCond的wait()过程,等待被唤醒
当收集到Vsync信号后开始回调onDispSyncEvent方法
virtual bool threadLoop() {
status_t err;
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
nsecs_t nextEventTime = 0;
while (true) {
Vector<CallbackInvocation> callbackInvocations;
nsecs_t targetTime = 0;
{ // Scope for lock
Mutex::Autolock lock(mMutex);
if (mStop) {
return false;
}
if (mPeriod == 0) {
err = mCond.wait(mMutex);
continue;
}
nextEventTime = computeNextEventTimeLocked(now);
targetTime = nextEventTime;
bool isWakeup = false;
if (now < targetTime) {
err = mCond.waitRelative(mMutex, targetTime - now);
if (err == TIMED_OUT) {
isWakeup = true;
} else if (err != NO_ERROR) {
return false;
}
}
now = systemTime(SYSTEM_TIME_MONOTONIC);
if (isWakeup) {
mWakeupLatency = ((mWakeupLatency * 63) +
(now - targetTime)) / 64;
if (mWakeupLatency > 500000) {
mWakeupLatency = 500000;
}
}
//收集vsync信号的所有回调方法
callbackInvocations = gatherCallbackInvocationsLocked(now);
}
if (callbackInvocations.size() > 0) {
//回调所有对象的onDispSyncEvent方法
fireCallbackInvocations(callbackInvocations);
}
}
return false;
}
void fireCallbackInvocations(const Vector<CallbackInvocation>& callbacks) {
for (size_t i = 0; i < callbacks.size(); i++) {
//执行DSP 的接受方法
callbacks[i].mCallback->onDispSyncEvent(callbacks[i].mEventTime);
}
}
DispSyncSource.onDispSyncEvent
virtual void onDispSyncEvent(nsecs_t when) {
sp<VSyncSource::Callback> callback;
{
Mutex::Autolock lock(mCallbackMutex);
callback = mCallback;
}
if (callback != NULL) {
// 执行 EventThread接受Vsync方法
callback->onVSyncEvent(when);
}
}
EventThread.onVsyncEvent
void EventThread::onVSyncEvent(nsecs_t timestamp) {
Mutex::Autolock _l(mLock);
mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
mVSyncEvent[0].header.id = 0;
mVSyncEvent[0].header.timestamp = timestamp;
mVSyncEvent[0].vsync.count++;
mCondition.broadcast(); //唤醒EventThread线程
}
EventThread.postEvent
status_t EventThread::Connection::postEvent(
const DisplayEventReceiver::Event& event) {
ssize_t size = DisplayEventReceiver::sendEvents(mChannel, &event, 1);
return size < 0 ? status_t(size) : status_t(NO_ERROR);
}
DisplayEventReceiver.sendEvents
MQ.setEvenetThread监听BitTube,此处调用BitTube来sendObjects。一旦收到数据,则调用MQ.cb_eventReceiver()方法
ssize_t DisplayEventReceiver::sendEvents(const sp<BitTube>& dataChannel,
Event const* events, size_t count)
{
return BitTube::sendObjects(dataChannel, events, count);
}
MQ.cb_eventReceiver
int MessageQueue::cb_eventReceiver(int fd, int events, void* data) {
MessageQueue* queue = reinterpret_cast<MessageQueue *>(data);
return queue->eventReceiver(fd, events);
}
MQ.eventReceiver
接受事件,分发dispatchInvalidate、dispatchRefresh
消息接收,执行SF的onMessageReceived
int MessageQueue::eventReceiver(int /*fd*/, int /*events*/) {
ssize_t n;
DisplayEventReceiver::Event buffer[8];
while ((n = DisplayEventReceiver::getEvents(mEventTube, buffer, 8)) > 0) {
for (int i=0 ; i<n ; i++) {
if (buffer[i].header.type == DisplayEventReceiver::DISPLAY_EVENT_VSYNC) {
#if INVALIDATE_ON_VSYNC
mHandler->dispatchInvalidate();
#else
mHandler->dispatchRefresh();
#endif
break;
}
}
}
return 1;
}
// 发送refresh
void MessageQueue::Handler::dispatchRefresh() {
if ((android_atomic_or(eventMaskRefresh, &mEventMask) & eventMaskRefresh) == 0) {
//发送消息,则进入handleMessage过程【
mQueue.mLooper->sendMessage(this, Message(MessageQueue::REFRESH));
}
}
// MQ的消息接受处理
void MessageQueue::Handler::handleMessage(const Message& message) {
switch (message.what) {
case INVALIDATE:
android_atomic_and(~eventMaskInvalidate, &mEventMask);
mQueue.mFlinger->onMessageReceived(message.what);
break;
case REFRESH:
android_atomic_and(~eventMaskRefresh, &mEventMask);
mQueue.mFlinger->onMessageReceived(message.what);
break;
case TRANSACTION:
android_atomic_and(~eventMaskTransaction, &mEventMask);
mQueue.mFlinger->onMessageReceived(message.what);
break;
}
}
SF.onMessageReceived
void SurfaceFlinger::onMessageReceived(int32_t what) {
ATRACE_CALL();
switch (what) {
case MessageQueue::TRANSACTION: {
handleMessageTransaction();
break;
}
case MessageQueue::INVALIDATE: {
bool refreshNeeded = handleMessageTransaction();
refreshNeeded |= handleMessageInvalidate();
refreshNeeded |= mRepaintEverything;
if (refreshNeeded) {
signalRefresh();
}
break;
}
case MessageQueue::REFRESH: {
handleMessageRefresh(); // 执行refresh流程
break;
}
}
}
SF.handleMessageRefresh
void SurfaceFlinger::handleMessageRefresh() {
ATRACE_CALL();
// 处理显示设备与 layers 的改变
preComposition();
// 重建所有layer,根据z轴排序
rebuildLayerStacks();
// 更新 HWComposer涂层
setUpHWComposer();
doDebugFlashRegions();
// 生成OpenGL 纹理图像
doComposition();
// 将图像传递到物理屏幕
postComposition();
}
end



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









