 正则表达式入门
正则表达式入门





 本文详细介绍了正则表达式的基本概念、用途及基础语法,包括元字符、字符集、重复字符等,通过实例演示如何使用grep命令进行文本匹配。
本文详细介绍了正则表达式的基本概念、用途及基础语法,包括元字符、字符集、重复字符等,通过实例演示如何使用grep命令进行文本匹配。
一、正则表达式的定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为 regex、regexp 或 RE。
1.正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说, 是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
2.正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。其中普通字符包括大小写字母、数字、标点符号及一些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
3.正则表达式一般用于脚本编程与文本编辑器中。很多文本处理器与程序设计语言均支持正则表达式,如前面提到的 Perl、Linux 系统中常见的文本处理器(grep、egrep、sed、awk)。正则表达式具备很强大的文本匹配功能,能够在文本海洋中快速高效地处理文本。
二、正则表达式用途
1.快速提取
正则表达式对于系统管理员来说是非常重要的,系统运行过程中会产生大量的信息,这些信息有些是非常重要的,有些则仅是告知的信息。身为系统管理员如果直接看这么多的信息数据,无法快速定位到重要的信息,如“用户账号登录失败”“服务启动失败”等信息。这时可以通过正则表达式快速提取“有问题”的信息。如此一来,可以将运维工作变得更加简单、方便。
2.邮件服务器(用途)
在 Internet 中,垃圾/广告邮件经常会造成网络塞车,如果在服务器端就将这些问题邮件提前剔除的话,客户端就会减少很多不必要的带宽消耗。而目前常用的邮件服务器 postfix 以及支持邮件服务器的相关分析软件都支持正则表达式的比对功能。将来信的标题和内容与特殊字符串进行对比,发现问题邮件就过滤掉。除邮件服务器之外,很多服务器软件都支持正则表达式。
虽然这些软件都支持正则表达式,不过字符串的对比规则还需要系统管理员来添加,所以作为系统管理员,正则表达式是必须掌握的技能之一。
三、基础正则表达式
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用的正则表达式的最基础的部分。在 Linux 系统中常见的文件处理工具中 grep 与 sed 支持基础正则表达式,而 egrep 与 awk 支持扩展正则表达式。掌握基础正则表达式的使用方法,首先必须了解基本正则表达式所包含的元字符的含义,下面通过 grep 命令以举例的方式逐个介绍。
四、基础正则表达式示例
下面的操作需要提前准备一个名为 test.txt 的测试文件,把httpdd的配置文件复制到test.txt文档中,文件具体内容如下所示:
[root@localhost ~]# cp /etc/httpd/conf/httpd.conf /opt/test.txt
[root@localhost ~]# cd /opt
[root@localhost opt]# ls
rh test.txt
[root@localhost opt]# cat test.txt
#
# This is the main Apache HTTP server configuration file. It contains the
# configuration directives that give the server its instructions.
# See <URL:http://httpd.apache.org/docs/2.4/> for detailed information.
# In particular, see
# <URL:http://httpd.apache.org/docs/2.4/mod/directives.html>
# for a discussion of each configuration directive.
#
# Do NOT simply read the instructions in here without understanding
# what they do. They're here only as hints or reminders. If you are unsure
# consult the online docs. You have been warned.
#
# Configuration and logfile names: If the filenames you specify for many
# of the server's control files begin with "/" (or "drive:/" for Win32), the
,,,,,//省略部分内容
[root@localhost opt]#
grep
1.查找特定字符
(1)查找特定字符非常简单,如执行以下命令即可从 test.txt 文件中查找出特定字符“the” 所在位置。其中“-n”表示显示行号、“-i”表示不区分大小写。命令执行后,符合匹配标准的字符,字体颜色会变为红色(本章中全部通过加粗显示代替)。
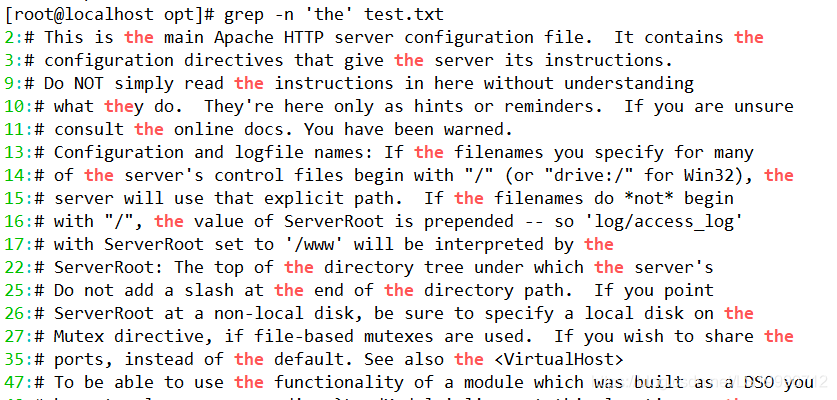
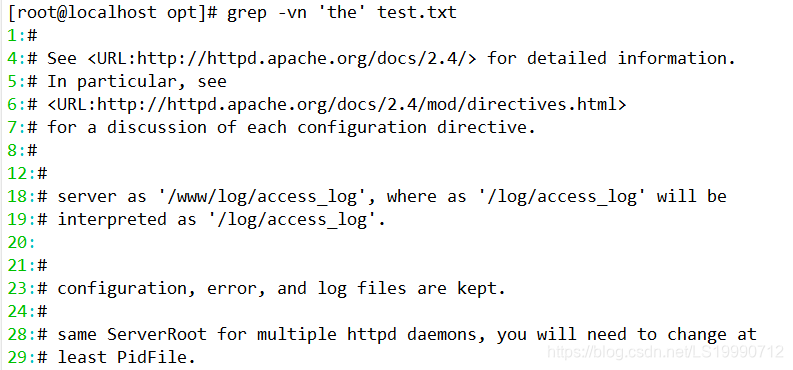
(2)若反向选择,如查找不包含“the”字符的行,则需要通过 grep 命令的“-vn”选项实现。
2.利用中括号“[]”来查找集合字符
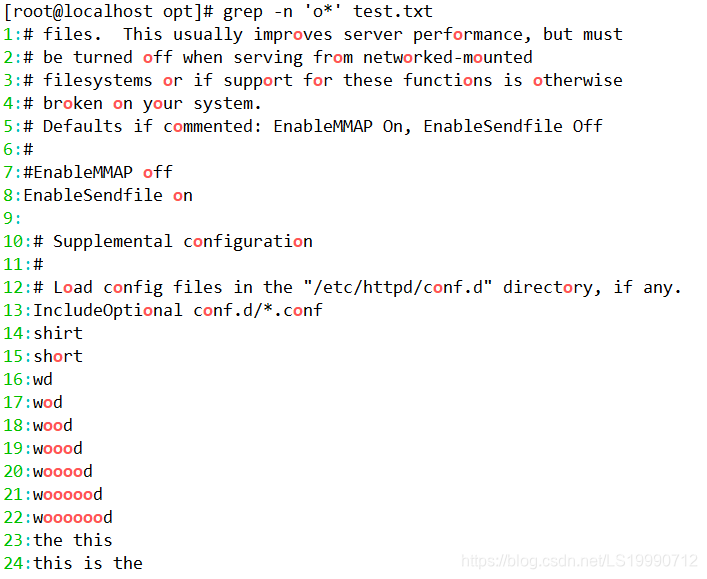
(1)想要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含“sh” 与“rt”。此时执行以下命令即可同时查找到“shirt”与“short”这两个字符串。“[]”中无论有几个字符,都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”。

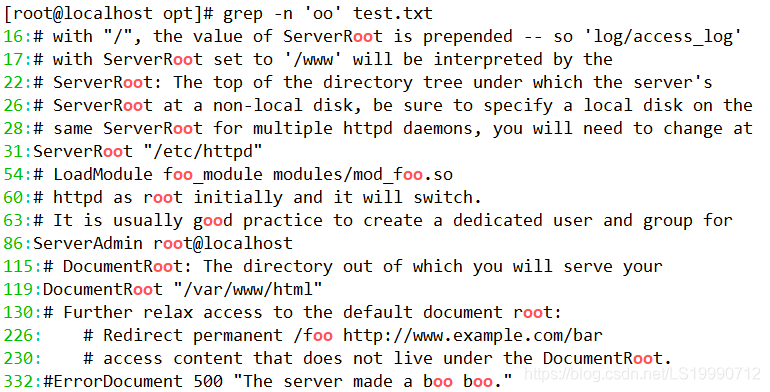
(2)若要查找包含重复单个字符“oo”时,只需要执行以下命令即可。
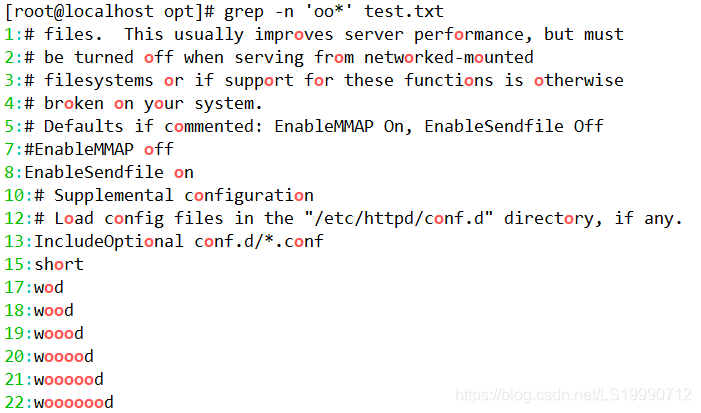
(3)若查找“oo”前面不是“w”的字符串,只需要通过集合字符的反向选择“[^]”来实现该目的,如执行“grep –n‘[^w]oo’test.txt”命令表示在 test.txt 文本中查找“oo” 前面不是“w”的字符串。
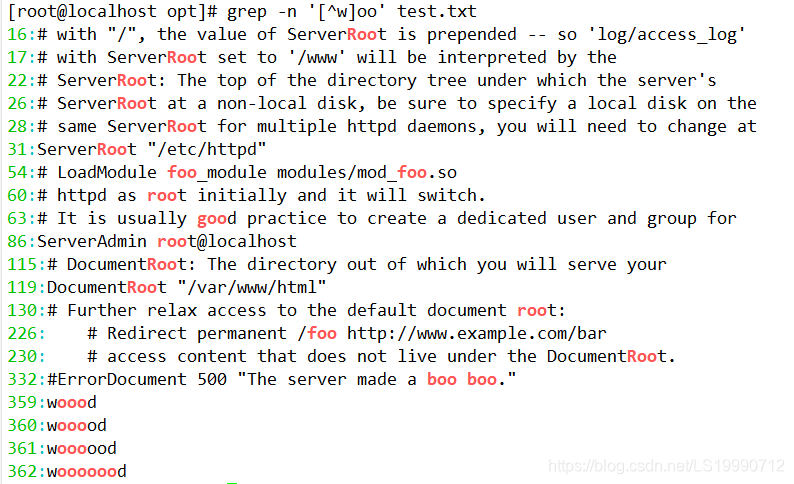
(4)在上述命令的执行结果中发现“woood”与“wooooood”也符合匹配规则,二者均包含“w”。其实通过执行结果就可以看出,符合匹配标准的字符加粗显示,而上述结果中可以得知,“#woood #”中加粗显示的是“ooo”,而“oo”前面的“o”是符合匹配规则的。同理“#woooooood #”也符合匹配规则。
若不希望“oo”前面存在小写字母,可以使用“grep –n‘[^a-z]oo’test.txt”命令实现,其中“a-z”表示小写字母,大写字母则通过“A-Z”表示。

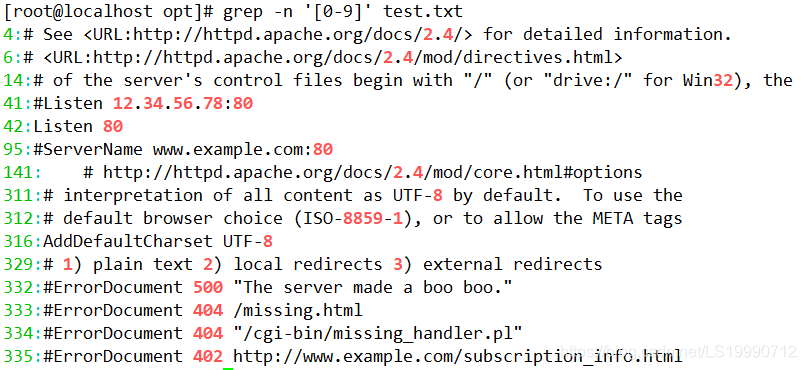
(5)查找包含数字的行可以通过“grep –n‘[0-9]’test.txt”命令来实现。
3.查找行首“^”与行尾字符“$”
(1)基础正则表达式包含两个定位元字符:“^”(行首)与“$”(行尾)。在上面的示例中,查询“the”字符串时出现了很多包含“the”的行,如果想要查询以“the”字符串为行首的行,则可以通过“^”元字符来实现。
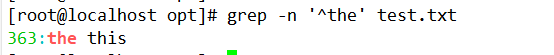
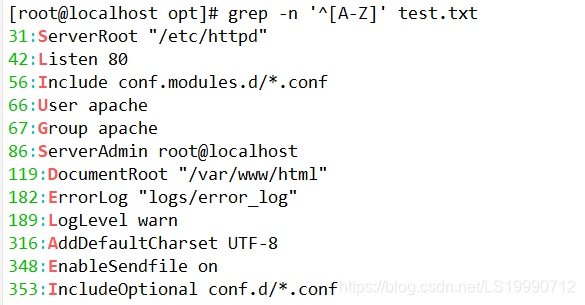
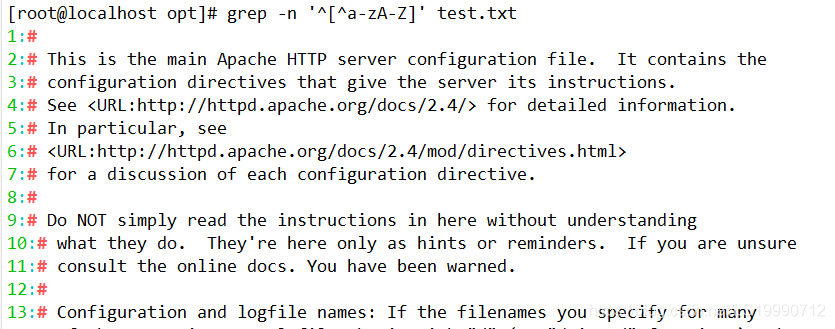
(2)查询以小写字母开头的行可以通过“^[a-z]”规则来过滤,查询大写字母开头的行则使用“^[A-Z]”规则,若查询不以字母开头的行则使用“^[^a-zA-Z]”规则。

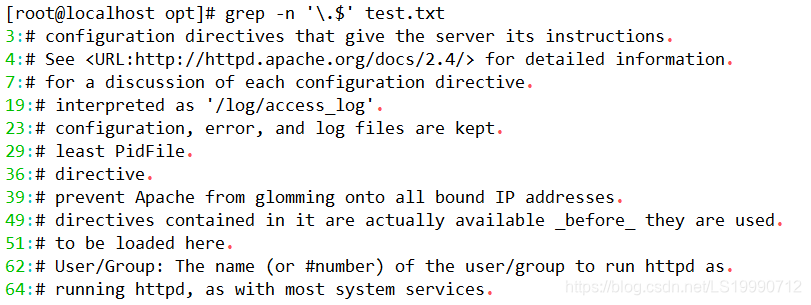
(3)“^”符号在元字符集合“[]”符号内外的作用是不一样的,在“[]”符号内表示反向选择,在“[]”符号外则代表定位行首。反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符。例如,执行以下命令即可实现查询以小数点(.)结尾的行。因为小数点(.) 在正则表达式中也是一个元字符(后面会讲到),所以在这里需要用转义字符“\”将具有特 殊意义的字符转化成普通字符。
(4)当查询空白行时,执行“grep –n‘^$’test.txt”命令即可。

4.查找任意一个字符“.”与重复字符“*”
(1)前面提到,在正则表达式中小数点(.)也是一个元字符,代表任意一个字符。例如, 执行以下命令就可以查找“w??d”的字符串,即共有四个字符,以 w 开头 d 结尾。

(2)在上述结果中,“wood”字符串“w..d”匹配规则。若想要查询 oo、ooo、ooooo 等资料,则需要使用星号(*)元字符。但需要注意的是,“*”代表的是重复零个或多个前面的单字符。“o*”表示拥有零个(即为空字符)或大于等于一个“o”的字符,因为允许空字符,所以执行“grep –n‘o*’test.txt”命令会将文本中所有的内容都输出打印。如果是“oo*”, 则第一个 o 必须存在,第二个 o 则是零个或多个 o,所以凡是包含 o、oo、ooo、ooo,等的资料都符合标准。同理,若查询包含至少两个 o 以上的字符串,则执行“grep –n‘ooo*’ test.txt”命令即可。

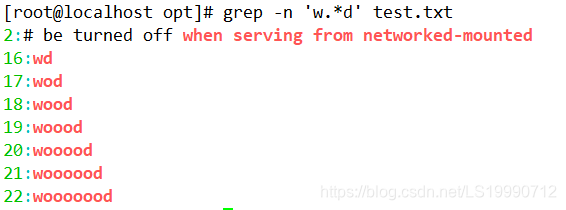
(3)查询以 w 开头 d 结尾,中间包含至少一个 o 的字符串,执行以下命令即可实现。

(4)查询以 w 开头 d 结尾,中间的字符可有可无的字符串。
(5)查询任意数字所在行。
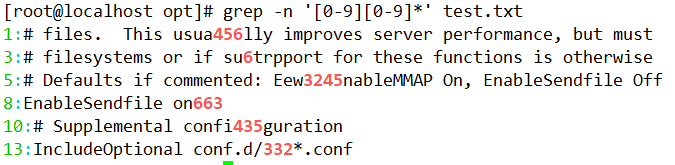
5.查找连续字符范围“{}”
在上面的示例中,我们使用“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一个范围内的重复的字符串该如何实现呢?例如,查找三到五个 o 的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符“{}”。因为“{}”在 Shell 中具有特殊 意义,所以在使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。 “{}”字符的使用方法如下所示。
(1)查询两个 o 的字符。
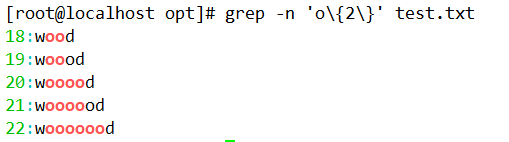
(2)查询以 w 开头以 d 结尾,中间包含 2~5 个 o 的字符串。

(3)查询以 w 开头以 d 结尾,中间包含 2 以上 o 的字符串。

6.元字符总结
| 元字符 | 作用 |
| ^ | 匹配输入字符串的开始位置。除非在方括号表达式中使用,表示不包含该字符集合。要匹配“^”字符本身,请使用“\^” |
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则“$”也匹配‘\n’或‘\r’。要匹配“$”字符本身,请使用“\$” |
| . | 匹配除“\r\n”之外的任何单个字符 |
| \ | 将下一个字符标记为特殊字符、原义字符、向后引用、八进制转义符。例如,‘n’匹配字符“n”。 ‘\n’匹配换行符。序列‘\\’匹配“\”,而‘\(’则匹配“(” |
| * | 匹配前面的子表达式零次或多次。要匹配“*”字符,请使用“\*” |
| [ ] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a” |
| [^] | 赋值字符集合。匹配未包含的一个任意字符。例如,“[^abc]”可以匹配“plain”中“plin”中的任何一个字母 |
| [n1-n2] | 字符范围。匹配指定范围内的任意一个字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意一个小写字母字符。 注意:只有连字符(-)在字符组内部,并且出现在两个字符之间时,才能表示字符的范围;如 果出现在字符组的开头,则只能表示连字符本身 |
| {n} | n 是一个非负整数,匹配确定的 n 次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个 o |
| {n,} | n 是一个非负整数,至少匹配 n 次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有 o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*” |
| {n,m} | m 和n 均为非负整数,其中 n<=m,最少匹配 n 次且最多匹配 m 次 |

















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









