



 本文通过使用sklearn库创建了一个人工数据集,并利用交叉验证的方法对比了三种不同的机器学习分类器:高斯朴素贝叶斯(GuassianNB)、支持向量机(SVC)及随机森林(RandomForestClassifier)的性能。实验结果显示随机森林分类器的准确度较高。
本文通过使用sklearn库创建了一个人工数据集,并利用交叉验证的方法对比了三种不同的机器学习分类器:高斯朴素贝叶斯(GuassianNB)、支持向量机(SVC)及随机森林(RandomForestClassifier)的性能。实验结果显示随机森林分类器的准确度较高。

首先是创建数据集和split 数据集
import sklearn
from sklearn import datasets
from sklearn import cross_validation
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
dataset = datasets.make_classification(n_samples=1000,n_features=10)
data = dataset[0]
target = dataset[1]
kf = cross_validation.KFold(len(data),n_folds=10,shuffle=True)然后是Guassian NB 算法训练
# Guassian NB
i = 1
for train_i,test_i in kf:
x_train,y_train = data[train_i],target[train_i]
x_test,y_test = data[test_i],target[test_i]
clf = GaussianNB()
clf.fit(x_train,y_train)
pred = clf.predict(x_test)
print("Group:",i)
i += 1
print("Accuracy:", metrics.accuracy_score(y_test, pred))
print("F1-score:", metrics.f1_score(y_test, pred))
print("AUC ROC:",metrics.roc_auc_score(y_test, pred))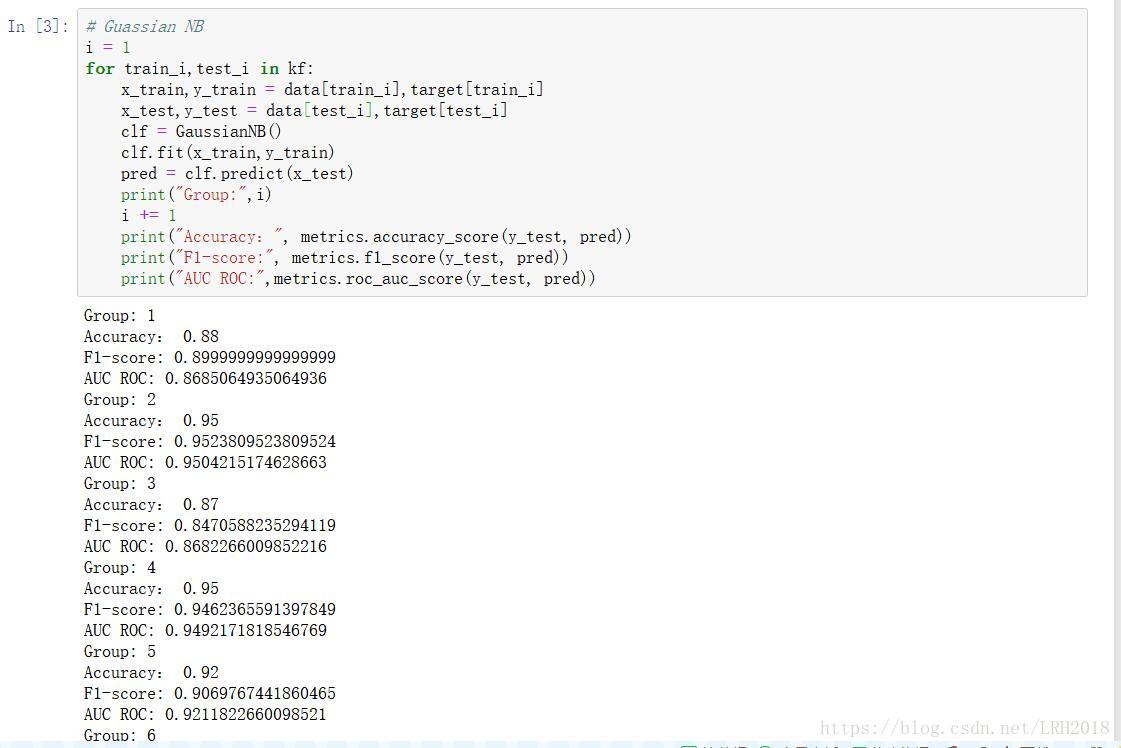

SVC
#SVC
for c in [1e-02, 1e-01, 1e00, 1e01, 1e02]:
i = 1
for train_index,test_index in kf:
x_train,y_train = data[train_index],target[train_index]
x_test,y_test = data[test_index],target[test_index]
clf = SVC(C=c,kernel='rbf',gamma=0.1)
clf.fit(x_train,y_train)
pred = clf.predict(x_test)
print("Group:",i)
i += 1
print("C = ",c)
print("Accuracy:", metrics.accuracy_score(y_test, pred))
print("F1-score:", metrics.f1_score(y_test, pred))
print("AUC ROC:",metrics.roc_auc_score(y_test, pred))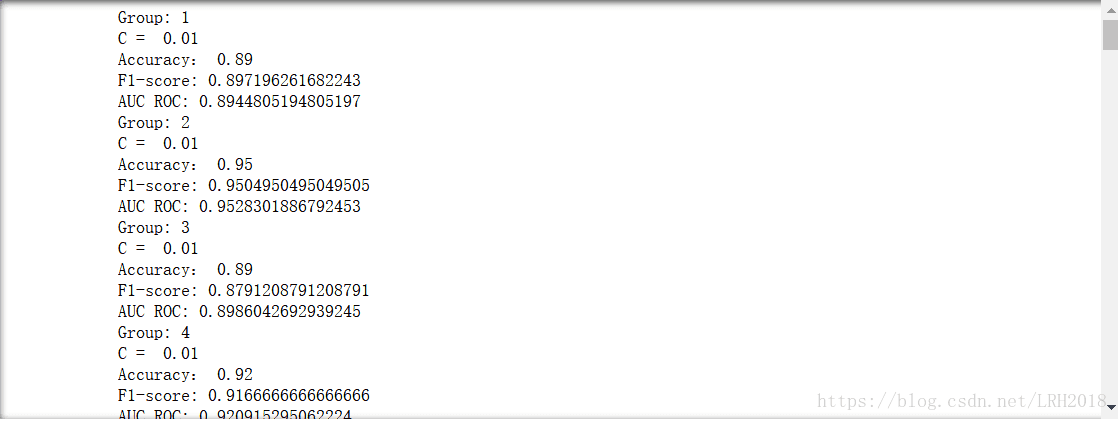
输出较长,这里不全部给出截图
RandomForestClassifier
for n in [10, 100, 1000]:
i = 1
for train_index,test_index in kf:
x_train,y_train = data[train_index],target[train_index]
x_test,y_test = data[test_index],target[test_index]
clf = RandomForestClassifier(n_estimators=n)
clf.fit(x_train,y_train)
pred = clf.predict(x_test)
print("Group:",i)
i += 1
print("n_estimators = ",n)
print("Accuracy:", metrics.accuracy_score(y_test, pred))
print("F1-score:", metrics.f1_score(y_test, pred))
print("AUC ROC:",metrics.roc_auc_score(y_test, pred))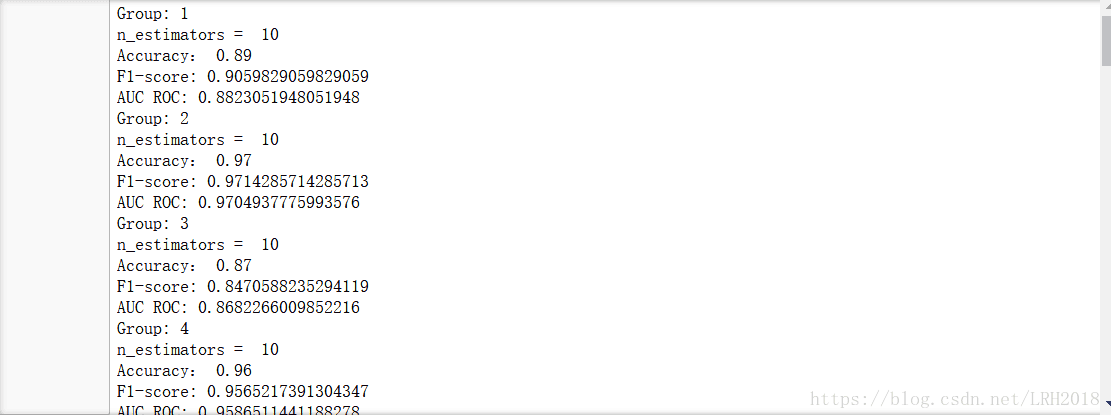
输出较长,这里不全部给出截图
结果:RandomForestClassifier 的准确度比较好,而Guassian NB的准确度差一点,SVC的准确度波动较大

















 2191
2191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









