




 本文介绍了一种使用Python批量从多个文件夹内的shp文件中提取温度数据的方法,并将其转换为CSV格式进行存储。
本文介绍了一种使用Python批量从多个文件夹内的shp文件中提取温度数据的方法,并将其转换为CSV格式进行存储。
1、问题描述
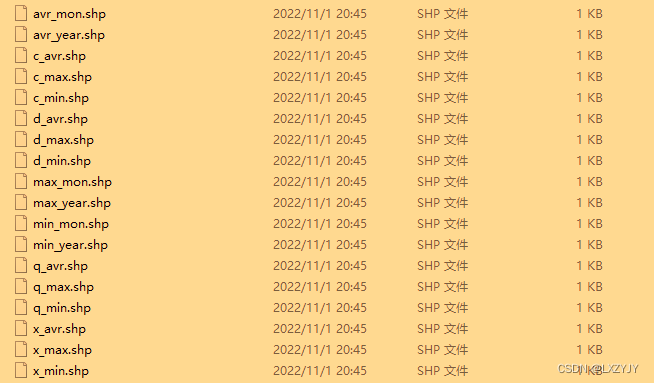
我有10个文件夹,每一个文件夹有18个shp文件(温度数据),需要提取每个shp文件的温度数据,即下图属性表中RASTERVALU列。

2、上代码
#coding:utf-8
import arcpy
from arcpy import env
import pandas as pd
#文件名list
file_name_list = ["avr_mon.shp","avr_year.shp",
"max_mon.shp","max_year.shp",
"min_mon.shp","min_year.shp",
"c_avr.shp","c_max.shp","c_min.shp",
"x_avr.shp","x_max.shp","x_min.shp",
"q_avr.shp", 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









