







一、算法复杂度
算法复杂度分为时间复杂度和空间复杂度。
作用:
时间复杂度是指执行算法所需要的计算工作量;
而空间复杂度是指执行这个算法所需要的内存空间。
(算法的复杂性体现在运行该算法时的计算机所需资源的多少上,计算机资源最重要的是时间和空间(即寄存器)资源,因此复杂度分为时间和空间复杂度)。
简单来说,时间复杂度指的是语句执行次数,空间复杂度指的是算法所占的存储空间
二、时间复杂度
1、计算时间复杂度的方法:
1、用常数1代替运行时间中的所有加法常数
2、修改后的运行次数函数中,只保留最高阶项
3、去除最高阶项的系数
2、按数量级递增排列,常见的时间复杂度有:
常数阶O(1),对数阶O(log2n),线性阶O(n),
线性对数阶O(nlog2n),平方阶O(n^2),立方阶O(n^3),…,
k次方阶O(n^k),指数阶O(2^n)。
随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
举个栗子:
sum = n*(n+1)/2; //时间复杂度O(1)
for(int i = 0; i < n; i++){
printf("%d ",i);
}
//时间复杂度O(n)
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
printf("%d ",i);
}
}
//时间复杂度O(n^2)
for(int i = 0; i < n; i++){
for(int j = i; j < n; j++){
printf("%d ",i);
}
}
//运行次数为(1+n)*n/2
//时间复杂度O(n^2)
int i = 1, n = 100;
while(i < n){
i = i * 2;
}
//设执行次数为x. 2^x = n 即x = log2n
//时间复杂度O(log2n)
3、最坏时间复杂度和平均时间复杂度
最坏情况下的时间复杂度称最坏时间复杂度。一般不特别说明,讨论的时间复杂度均是最坏情况下的时间复杂度。
这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的上界,这就保证了算法的运行时间不会比任何更长。
平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,算法的期望运行时间。设每种情况的出现的概率为pi,平均时间复杂度则为sum(pi*f(n))
常用排序算法的时间复杂度
最差时间分析 平均时间复杂度 稳定度 空间复杂度
冒泡排序 O(n2) O(n2) 稳定 O(1)
快速排序 O(n2) O(n*log2n) 不稳定 O(log2n)~O(n)
选择排序 O(n2) O(n2) 不稳定 O(1)
二叉树排序 O(n2) O(n*log2n) 不稳定 O(n)
插入排序 O(n2) O(n2) 稳定 O(1)
堆排序 O(n*log2n) O(n*log2n) 不稳定 O(1)
希尔排序 O O 不稳定 O(1)
三、空间复杂度
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度,记做S(n)=O(f(n))。
对于一个算法来说,空间复杂度和时间复杂度往往是相互影响的。当追求一个较好的时间复杂度时,可能会使空间复杂度的性能变差,即可能导致占用较多的存储空间;反之,当追求一个较好的空间复杂度时,可能会使时间复杂度的性能变差,即可能导致占用较长的运行时间。
有时我们可以用空间来换取时间以达到目的。
转载自:
时间复杂度和空间复杂度
========================================================================
*1、关于运行次数为(1+n)n/2的问题
答:
先看内部循环,
当i=0时,语句运行次数为n;
当i=1时,语句运行次数为n-1;
…
当i=n-1时,语句运行次数为1。
那么总的运行次数就是n+(n-1)+…+1
根据高斯算法,总的运行次数就是:(n+1)*n/2
2、其他常见复杂度
除了常数阶、线性阶、平方阶、对数阶,还有如下时间复杂度:
f(n)=nlogn时,时间复杂度为O(nlogn),可以称为nlogn阶。
f(n)=n³时,时间复杂度为O(n³),可以称为立方阶。
f(n)=2ⁿ时,时间复杂度为O(2ⁿ),可以称为指数阶。
f(n)=n!时,时间复杂度为O(n!),可以称为阶乘阶。
f(n)=(√n时,时间复杂度为O(√n),可以称为平方根阶。
3、常用的时间复杂度按照耗费的时间从小到大依次是:
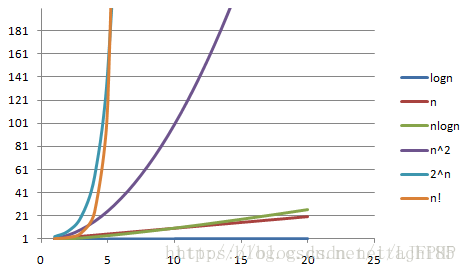
其中x轴代表n值,y轴代表T(n)值(时间复杂度)。T(n)值随着n的值的变化而变化,其中可以看出O(n!)和O(2ⁿ)随着n值的增大,它们的T(n)值上升幅度非常大,而O(logn)、O(n)、O(nlogn)随着n值的增大,T(n)值上升幅度则很小。
O(1)<O(logn)<O(n)<O(nlogn)<O(n²)<O(n³)<O(2ⁿ)<O(n!)
转载自:
算法(一)时间复杂度
========================================================================
例子:
(1) for(i=1;i<=n;i++) //循环了n*n次,当然是O(n^2)
for(j=1;j<=n;j++)
s++;
(2)for(i=1;i<=n;i++) //循环了(n+n-1+...+1)≈(n^2)/2 ,同上
for(j=i;j<=n;j++)
s++;
(4) i=1;k=0;
while(i<=n-1){
k+=10*i;
i++; }
//循环了
//n-1≈n次,所以是O(n)
(5) for(i=1;i<=n;i++)
for(j=1;j<=i;j++)
for(k=1;k<=j;k++)
x=x+1;
//循环了(1^2+2^2+3^2+...+n^2)=n(n+1)(2n+1)/6≈(n^3)/3,
//即O(n^3)
(6)
x=91; y=100;
while(y>0) if(x>100) {x=x-10;y--;} else x++;
//T(n)=O(1),与n无关
(7)i=n-1;
while(i>=0&&(A[i]!=k))
i--;
return i;
//此算法中的语句(3)的频度不仅与问题规模n有关,还与输入实例中A的各元素取值及K的取值有关: ①若A中没有与K相等的元素,则语句(3)的频度f(n)=n; ②若A的最后一个元素等于K,则语句(3)的频度f(n)是常数0。
综上:
1、取决于执行次数最多的语句,如当有若干个循环语句时,算法的时间复杂度是由嵌套层数最多的循环语句中最内层语句的频度f(n)决定的。(这部分,代表的意思是当有多个循环嵌套的时候,让最内层的循环次数最少会好一些)
2、如果算法的执行时间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)
3、算法的时间复杂度不仅仅依赖于问题的规模,还与输入实例的初始状态有关。
转载链接:
关于时间复杂度的详解
end

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









