







 本文详细介绍了Java NIO中的缓冲区,包括缓冲区的种类、核心方法,以及缓冲区的四个核心属性。还讨论了直接缓冲区与非直接缓冲区的差异,特别是直接缓冲区在物理内存中的存储方式。此外,文章阐述了Linux虚拟内存、Java直接内存和内存映射的关系,解释了虚拟存储的工作原理,以及Java如何通过内存映射文件实现高效的文件读取。最后,提到了回调函数的概念和在Java中的应用示例。
本文详细介绍了Java NIO中的缓冲区,包括缓冲区的种类、核心方法,以及缓冲区的四个核心属性。还讨论了直接缓冲区与非直接缓冲区的差异,特别是直接缓冲区在物理内存中的存储方式。此外,文章阐述了Linux虚拟内存、Java直接内存和内存映射的关系,解释了虚拟存储的工作原理,以及Java如何通过内存映射文件实现高效的文件读取。最后,提到了回调函数的概念和在Java中的应用示例。
学习笔记,仅供参考,禁止搬运,如有不正确的地方欢迎大家指正,谢谢!!!
一、缓冲区buffer
|
代码
|
package com.lihefei.nio.day01;
import org.junit.jupiter.api.Test;
import java.nio.ByteBuffer;
/**
* 一、缓冲区(buffer):
* 1> 缓冲区在 Java NIO 中负责数据的存取/存储。
* 2> 缓冲区的底层结构是:数组。
* 3> 用于存储不同数据类型的数据,根据数据类型不同(boolean 除外),提供相应类型的缓冲区:
* ByteBuffer
* CharBuffer
* ShortBuffer
* IntBuffer
* LongBuffer
* FloatBuffer
* DoubleBuffer
* 上述缓冲区管理方式几乎一致,都是通过allocate()获取缓冲区
*
* 二、缓冲区存取数据的核心方法:
* put(): 存入数据到缓冲区中
* get(): 获取缓冲区中的数据
*
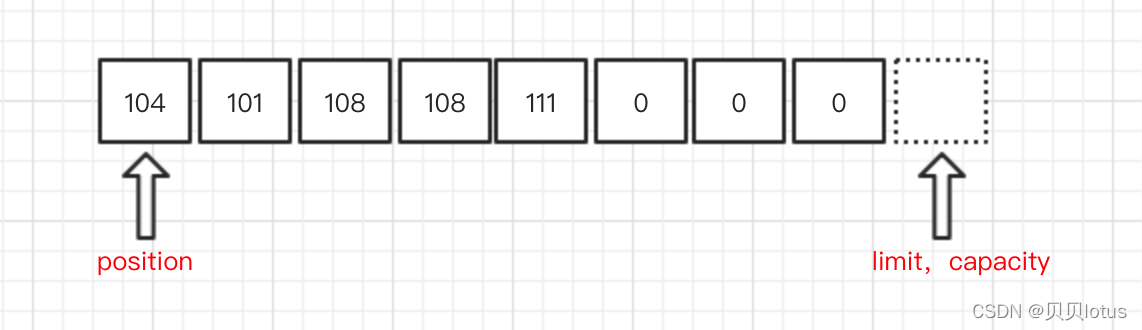
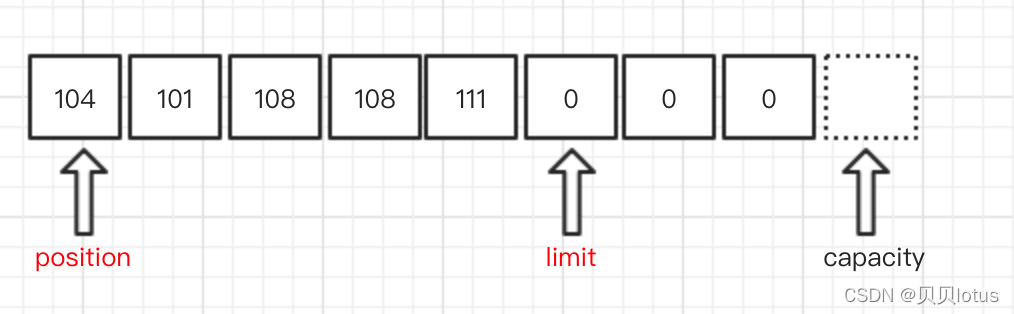
* 三、缓冲区中四个核心属性
* capacity:容量,表示缓冲区中最大存储数据的容量,一旦声明,不能改变。
* limit:界限,表示缓冲区可以操作数据的大小。(第 limit 个后面的数据,我们不能进行读写)
* position:位置,表示缓冲区中正在操作数据的位置。(从0开始)
* mark:标记,表示记录当前position的位置。可以通过reset(),将position恢复到mark的位置(让操作数据的位置跳回到标记的位置)
*
* 注意:
* 0 <= mark <= position <= limit <= capacity
* clear后,mark重置,若reset(),会报异常
*
* 四、直接缓冲区与非直接缓冲区
* 非直接缓冲区:通过allocate() 方法分配缓冲区,将缓冲区建立在JVM的内存中
* 直接缓冲区:
* 1> 通过allocateDirect() 方法分配缓冲区,将缓冲区建立在物理内存中,可以提高效率
* 2> 减少了在内核程序空间与JVM用户程序空间之间的拷贝,直接将磁盘地址与JVM虚拟地址之间的关系映射文件放在实际物理内存中,
* 方便Java程序对磁盘数据进行读写IO操作
*
* 注意:只有ByteBuffer支持直接缓冲区
*
* @author lotus
* @create 2020-11-24 7:02 下午
*/
public class BufferTest {
@Test
public void test1() {
String str = "abcde";
// 1.allocate()分配一个指定大小的缓冲区
ByteBuffer bb = ByteBuffer.allocate(1024);
System.out.println("================allocate()====================");
System.out.println("bb.position() = " + bb.position()); // 0
System.out.println("bb.limit() = " + bb.limit()); // 1024
System.out.println("bb.capacity() = " + bb.capacity()); // 1024
// 2.put():存入数据到缓冲区中
bb.put(str.getBytes());
System.out.println("================put()====================");
System.out.println("bb.position() = " + bb.position()); // 5
System.out.println("bb.limit() = " + bb.limit()); // 1024
System.out.println("bb.capacity() = " + bb.capacity()); // 1024
// 3.flip(): 缓冲区 由 写数据模式 切换成 读取数据模式 (默认为写数据模式 <<position=当前写入数据的下一个位置索引,limit=capacity>>)
bb.flip(); // 缓冲区:切换为读数据模式 <<limit=切换前写数据模式下的position,position=0>>
System.out.println("================flip()====================");
System.out.println("bb.position() = " + bb.position()); // 0
System.out.println("bb.limit() = " + bb.limit()); // 5
System.out.println("bb.capacity() = " + bb.capacity()); // 1024
// 4.get(): 读取缓冲区中的数据
byte[] dst = new byte[bb.limit()];
bb.get(dst);
System.out.println(new String(dst, 0, dst.length));
System.out.println("================get()====================");
System.out.println("bb.position() = " + bb.position()); // 5
System.out.println("bb.limit() = " + bb.limit()); // 5
System.out.println("bb.capacity() = " + bb.capacity()); // 1024
// 5.rewind(): 可重复读 <<重置:position=0>>
bb.rewind();
System.out.println("================rewind()====================");
System.out.println("bb.position() = " + bb.position()); // 0
System.out.println("bb.limit() = " + bb.limit()); // 5
System.out.println("bb.capacity() = " + bb.capacity()); // 1024
// 6.clear():清空缓冲区,但是缓冲区中的数据依然存在,处在"被遗忘"状态 <<缓冲区属性恢复初始值:position=0,limit=capacity>>
bb.clear();
System.out.println("================clear()====================");
System.out.println("bb.position() = " + bb.position()); // 0
System.out.println("bb.limit() = " + bb.limit()); // 1024
System.out.println("bb.capacity() = " + bb.capacity()); // 1024
System.out.println((char)bb.get()); // a
}
@Test
public void test2() {
String str = "abcde";
ByteBuffer buf = ByteBuffer.allocate(1024);
// 写
buf.put(str.getBytes());
// 切换
buf.flip();
// 读
byte[] dst = new byte[buf.limit()];
buf.get(dst,0,2);
System.out.println(new String(dst)); // ab
System.out.println(buf.position()); // 2
// mark():标记当前position的位置
buf.mark();
buf.get(dst,2,2);
System.out.println(new String(dst)); // abcd
System.out.println(buf.position()); // 4
// reset():恢复到mark()的位置
buf.reset();
System.out.println(buf.position()); // 2
// hasRemaining(): 判断缓冲区中是否还有剩余的数据
if(buf.hasRemaining()) {
// remaining(): 获取缓冲区中可以操作的数量
System.out.println(buf.remaining()); // 3
}
}
@Test
public void test3() {
// 分配直接缓冲区
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
System.out.println(buf.isDirect());
}
}
|
|
Java 如何和外部设备通信
|
计算机的外部设备有鼠标、键盘、打印机、网卡等,通常我们将外部设备和和主存之间的信息传递称为 I/O 操作 , 按操作特性可以分为,输出型设备,输入型设备,存储设备。现代设备都采用通道方式和主存进行交互,通道是一个专门用来处理IO任务的设备, CPU 在处理主程序时遇到I/O请求,启动指定通道上选址的设备,一旦启动成功,通道开始控制设备进行操作,而 CPU 可以继续执行其他任务,I/O 操作完成后,通道发出 I/O 操作结束的中断,处理器转而处理 IO 结束后的事件。其他处理 IO 的方式,例如轮询、中断、DMA,在性能上都不如通道。当然 Java 程序和外部设备通信也是通过系统调用完成。
|
|
课堂笔记:
NIO 与 IO
直接缓冲区与非直接缓冲区
|
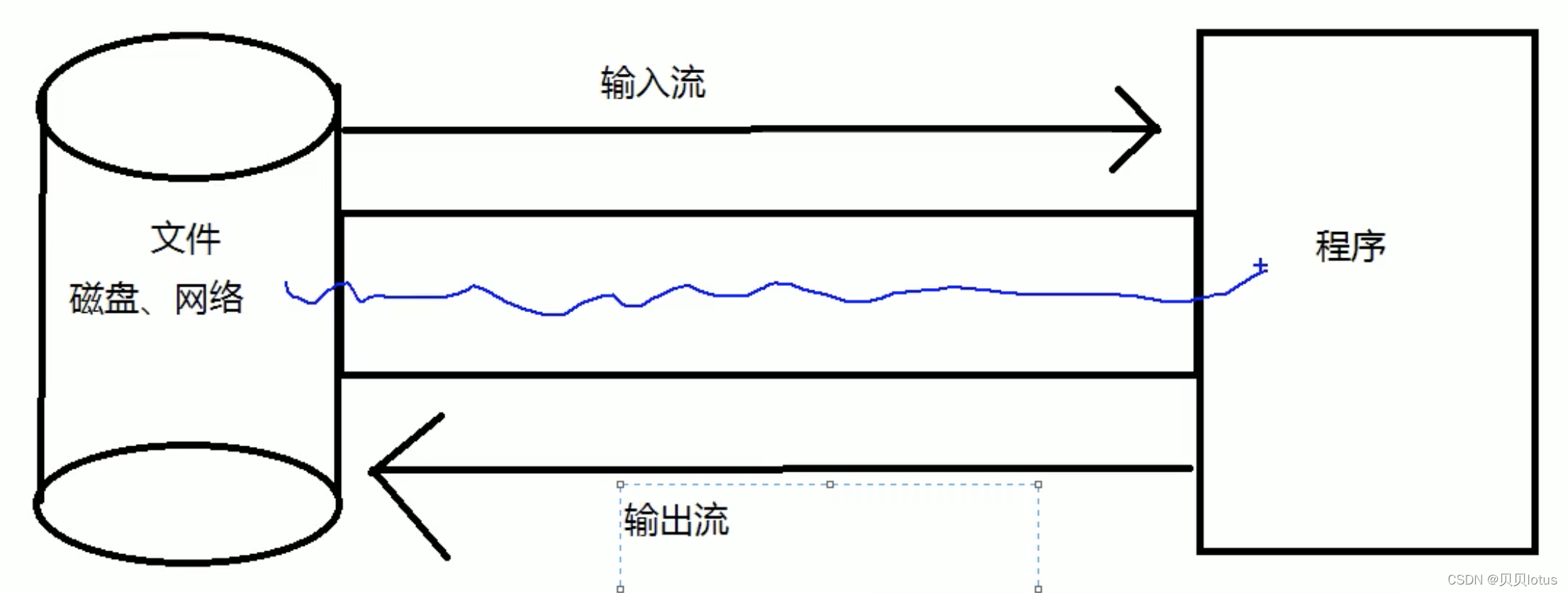
一、NIO 与 IO 区别:
IO 面向流 单向
NIO 面向缓冲区 channel通道 双向
传统IO:
水管
NIO:
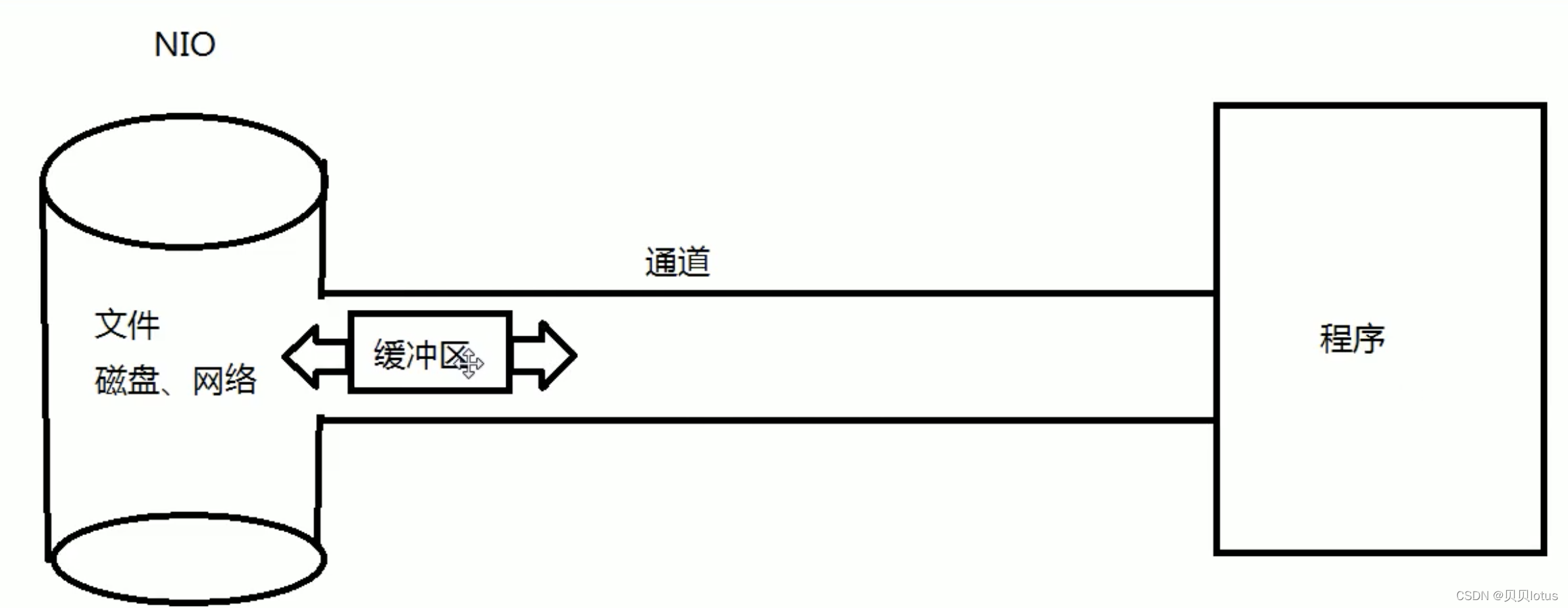
通道:只是负责传输,缓冲区负责数据的存储(存取) 铁路
IO设备:文件、磁盘、网络
二、直接缓冲区 与 非直接缓冲区
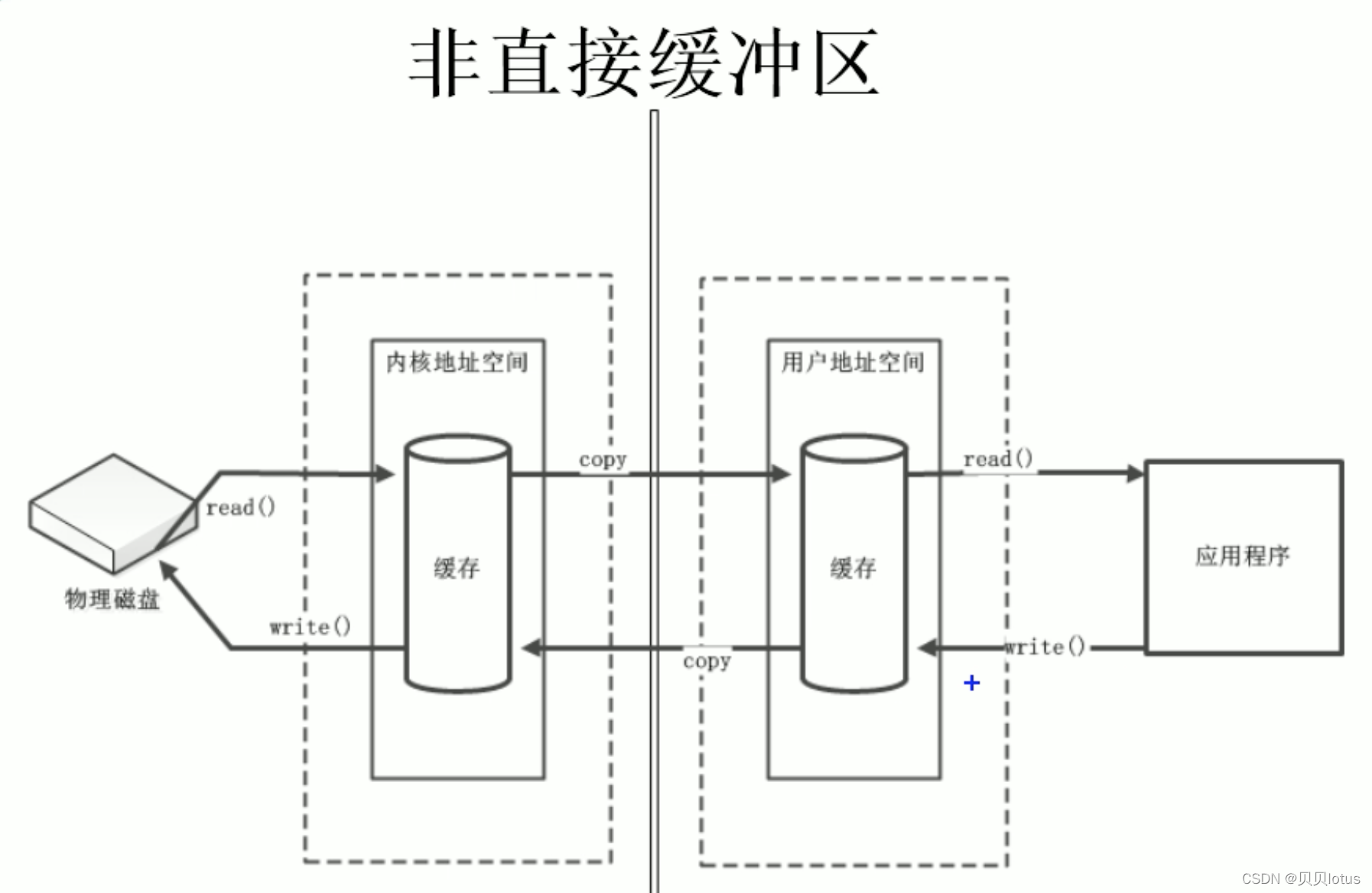
非直接缓冲区 :建立在JVM的内存中 (os给Java程序分配的内存空间) 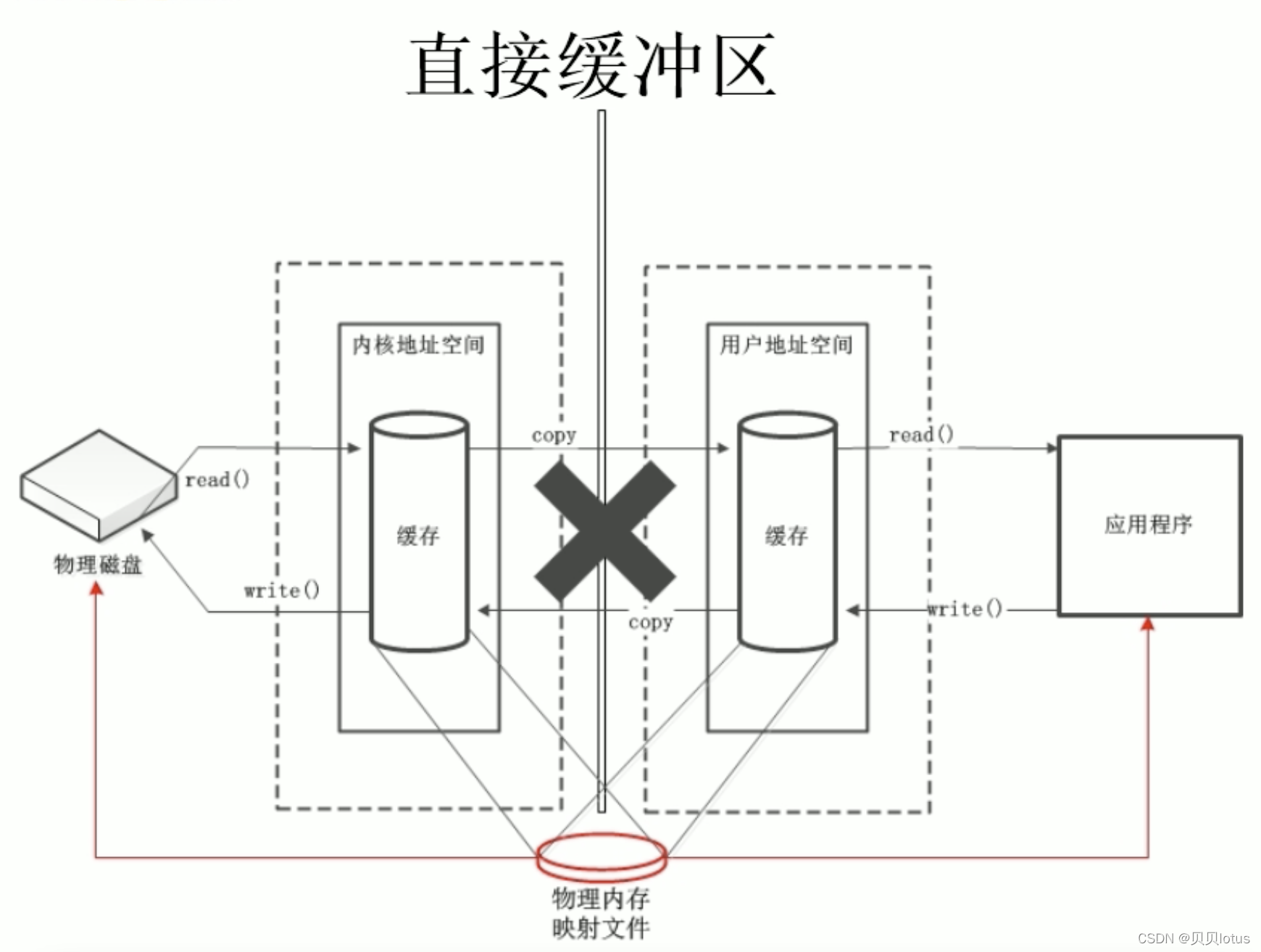
直接缓冲区:缓冲区直接建立在OS的物理内存中 (JVM堆外内存)
弊端:
不安全,
资源消耗大,开辟实际物理空间,资源回收问题
不确定何时将数据写到物理磁盘中去,由cpu调度决定
|
|
rewind()、clear()、flip() 区别
|
rewind():
rewind()方法将position置0,清除mark,它的作用在于为提取Buffer的有效数据做准备。 重读
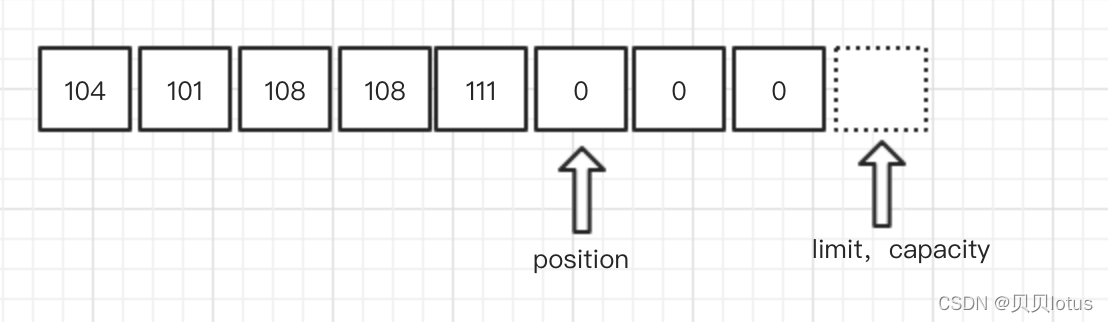
clear():
clear()方法将position置0,清除mark,与rewind()方法不同的是,它还会将limit置为capacity的大小,这个方法用于“清空”缓冲区。
注意,清空打上了引号,因为它的作用仅仅是将position、limit等这些标志位复原,并非清空了真实的数据
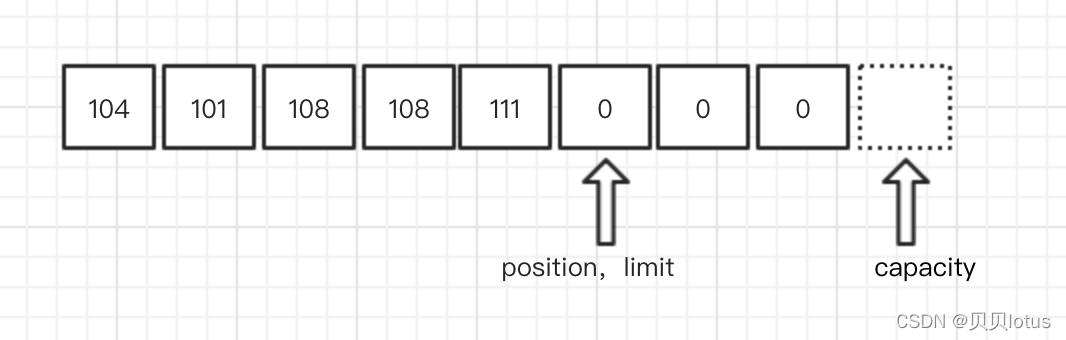
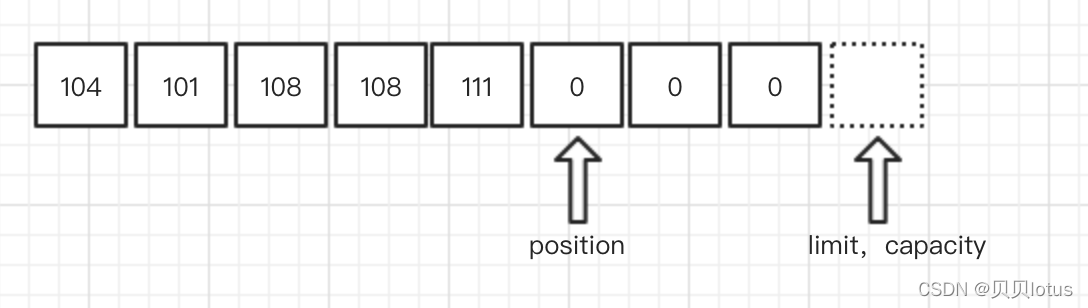
flip():
flip()方法将position置0,清除mark,然后将limit置为position的大小,通常在读写转换时使用。
|
二、Linux 虚拟内存、Java直接内存和内存映射
|
虚拟存储
|
CPU 是如何访问内存的?
CPU 采用 段基址 + 段内偏移地址 的方式访问内存,其中段基地址在程序启动的时候确认,段基地址还是绝对的物理地址,但可以同时运行多个程序了, 需要段基址寄存器和段内偏移地址寄存器来存储地址,最终将两个地址相加送上地址总线。
内存分段:一个内存段对应一个进程,解决多进程并发执行 (段基址)
相当于每个进程都会分配一个内存段,而且这个内存段需要是一块连续的空间,主存里维护着多个内存段,当某个进程需要更多内存,并且超出物理内存的时候,就需要将某个不常用的内存段换到硬盘上,等有充足内存的时候在从硬盘加载进来,也就是 swap 。每次交换都需要操作整个段的数据。
内存分页:解决内存空间利用率低,充分利用非连续的地址空间 (段内偏移地址)
首先连续的地址空间是很宝贵的,例如一个 50M 的内存,在内存段之间有空隙的情况下,将无法支持 5 个需要 10M 内存才能运行的程序,如何才能让段内地址不连续呢? 答案是内存分页。
在保护模式下,每一个进程都有自己独立的地址空间,所以段基地址是固定的,只需要给出段内偏移地址就可以了,而这个偏移地址称为线性地址,线性地址是连续的,而内存分页将连续的线性地址和和分页后的物理地址相关联,这样逻辑上的连续线性地址可以对应不连续的物理地址。物理地址空间可以被多个进程共享,而这个映射关系将通过页表( page table)进行维护。 标准页的尺寸一般为 4KB ,分页后,物理内存被分成若干个 4KB 的数据页,进程申请内存的时候,可以映射为多个 4KB 大小的物理内存,而应用程序读取数据的时候会以页为最小单位,当需要和硬盘发生交换的时候也是以页为单位。
总结:
1> 一个进程 对应 一个内存段, 当某个进程申请空间剩余内存不够分配时,会发生swap,将不常用内存段放到硬盘中,这块内存空间先给这个进程用,等到后面内存充足,再硬盘中备份的那个内存段加载回内存中。
2> 一个内存段由多个(4kb)内存页组成,进程IO读写操作或swap时是以页为最小单位。IO读写操作空间不够时,也是和硬盘swap。
虚拟存储:简化进程内存管理,保护进程不被其他进程破坏
现代计算机多采用虚拟存储技术,虚拟存储让每个进程以为自己独占整个内存空间,其实这个虚拟空间是主存和磁盘的抽象,这样的好处是,每个进程拥有一致的虚拟地址空间,简化了内存管理,进程不需要和其他进程竞争内存空间。因为他是独占的,也保护了各自进程不被其他进程破坏,
另外,他把主存看成磁盘的一个缓存,主存中仅保存活动的程序段和数据段,当主存中不存在数据的时候发生缺页中断,然后从磁盘加载进来,当物理内存不足的时候会发生 swap 到磁盘。页表保存了虚拟地址和物理地址的映射,页表是一个数组,每个元素为一个页的映射关系,这个映射关系可能是和主存地址,也可能和磁盘,页表存储在主存,我们将存储在高速缓冲区cache 中的页表称为快表 TLAB 。
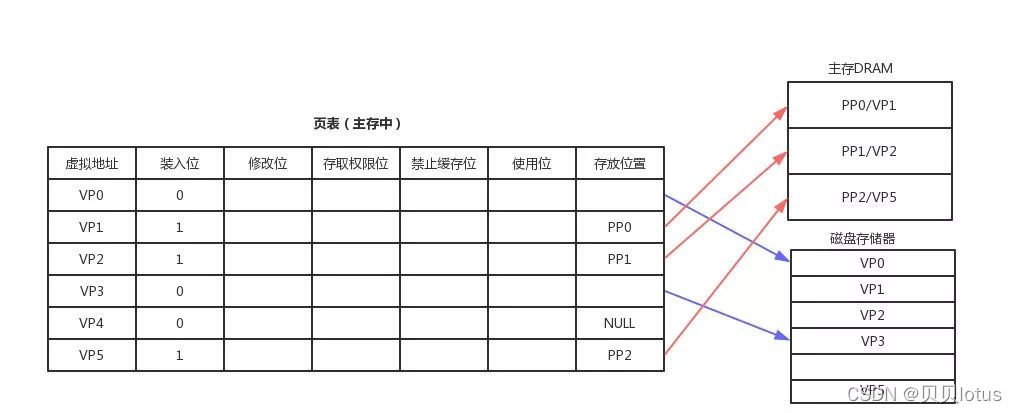
装入位:表示对于页是否在主存,如果为0,数据还在磁盘
存放位置 :建立虚拟页和物理页的映射,用于地址转换,如果为null表示是一个未分配页
修改位:用来存储数据是否修改过
权限位:用来控制是否有读写权限
禁止缓存位:主要用来保证 cache 主存 磁盘的数据一致性
|
|
Java 读取文件方式
|
读取文件的流程:
标准IO操作方式:先通过系统调用从磁盘读取数据,存入操作系统的内核缓冲区,然后在从内核缓冲区拷贝到用户空间。 非直接缓冲区
内存映射文件方式:而是将磁盘文件直接映射到用户的虚拟存储空间中,通过页表维护虚拟地址到磁盘的映射,通过内存映射的方式读取文件的好处有,因为减少了从内核缓冲区到用户空间的拷贝,直接从磁盘读取数据到内存(主存中所占的用户空间),减少了系统调用的开销,对用户而言,仿佛直接操作的磁盘上的文件,另外由于使用了虚拟存储,所以不需要连续的主存空间来存储数据。 直接缓冲区 直接内存映射技术
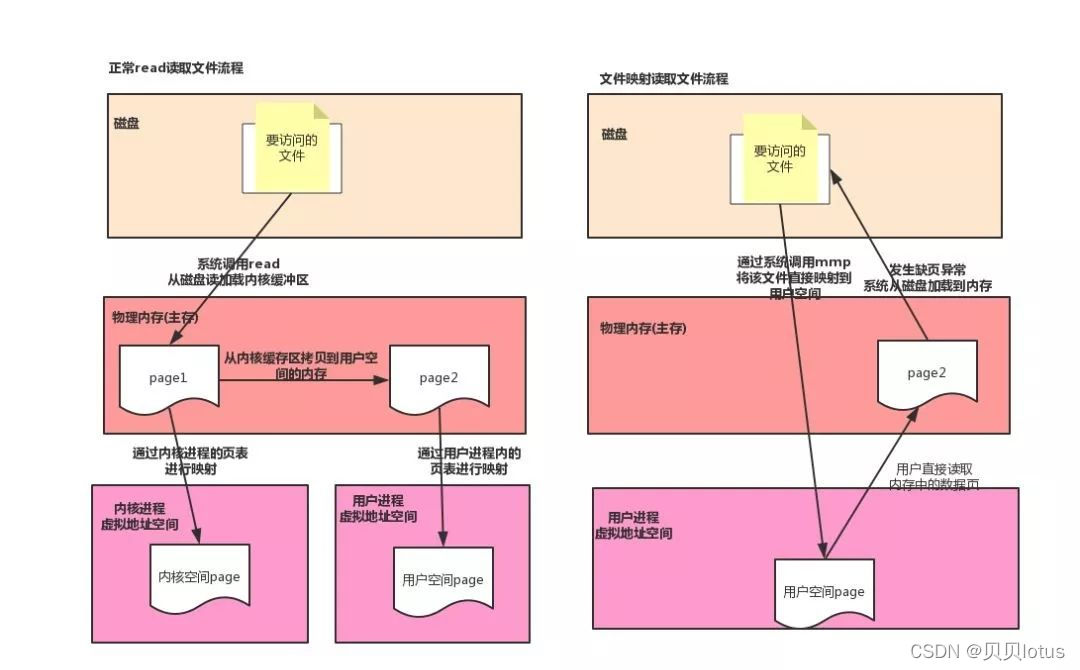
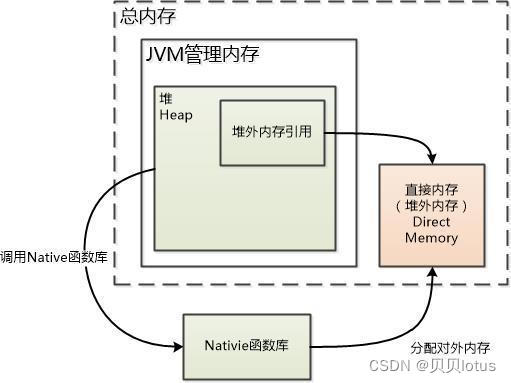
在 Java NIO 中,使用MappedByteBuffer 实现内存映射,Java程序将这个缓冲区建立在一个JVM堆外内存(即,JVM直接内存/直接缓冲区)中
直接将用户空间中的一部分区域(一些内存页,在JVM直接内存中)与文件对象建立映射关系(用户进程所占内存中部分区域的虚拟地址与磁盘文件的物理地址映射),在映射完之后,并没有立即占有物理内存,而是访问数据页的时候,先查页表,发现要访问的虚拟地址对应的物理地址中没有数据,发起缺页异常,然后从磁盘将数据加载进内存。就好像直接从内存中读、写文件一样,速度当然快了。
所以一些对实时性要求很高的中间件,例如rocketmq,消息存储在一个大小为1G的文件中,为了加快读写速度,会将这个文件映射到内存后,在每个页写一比特数据,这样就可以把整个1G文件都加载进内存,在实际读写的时候就不会发生缺页了,这个在rocketmq内部叫做文件预热。
内存映射IO原理: 利用PC虚拟存储,CPU访问内存的特点:当通过虚拟地址访问数据时,发现页表对应的物理地址不是主存地址而是磁盘地址(主存中读不到数据)时,产生缺页异常,CPU就会把数据从磁盘加载进主存中。 完成将磁盘文件数据加载到用户空间中的效果(缺页异常自动引起的磁盘文件到主存的加载/拷贝)
在内存映射文件的时候将某一段的虚拟地址和文件对象的某一部分建立起映射关系,此时并没有拷贝数据到内存中去,而是当进程代码第一次引用这段虚拟地址时,触发了缺页异常,这时候OS根据映射关系直接将文件的相关部分数据拷贝到进程的用户私有空间中去,当有操作第N页数据的时候重复这样的OS页面调度程序操作。原来内存映射文件的效率比标准IO高的重要原因就是因为少了把数据拷贝到OS内核缓冲区这一步,数据直接被拷贝到进程的地址空间中。
File file = new File("E:\\download\\office2007pro.chs.ISO");
FileInputStream in = new FileInputStream(file);
FileChannel channel = in.getChannel();
MappedByteBuffer buff = channel.map(FileChannel.MapMode.READ_ONLY, 0,channel.size());
按照jdk文档的官方说法,内存映射文件属于JVM中的直接缓冲区,还可以通过 ByteBuffer.allocateDirect() ,即DirectMemory的方式来创建直接缓冲区。他们相比基础的 IO操作来说就是少了中间缓冲区的数据拷贝开销。同时他们属于JVM堆外内存,不受JVM堆内存大小的限制。
注:内存/主存指的是内存条(独立于CPU的存储设备)
|
|
总结(面试)
|
1. 正常读取文件流程:使用非直接缓冲区
首先用户程序通过系统调用向cpu发出IO请求,cpu产生IO中断,回收用户进程cpu资源和阻塞 (pend) 进程,将用户进程的现场信息保存到用户空间中,cpu根据IO请求,抛出一个线程来调用内核程序对硬盘等外部设备进行读取数据,将数据先copy到内核程序的缓存空间中,再从内核缓存空间copy到用户程序的缓存空间,结束IO操作以后,将被阻塞的用户进程重新加到就绪队列等待cpu调度(时间片轮转法),将用户进程的现场信息缓存拉取回cpu,还原进程现场,继续执行用户进程
2. 以内存映射方式读取文件流程:使用直接缓冲区
实现原理:Java程序在JVM堆外内存(JVM直接内存/直接缓冲区)中建立MappedByteBuffer缓冲区,将缓冲区所在区域的虚拟地址与磁盘文件物理地址相映射( 硬盘上文件 的位置与进程 逻辑地址空间中 一块大小相同的区域之间的一一对应),映射后,缓冲区没有立即占用物理内存空间,此时JVM直接内存中还没有数据,当第一次访问缓冲区对象时,查看页表,发现缓冲区对象虚拟地址对应的物理地址不在内存中,而在磁盘中,引起缺页异常,cpu立即将文件数据从磁盘中加载到内存中,此时完成了从磁盘读取文件到用户空间中的功能。
优势:减少了内核空间到用户空间的拷贝,读取磁盘中的文件到内存中,就像直接在内存中读写文件一样,速度比第一种快多了。而且使用虚拟存储的方式,可以使用不连续的内存空间,降低内存空间资源的浪费。
|
三、回调
|
什么是回调函数?
|
编程分为两类:系统编程(system programming)和应用编程(application programming)。所谓系统编程,简单来说,就是编写库;而应用编程就是利用写好的各种库来编写具某种功用的程序,也就是应用。系统程序员会给自己写的库留下一些接口,即API(application programming interface,应用编程接口),以供应用程序员使用。所以在抽象层的图示里,库位于应用的底下。
当程序跑起来时,一般情况下,应用程序(application program)会时常通过API调用库里所预先备好的函数(系统调用)。但是有些库函数(library function)却要求应用先传给它一个函数,好在合适的时候调用,以完成目标任务。这个被传入的、后又被调用的函数就称为回调函数(callback function)。
打个比方,有一家旅馆提供叫醒服务,但是要求旅客自己决定叫醒的方法。可以是打客房电话,也可以是派服务员去敲门,睡得死怕耽误事的,还可以要求往自己头上浇盆水。这里,“叫醒”这个行为是旅馆提供的,相当于库函数,但是叫醒的方式是由旅客决定并告诉旅馆的,也就是回调函数。而旅客告诉旅馆怎么叫醒自己的动作,也就是把回调函数传入库函数的动作,称为登记回调函数(to register a callback function)。如下图所示(图片来源:维基百科):
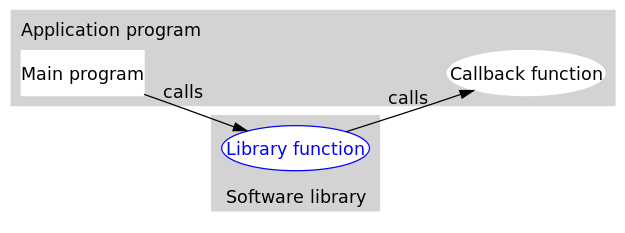
可以看到,回调函数通常和应用处于同一抽象层(因为传入什么样的回调函数是在应用级别决定的)。而回调就成了一个高层调用底层,底层再回过头来调用高层的过程。(我认为)这应该是回调最早的应用之处,也是其得名如此的原因。
总结:
1. 应用程序 通过 系统程序员提供库(即,内核程序)的访问接口API(系统调用) 间接调用 库函数,实际执行库函数的是库中的主函数
2. 调用时,应用程序需要将回调函数作为系统调用的参数传入 (高层调用底层)
3. 库函数中需要执行由应用程序实现/编写的回调函数 (底层调用高层)
回调机制的优势
从上面的例子可以看出,回调机制提供了非常大的灵活性。请注意,从现在开始,我们把图中的库函数改称为中间函数了,这是因为回调并不仅仅用在应用和库之间。任何时候,只要想获得类似于上面情况的灵活性,都可以利用回调。
这种灵活性是怎么实现的呢?乍看起来,回调似乎只是函数间的调用,但仔细一琢磨,可以发现两者之间的一个关键的不同:在回调中,我们利用某种方式,把回调函数像参数一样传入中间函数。可以这么理解,在传入一个回调函数之前,中间函数是不完整的。换句话说,程序可以在运行时,通过登记不同的回调函数,来决定、改变中间函数的行为。这就比简单的函数调用要灵活太多了。请看下面这段Python写成的回调的简单示例:
`even.py`
#回调函数1
#生成一个2k形式的偶数
def double(x):
return x * 2
#回调函数2
#生成一个4k形式的偶数
def quadruple(x):
return x * 4
`callback_demo.py`
from even import *
#中间函数
#接受一个生成偶数的函数作为参数
#返回一个奇数
def getOddNumber(k, getEvenNumber):
return 1 + getEvenNumber(k)
#起始函数,这里是程序的主函数
def main():
k = 1
#当需要生成一个2k+1形式的奇数时
i = getOddNumber(k, double)
print(i)
#当需要一个4k+1形式的奇数时
i = getOddNumber(k, quadruple)
print(i)
#当需要一个8k+1形式的奇数时
i = getOddNumber(k, lambda x: x * 8)
print(i)
# 类似于API 访问接口
if __name__ == "__main__":
main()
#运行`callback_demp.py`,输出如下:
# 3
# 5
# 9
易被忽略的第三方
中间函数和回调函数是回调的两个必要部分,不过人们往往忽略了回调里的第三方,就是中间函数的调用者。绝大多数情况下,这个调用者可以和程序的主函数等同,我这里把它称为起始函数。
给中间函数传入什么样的回调函数,是在起始函数里决定的。实际上,回调并不是“你我”两方的互动,而是ABC的三方联动。
回调实际上有两种:阻塞式回调和延迟式回调。两者的区别在于:阻塞式回调里,回调函数的调用一定发生在起始函数返回之前;而延迟式回调里,回调函数的调用有可能是在起始函数返回之后。
注意:上述所举的示例为阻塞式回调
回调说明
callback 一词本来用于打电话。你可以打电话(call)给别人,也可以留下电话号码,让别人回电话(callback)。call 和 callback 在计算机领域翻译成“调用”和“回调”。
回调函数是你写一个函数,让预先写好的系统来调用。你调用系统的函数,是直调。让系统调用你的函数,就是回调。
--------------------------------
回调函数可以看成,让别人做事,传进去的额外信息。
A 让 B 做事,根据粒度不同,可以理解成 A 函数调用 B 函数,或者 A 类使用 B 类,或者 A 组件使用 B 组件等等。反正就是 A 叫 B 做事。
当 B 做这件事情的时候,自身的需要的信息不够,而 A 又有。就需要 A 从外面传进来,或者 B 做着做着再向外面申请。对于 B 来说,一种被动得到信息,一种是主动去得到信息。有些人给这两种方式一个术语,叫信息的压送( push),和信息的拉取( pull)。 这两种方式对应这两种回调:阻塞式回调和延迟式回调
A "callback" is any function that is called by another function which takes the first function as a parameter. (在一个函数中调用另外一个函数就是callback)
|
|
Java写成的回调的简单示例
|
// 优化方式一:策略设计模式 + 匿名内部类/Lambda表达式 方式创建自定义函数式接口MyPredicate<T>的实现类对象
// 中间函数
public static List<Employee> filterEmployee(List<Employee> list,MyPredicate<Employee> mp) {
List<Employee> emps = new ArrayList<>();
for (Employee e : list) {
if (mp.test(e)) {
emps.add(e);
}
}
return emps;
}
// 测试程序 主函数(起始函数)
@Test
public void test5() {
// 匿名内部类
List<Employee> list2 = Java8NewTest.filterEmployee(this.employees, new MyPredicate<Employee>() {
// 回调函数
@Override
public boolean test(Employee e) {
return e.getSalary()>50000;
}
});
list2.forEach(System.out::println);
// Lambda表达式
// Lambda表达式只有一句时可以省{return ;}
// List<Employee> list = TestLambda1.filterEmployee(this.employees,(t) -> {return t.getAge()>=35;});
List<Employee> list = Java8NewTest.filterEmployee(this.employees,(t) -> t.getAge()>=35);
list.forEach(System.out::println);
System.out.println();
}
中间函数:filterEmployee(List<Employee> list,MyPredicate<Employee> mp) :测试程序中调用中间函数,并向中间函数传入参数:回调函数
回调函数:MyPredicate<Employee> mp.test():MyPredicate接口的抽象方法
起始函数:test5() : 相当于程序主函数
|
四、进程与线程状态
|
中断
|
指计算机运行过程中,出现某些意外情况需主机干预时,机器能自动停止正在运行的程序并转入处理新情况的程序,处理完毕后又返回原被暂停的程序继续运行。
|
|
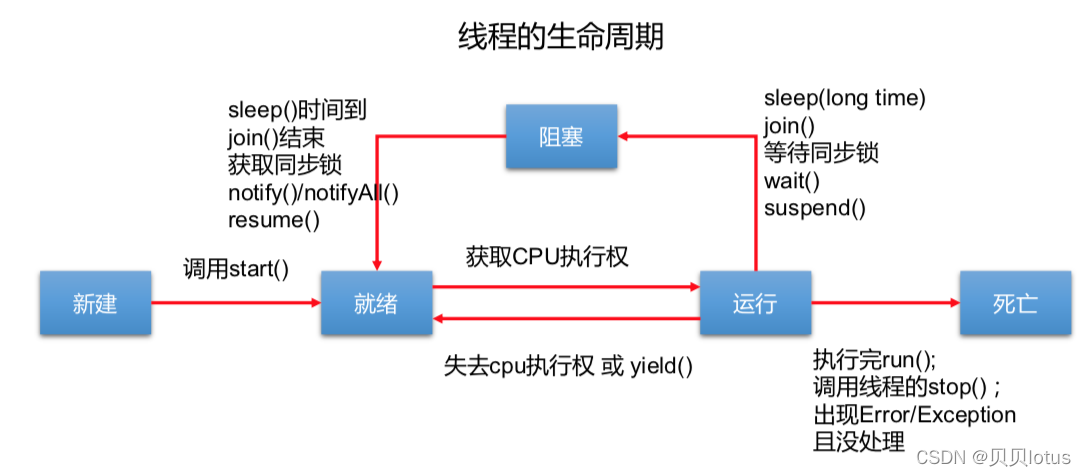
线程状态转换图
|
|
|
阻塞和挂起的区别
|
线程与进程的阻塞
线程
在运行的过程中因为某些原因而发生阻塞,阻塞状态的线程的特点是:
该线程放弃CPU的使用,暂停运行
,只有等到导致阻塞的原因消除之后才恢复运行。或者是被其他的线程中断,该线程也会退出阻塞状态,同时抛出InterruptedException。
正在执行的进程
由于发生某时间(如I/O请求、申请缓冲区失败等)暂时无法继续执行。此时引起进程调度,OS把处理机分配给另一个就绪进程,而让受阻进程处于暂停状态,一般将这种状态称为阻塞状态。
进程的挂起
挂起
进程在操作系统中可以定义为
暂时被淘汰出内存
的进程,机器的资源是有限的,在资源不足的情况下,操作系统对在内存中的程序进行合理的安排,其中有的进程被暂时调离出内存,当条件允许的时候,会被操作系统再次调回内存,重新进入等待被执行的状态即就绪态,系统在超过一定的时间没有任何动作
共同点:
1. 进程都暂停执行
进入阻塞状态
2. 进程都释放CPU,即两个过程都会涉及上下文切换
不同点:
1.
对系统资源占用不同:虽然都释放了CPU,但阻塞的进程仍处于内存中,而挂起的进程通过“对换”技术被换出到外存(磁盘)中。
2.
发生时机不同:
阻塞一般在进程等待资源(IO资源、信号量等)时发生;
挂起是由于用户和系统的需要,例如:
a. 终端用户需要暂停程序研究其执行情况或对其进行修改
用于
程序调试
中的条件中断,当出现某个条件的情况下挂起,然后进行单步调试。
b. OS为了提高内存利用率需要将暂时不能运行的进程(处于就绪或阻塞队列的进程)调出到磁盘
3.
恢复时机不同:
阻塞要在等待的资源得到满足(例如获得了锁)后,才会进入就绪状态,等待被调度而执行;
被挂起的进程由将其
挂起的对象(如用户、系统)在时机符合时(调试结束、被调度进程选中需要重新执行)将其主动
激活.
suspend和resume相当于播放器的暂停和恢复
阻塞的原因:
线程中的阻塞
、Socket客户端的阻塞、
Socket服务器端的阻塞
。
一般线程中的阻塞:
A、线程执行了Thread.
sleep
(int millsecond);方法,当前线程放弃CPU,睡眠一段时间,然后再恢复执行
B、线程
执行一段同步代码
,但是
尚且无法获得相关的同步锁
,只能进入阻塞状态,等到获取了同步锁,才能恢复执行。
C、线程
执行
了一个对象的
wait()
方法,直接进入阻塞状态,等待其他线程执行notify()或者notifyAll()方法。
wait ----> notify 等待和唤醒
D、线程执行某些
IO操作
,因为等待相关的资源而进入了阻塞状态。比如说监听system.in,但是尚且没有收到键盘的输入,则进入阻塞状态。
Socket客户端的阻塞:
A、请求与服务器连接时,调用connect方法,进入阻塞状态,直至连接成功。
B、
当从Socket输入流读取数据时,在读取足够的数据之前会进入阻塞状态
。比如说通过BufferedReader类使用readLine()方法时,在没有读出一行数据之前,数据量就不算是足够,会处在阻塞状态下。
C、调用Socket的setSoLinger()方法关闭了Socket延迟,
当执行Socket的close方法时
,会进入阻塞状态,直到底层Socket发送完所有的剩余数据
Socket服务器的阻塞:
A、
线程执行ServerSocket的accept()方法
,等待客户的连接,直到接收到客户的连接,才从accept方法中返回一个Socket对象
B、
从Socket输入流读取数据时,如果输入流没有足够的数据,就会进入阻塞状态
D、
线程向Socket的输出流写入一批数据,可能进入阻塞状态
当程序阻塞时,会降低程序的效率,于是人们就希望能引入非阻塞的操作方法。
所谓非阻塞方法,就是指当线程执行这些方法时,如果操作还没有就绪,就立即返回,不会阻塞着等待操作就绪。Java.nio 提供了这些支持非阻塞通信的类。
挂起的原因
(1)
终端用户的请求
。当终端用户在自己的程序运行期间发现有可疑问题时,希望暂停使自己的程序静止下来。亦即,使正在执行的进程暂停执行;若此时用户进程正处于就绪状态而未执行,则该进程暂不接受调度,以便用户研究其执行情况或对程序进行修改。我们把这种静止状态成为“挂起状态”。
(2)
父进程的请求。有时父进程希望挂起自己的某个子进程,以便考察和修改子进程,或者协调各子进程间的活动。
(3)
负荷调节的需要。当实时系统中的工作负荷较重,已可能影响到对实时任务的控制时,可由系统把一些不重要的进程挂起,以保证系统能正常运行。
(4)
操作系统的需要。操作系统有时希望挂起某些进程,以便检查运行中的资源使用情况或进行记账。
(5)
对换的需要。为了缓和内存紧张的情况,将内存中处于阻塞状态的进程换至外存上。
操作系统中睡眠、阻塞、挂起的区别形象解释:
操作系统中睡眠、阻塞、挂起的区别形象解释:
首先这些术语都是对于
线程来说的。对线程的控制就好比你控制了一个雇工为你干活。你对雇工的控制是通过编程来实现的。
挂起
线程的意思就是你对主动对雇工说:“你睡觉去吧,用着你的时候我主动去叫你,然后接着干活”。
使线程
睡眠
的意思就是你主动对雇工说:“你睡觉去吧,某时某刻过来报到,然后接着干活”。
线程
阻塞
的意思就是,你突然发现,你的雇工不知道在什么时候没经过你允许,自己睡觉了,但是你不能怪雇工,因为本来你让雇工扫地,结果扫帚被偷了或被邻居家借去了,你又没让雇工继续干别的活,他就只好睡觉了。至于扫帚回来后,雇工会不会知道,会不会继续干活,你不用担心,雇工一旦发现扫帚回来了,他就会自己去干活的。因为雇工受过良好的培训。这个培训机构就是操作系统。
|

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









