




特征选择(Feature Selection)
特征选择是选择对模型训练最重要的特征,去除冗余或不相关特征,从而提高模型的性能和训练速度,并减少过拟合。
原理
特征选择通过减少数据维度,去除冗余或不相关特征,可以提高模型的性能和训练速度,并减少过拟合。常用的方法包括基于统计量的方法(如方差选择、相关系数选择)、基于模型的方法(如基于树模型的特征重要性度量)、和基于嵌入的方法(如正则化模型中的L1正则化)。
核心公式
可以使用基于树模型的特征重要性度量,如在随机森林中计算特征重要性:
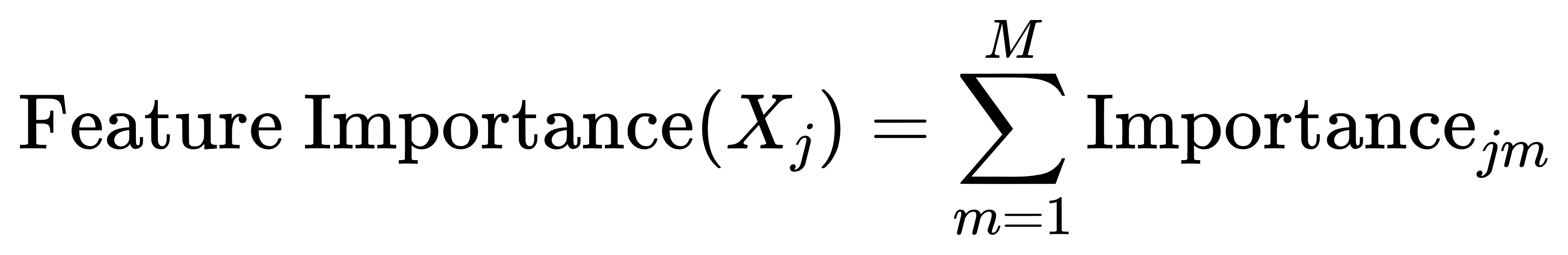
其中,Importancejm 是第 m 棵树中特征 Xj 的重要性度量。
假设使用基于Gini系数的特征重要性计算方法,单棵树的特征重要性可以表示为:
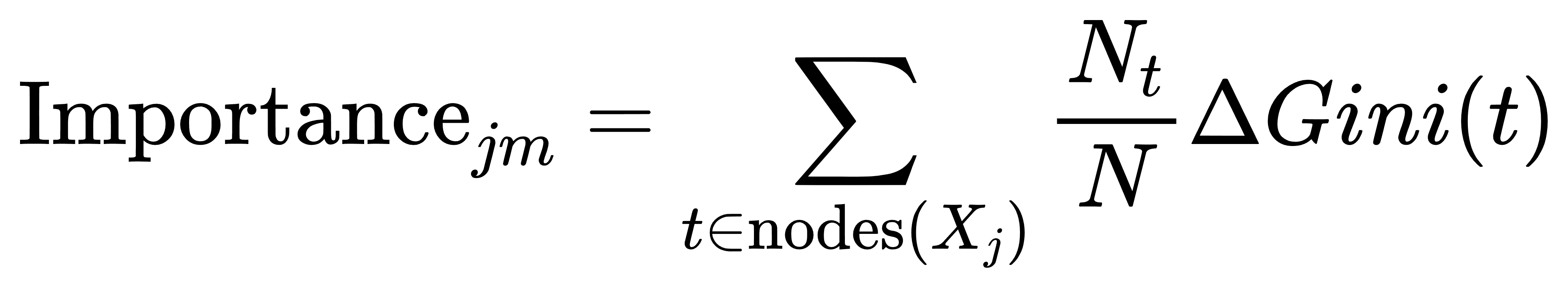
其中,nodes(Xj) 是所有包含特征 Xj的节点, Nt 是节点 t 的样本数量, N 是总样本数量, ΔGini(t) 是节点 t 上的Gini系数变化。
案例
数据集说明
假设我们有一个包含以下特征的数据集:
- 饮食习惯:
Diet(类别特征,如“健康饮食”、“普通饮食”、“不健康饮食”) - 每周运动频率:
ExerciseFrequency(数值特征,单位:次/周) - 平均睡眠时间:
SleepHours(数值特征,单位:小时/天) - 血压:
BloodPressure(数值特征,单位:mmHg) - 体重:
Weight(数值特征,单位:kg) - 心率:
HeartRate(数值特征,单位:次/分钟)
我们的目标是找出哪些特征对预测健康状况(HealthStatus,如“健康”或“不健康”)最重要。
代码实现
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import Standard 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4563
4563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









