




 本文介绍了C++中的基本编程概念,如保留小数点后n位、区间分类的if语句、while和for循环的转换。接着,深入讲解了字符串处理、函数的递归和迭代、构造和析构函数、类和对象的封装、继承、多态,以及STL中的容器如vector、list、set和map的基本操作。此外,还涵盖了指针、引用、深拷贝和浅拷贝、运算符重载等主题。
本文介绍了C++中的基本编程概念,如保留小数点后n位、区间分类的if语句、while和for循环的转换。接着,深入讲解了字符串处理、函数的递归和迭代、构造和析构函数、类和对象的封装、继承、多态,以及STL中的容器如vector、list、set和map的基本操作。此外,还涵盖了指针、引用、深拷贝和浅拷贝、运算符重载等主题。
1、保留小数点后n位
cpp8:cout << fixed << setprecision(1) << cost << endl;
只要出现了fixed,则后面都是以fixed输出。
cout<<fixed<<x<<endl;
cout<<y<<endl;//之后不用再打一遍fixed了
特点:无科学记数法即使用fixed时,输出小数点后的位数是6位。
这样输出的方法叫做定点表示法表示浮点数!
fixed与setprecision(n)连用可以控制小数点后的位数,现在就可以理解因为那是定点数记数法。
如果没有fixed的话,就是浮点数记数法了,那么它控制的应该就是有效数字的位数(包括小数点前的)
2、按照区间分类时从高到低写if语句
问题:BMI=体重/身高2(kg/m2)。小于 18.5 属于"偏瘦",大于等于 18.5 小于 20.9 属于"苗条",大于等于 20.9 小于等于 24.9 属于"适中",超过 24.9 属于"偏胖"。
if(BMI>=24.9)
{
cout<<"偏胖"<<endl;
}
else if (BMI>=20.9) {
cout<<"适中"<<endl;
}
else if (BMI>=18.5) {
cout<<"苗条"<<endl;
}
else if (BMI>0) {
cout<<"偏瘦"<<endl;
}
注意:如果区间有上限则不能像上述代码编写。,需要将每个区间写出来
比如:
90-100 优秀
80-89 良
70-79 中
60-69 及格
0-59 差
如果区间不连续可以使用'' || ''或运算符或者使用case语句进行编写
比如:3 - 5 月为春季、6 - 8 月为夏季、9 - 11 月为秋季、12,1,2 月为冬季
3、while循环与for循环的转换
作用:满足循环条件,执行循环语句
语法: while(循环条件){ 循环语句 }
解释:只要循环条件的结果为真,就执行循环语句
while(n)
{
if(n%2==0)
{
sum+=n;
}
n--;
}注意:在while循环语句里一般都要控制循环条件++或者-- 因为不能陷入死循环!
do{ 循环语句 } while(循环条件); 与 while 的区别在于do...while 会先执行一次循环语句,再判断 循环条件。
语法: for(起始表达式;条件表达式;末尾循环体) { 循环语句; }
for(int i=1;i<=n;i++)
{
if(i%2==0)
{
sum+=i;
}
}
在for循环中,条件表达式比较重要,因为这是跳出循环的依据
补充1:阶乘一般需要用到*=运算符
补充2:a++;++a;a--;--a
前置递增先对变量进行++,再计算表达式
后置递增先计算表达式,后对变量进行++
补充3:如何提取三位数的个十百位
a=i%10;
b=i%100/10;
c=i/100;
补充4:外层循环执行 1 次,内层循环执行 1 轮
补充5:很大的数特别是乘积的和或者阶乘的结果要用long long长长整型
补充6:除与取模的用途
/ 除 10 / 5 = 2
% 取模(取余) 10 % 3 = 1
除一般用于得到高位的数 比如:int 188/100=1 188%100=88 88/10=8
取余一般用于这个数是否能被另一个数整除 如果可以则为0 不可以则为其他数
4、数组的基本操作
一维数组定义方式: 数据类型 数组名[ 数组长度 ]; int arr[6];
"整个数组所占内存空间为: " << sizeof(arr)
"每个元素所占内存空间为: " << sizeof(arr[0])
"数组的元素个数为: " << sizeof(arr) / sizeof(arr[0])
补充1:找数组中的最值:求解思路 先定义最值 遍历整个数组 若遍历到的数比最值大或者小 则将最值赋予此值
int max=arr[0],min=arr[0];//将最值赋给任意一值
for(int i=1;i<len;i++)//遍历数组
{
if(arr[i]>max)
{
max=arr[i];
}
if(arr[i]<min)
{
min=arr[i];
}
}补充2:数组元素反转
定义一个临时变量,第一个和最后一个成对的进行交换,交换次数为len/2
int temp=0;//定义一个临时变量
for(int i=0;i<len/2;i++){//成对进行交换 所以只需要len/2
temp=arr[i];
arr[i]=arr[len-1-i];
arr[len-1-i]=temp;
}补充3:冒泡排序 是对数组内元素进行排序
1. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2. 对每一对相邻元素做同样的工作,执行完毕后,找到第一个最大值。
3. 重复以上的步骤,每次比较次数-1,直到不需要比较
for(int i=0;i<len-1;i++) {//冒泡排序需要做len-1次
for (int j=0; j<len-1-i; j++) {//每次需要交换len-1-i次
if(arr[j]>arr[j+1]) {
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
补充4:选择排序即选定一位最值,将其他的与之比较
for(int i=0;i<len-1;i++)//进行len-1次选择
{
int min=i;//选定一位为最小值
for(int j=i+1;j<len;j++)//选定一位后 将其后面的数分别再比较
{
if(arr[j]<arr[min])//若有比选定的数更小的数 则重新赋值给最小值
{
min=j;
}
}
swap(arr[i],arr[min]);//比较之后进行交换
}补充5:二维数组
定义方式为 数据类型 数组名[ 行数 ][ 列数 ] = { {数据 1,数据 2 } ,{数据 3,数据 4 } };
遍历二维数组的方式是嵌套循环:
for(int i = 0; i < 行数; i++) {
for(int j = 0; j < 列数; j++) {
sum += arr[i][j];//求数组总和
}
}补充6:指针和数组: 利用指针访问数组中元素
int * p = arr; //指向数组的指针
for (int i = 0; i < 10; i++)
{ //利用指针遍历数组
cout << *p << endl;
p++;
}
5、字符串的基本语法
输入字符串的方法:
1、cin >> str
虽然可以使用 cin 和 >>运算符来输入字符串,当 cin 读取数据时,一旦它接触到第一个非空格字符即开始阅读,当它读取到下一个空白字符(空格、制表符、换行符)时,它将停止读取,并自动在结尾添加空字符。
故 cin 不能输入包含嵌入空格的字符串。
2、面向行的输入:getline(cin,temp) 第二个参数为string类型的变量。还有get()函数
为了解决cin的问题,可以使用一个叫做 getline 的 C++ 函数。此函数可读取整行,包括前导和嵌入的空格,并将其存储在字符串对象中。
cin.getline(1,2) 参数1是用来储存输入行数组的名称,参数2是要读取的字符数。如果参数为20,函数最多读取19个字符,余下的空间用来存储自动在结尾处添加的空字符。
getline()将丢弃换行符,而get()将换行符保留在输入序列里。
补充1:字符串拼接可以直接使用+号进行拼接:string s=s1+s2;
6、结构体简单使用
结构体定义:struct 结构体名 { 结构体成员列表 };
结构体变量利用操作符 ''.'' 访问成员
结构体数组:struct 结构体名 数组名[元素个数] = { {} , {} , ... {} }
结构体指针:利用操作符 `-> `可以通过结构体指针访问结构体属性
struct student * p = &stu;
p->score = 80; //指针通过 -> 操作符可以访问成员
结构体作为参数向函数进行地址传递也就是 使用指针访问结构体成员
7、new和delete运算符
在 C++中主要利用 new 在堆区开辟内存,堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符delete
int* a = new int(10);
delete p;//利用 delete 释放堆区数据
int *p=new int[n];//在堆区开辟数组 p为数组名
delete[] arr;//释放数组 delete 后加 []
8、函数的使用
函数的定义:
返回值类型 函数名 (参数列表)
{
函数体语句
return 表达式
}
函数定义里小括号内称为形参,函数调用时传入的参数称为实参。
函数的声明:告诉编译器函数名称及如何调用函数。函数的实际主体可以单独定义。声明可以多次,但是函数的定义只能有一次
补充1:值传递:是函数调用时实参将数值传入给形参,值传递时,如果形参发生,并不会影响实参,值传递时,形参是修饰不了实参
void mySwap01(int a, int b) {
int temp = a;
a = b;
b = temp;
}
补充2:地址传递会改变实参 调用方式:mySwap02(&a, &b);
void mySwap02(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
补充3:引用传递会改变实参,让形参修饰实参,引用可以简化指针修改实参
通过引用参数产生的效果同按地址传递是一样的。引用的语法更清楚简单
void mySwap03(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}指针、数组、函数:当数组名传入到函数作为参数时,被退化为指向首元素的指针
void func(int* p, int n) //指针指向一个数组 n表示数组的长度
{
for(int i=0;i<n;i++)//循环遍历数组
{
if(p[i]==0)//检查数组中索引为 i 的元素是否为零
{
for(int j=i;j<n-1;j++)//将0后面的元素移到0的前面 这个循环只定义了0前面的那个元素
{
p[j]=p[j+1];//将0元素右移一位
//此时并没有更改最后一位
}
p[n-1]=0;//将数组中最后一个元素设置为零
n--;//更新长度
}
}
}函数的分文件编写:一般有 4 个步骤
1. 创建后缀名为.h 的头文件
2. 创建后缀名为.cpp 的源文件
3. 在头文件中写函数的声明
4. 在源文件中写函数的定义
补充4:字符串的大小可以通过ACSLL码来比较,如果字符串的长度不同,可以通过判断字符串是否遍历结束即指针指向空字符'\0'
int mystrcmp(const char* src, const char* dst) {
// 先判断两个字符串的长度
while(*src&&*dst)
{
//两个字符串长度相同 字符不同时的比较
if(*src-*dst>0)
{
return 1;
}
else if(*src-*dst<0)
{
return -1;
}
src++;
dst++;
}
//判断两个字符串是否遍历结束
if(*src=='\0'&&*dst!='\0')
{
return -1;
}
else if(*src=='\0'&&*dst=='\0')
{
return 0;
}
else
{
return 1;
}
补充5:函数strncmp()、strlen()、strcpy()
函数原型:int strncmp(const char* str1, const char* str2, size_t num)
头 文 件:#include <string.h>
返 回 值:(与strncmp相同)str1 = str2 则返回0,比较字符串str1和str2的前num个字符。
str1 > str2 则返回大于0的值,
str1 < str2 则返回小于0的值
strncmp可用于比较两个字符串常量或比较数组和字符串常量,不能比较数字等其他形式的参数。
strlen()函数:
1.strlen函数的函数原型:size_t strlen(const char*str) 该函数包含在string.h的头文件中。
2.该函数用于求参数str指向字符串的长度。
3.注意:字符串中’\0’作为结束标志,strlen函数返回的是在字符串中’\0’前面的字符个数(不包含’\0’),当字符串的下一位不是’\0’时,无法用strlen函数求长度,求出的为随机值。
for (int i = 0; i < strlen(str) - strlen(substr) + 1; i++)
//strlen(str)为源字符串长度 strlen(substr)为比较字符串长度
{
if (strncmp(str + i, substr, strlen(substr)) == 0)
count++;
}strcpy()函数:strcpy即string copy缩写,strcpy函数实现将源指针指向的空间里面的数据拷贝到目的地指针指向的空间,包括终止空字符('\0'),并在该点停止,char* strcpy(char* destination,char* source);源字符串必须以'\0'结束且源字符串的'\0'也会被拷贝到目标空间
注意:对于字符型数组来说,结尾字符为'\0',占一个空间。
public:
char* name; // 姓名
int age; // 年龄
Person(const char* name, int age) {
//int n=strlen(name);
this->name = new char[strlen(name)+1];
//字符串结尾符占一个数组元素位置
//strlen函数:计算的是字符串str的长度,计算的长度并不包含'\0'
//对于字符型数组来说,结尾字符为'\0',占一个空间。
strcpy(this->name, name);//将源指针指向的空间里面的数据拷贝到目的地指针指向的空间
this->age = age;
}
//如果不利用深拷贝在堆区创建新内存,会导致浅拷贝带来的重复释放堆区问题
Person(const Person& p) {
this->name = new char[strlen(p.name)+1];
strcpy(this->name, p.name);//char* strcpy(char* destination,char* source)
//this->name=p.name;
this->age = p.age;
}补充6:字符函数:判断字母字符、数字字符、空白、标点符号的函数
1、isalpha()函数用来判断一个字符是否为字母,如果是字母则返回非零,否则返回零。
2、isdigit()函数用来判断一个字符是否为数字,如果是字母则返回非零,否则返回零。
3、isspace()函数用来判断一个字符是否为空格,如果是字母则返回非零,否则返回零。
4、isalnum()函数用来判断一个字符是否为数字或字母,是则输出非零,否则输出零。
5、islower()函数用来判断一个字符是否为小写字母。
6、ispuuer()函数用来判断一个字符是否为大写字母。
补充7:函数递归和迭代
long long factorial(int n) {
//递归实现
if(n==1){
return 1;
}
return factorial(n-1)*n;
//f(5)=f(4)*5
//f(4)=f(3)*4
//f(3)=f(2)*3
//f(2)=f(1)*2
//f(1)=1 //1*2*3*4*5
//f(n-1)*n
}
//实际上是斐波那契数列问题:f(n)=f(n−1)+f(n−2)
//递归法
if(n<3){
return 1;
}
else{
return getSum(n-1)+getSum(n-2);
}
//迭代法
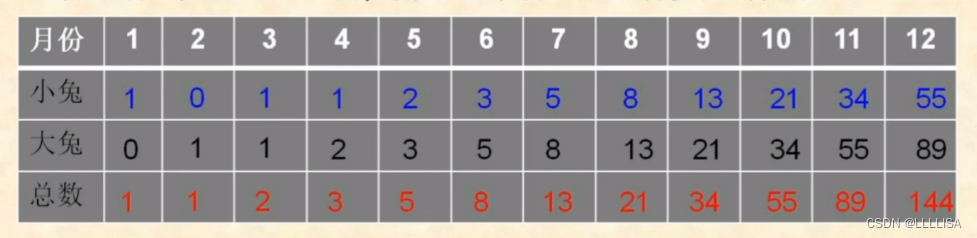
//除了自上而下的递归,我们还可以利用像上述数组一样的自下而上的相加
//除了第一二月外,这个月的值等于它前两个月的值相加,我们可以从第三个月开始不断累加,并更新前两个月的值即可
if(n<3) {
return 1;
}
else{
int a=1,b=1;//a表示当前要计算的月份n-2一个月 b表示当前要计算的月份n-1个月
int sum=0;
for(int i=3;i<=n;i++){
sum=a+b;//前两个月的值相加
b=a;//上月的总和
a=sum;//这月的总和
}
return sum;
}补充8:引用的基本使用
1、给变量起别名:数据类型 &别名 = 原名 int &b = a;
2、引用必须初始化,引用在初始化后,不可以改变
3、函数传参时,可以利用引用的技术让形参修饰实参
4、引用的本质在 c++内部实现是一个指针常量,指针常量是指针指向不可改,也说明为什么引用不可 更改
9、类和对象——封装
C++面向对象的三大特性为:==封装、继承、多态==对象上有其属性和行为
封装的意义: 将属性和行为作为一个整体,表现生活中的事物,将属性和行为加以权限控制
1、在设计类的时候,属性和行为写在一起,表现事物
语法:class 类名{ 访问权限: 属性 / 行为 };
2、类在设计时,可以把属性和行为放在不同的权限下,加以控制
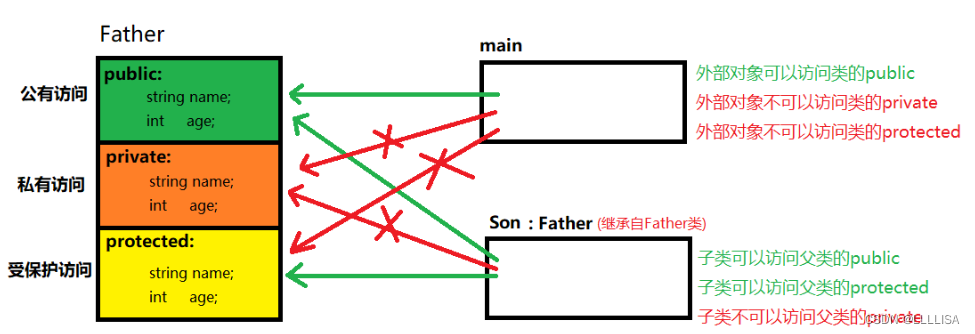
访问权限有三种:
1. public 公共权限 类内类外都可以访问
2. protected 保护权限 只有类内可以访问 当公共继承时,子类可以访问protected权限 但在外部 不能通过子类对象访问protected成员
Son类的成员函数中,可以直接访问它的父类的protected成员,
3. private 私有权限 只有类内可以访问 但可以使用友元让一个函数或者类 访问另一个类中私有成员
补充1:构造函数和析构函数
这两个函数将会被编译器自动调用, 完成对象初始化和清理工作。对象的初始化和清理工作是编译器强制要我们做的事情,因此如果我们不提供构造和析构, 编译器会提供。编译器提供的构造函数和析构函数是空实现。
构造函数语法:类名(){} 析构函数语法:~类名(){}
1. 构造、析构函数,没有返回值也不写 void
2. 构造函数名称与类名相同,析构在名称前加上符号 ~
3. 构造函数可以有参数,因此可以发生重载 析构函数不可以有参数,因此不可以发生重载
4. 程序在调用对象时候会自动调用构造,无须手动调用,而且只会调用一次
5、程序在对象销毁前会自动调用析构--一般用于将堆区开辟的数据做释放操作
class Person {
public:
//无参(默认)构造函数
Person() {
cout << "无参构造函数!" << endl;
}
//有参构造函数
Person(int a) {
age = a;
cout << "有参构造函数!" << endl;
}
//拷贝构造函数
Person(const Person& p) {
age = p.age;
cout << "拷贝构造函数 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+




 到【灌水乐园】发言
到【灌水乐园】发言







