







 本文深入解析XML的基础知识、用途及其与HTML的区别,详细介绍了XML的语法规范、DOM和SAX解析技术,并通过Dom4j和XPath示例演示如何高效解析和查询XML文档。
本文深入解析XML的基础知识、用途及其与HTML的区别,详细介绍了XML的语法规范、DOM和SAX解析技术,并通过Dom4j和XPath示例演示如何高效解析和查询XML文档。
笔记大纲
- XML简介
- XML用途
- XML基础语法
- XML解析
- Xpath查询
1.XML简介
1.1.定义
XML即可扩展标记语言(eXtensible Markup Lanuage),由W3C组织发布,目前推荐遵守的是W3C组织于2000年发布的XML1.0规范。
1.2.XML与HTML区别
| 序号 | XML | HTML |
|---|---|---|
| 1 | 用来传输和存储数据 | 用来显示数据 |
| 2 | 无预定义标签,均自定义标签 | 均为预定义标签,无自定义标签 |
| 3 | 严格区分大小写 | 不区分大小写 |
2.XML用途
(1)配置文件,如:JavaWeb中的web.xml ;
(2)数据存储,如: Ajax;
(3)数据格式交换,如:保存关系型数据。
3.XML基础语法
3.1.语法规则
(1)XML声明要么不写,要写就写在第一行,并且前面无任何其他字符;
(2)严格区分大小写;
(3)标签不能以数字开头。
其他与HTML的语法一致!
回顾☛[01]JavaWeb之HTML与CSS基础–4.HTMT标签语法
3.2.XML文档组成

(1)XM声明
①version属性指定XML版本,固定是1.0;
②encoding指定的字符集,告诉解析器是什么样的字符集进行解
码,编码由编辑器决定。
(2)CDATA区
①当XML文档中需要写一些程序代码、SQL语句或其他不希望XML解析器进行解析的内容时,就可以写在CDATA区中;
②XML解析器会将CDATA区中的内容原封不动的输出;
③CDATA区的定义格式:<![CDATA[…]]>。
4.XML解析
4.0.XML介绍
(1)dom4j是一个开源XML解析包;
(2)dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件都采用dom4j,如Hibernate;
(3)使用dom4j开发,需导入dom4j相应的jar包dom4j-1.6.1.jar。
4.1.XML解析技术体系
DOM标准针对的是Java,SAX标准主要针对安卓!
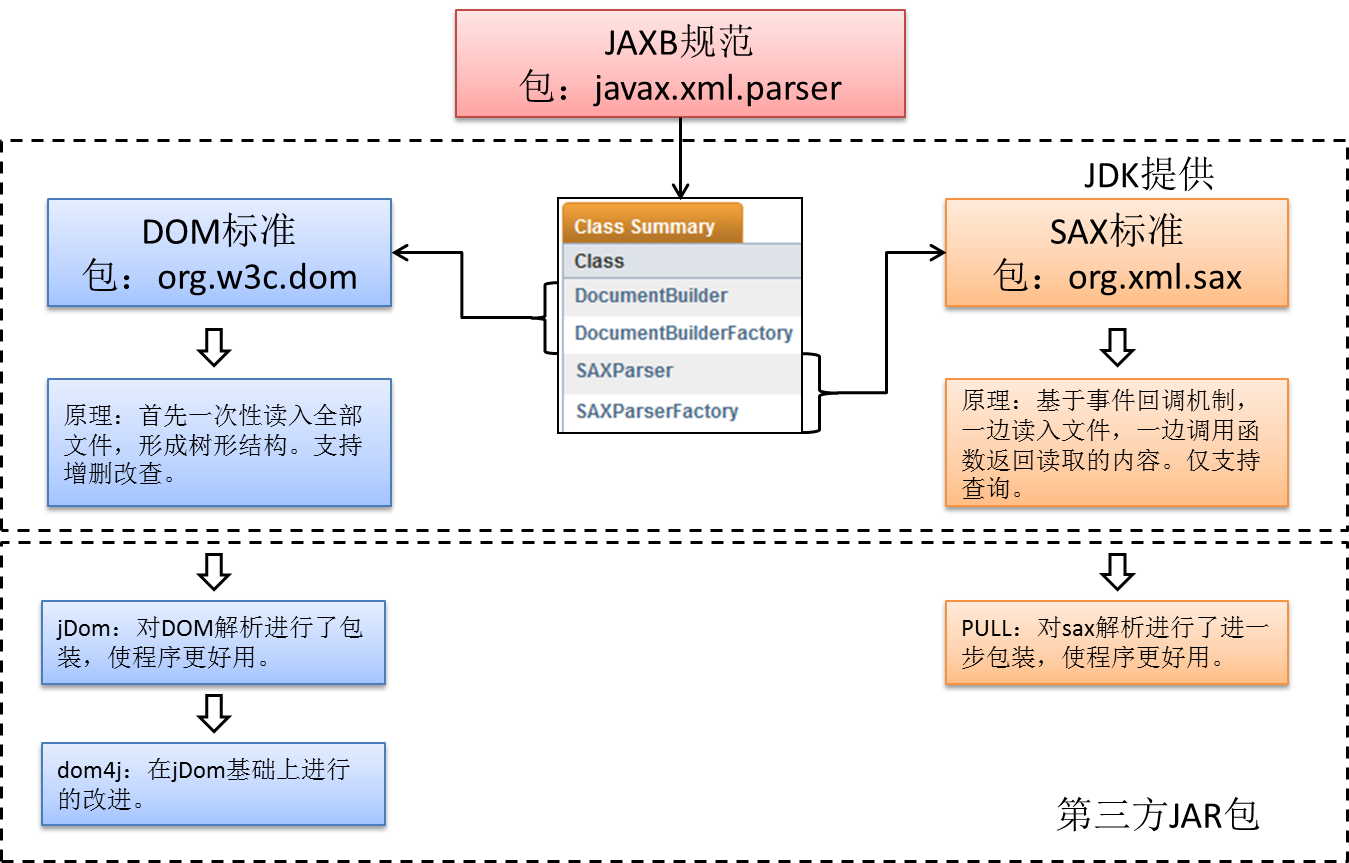
4.2.DOM和SAX比对
| 序号 | 比对 | DOM | SAX |
|---|---|---|---|
| 1 | 速度 | 需要一次性加载整个XML文档,然后将文档转换为DOM树,速度较差 | 顺序解析XML文档,无需将整个XML都加载到内存中,速度快 |
| 2 | 重复访问 | 将xml转换为DOM树后,在解析时,DOM树将常驻内存,可以重复访问 | 顺序解析XML文档,已解析过的数据,如果没保存,将不能获得,除非重新解析 |
| 3 | 内存要求 | 内存占用较大 | 内存占用率低 |
| 4 | 修改 | 即可读取文档内容,又可以修改 | 只能读取,不能修改 |
| 5 | 复杂度 | 完全面向对象的解析方式,容易使用 | 采用事件回调机制,通过事件的回调函数来解析XML文档,相对复杂 |
4.3.dom4j案例应用
(1)STS下的静态工程结构
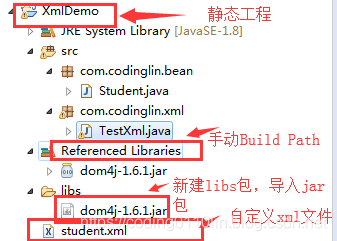
(2) 新建student.xml
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id="1">
<name>林大侠</name>
<age>18</age>
<post>Java开发工程师</post>
</student>
<student id="2">
<name>猪猪侠</name>
<age>19</age>
<post>大数据开发工程师</post>
</student>
<student id="3">
<name>键盘侠</name>
<age>19</age>
<post>实施开发工程师</post>
</student>
</students>
可以直接用浏览器打开student.xml文件:

新建javaBean–Student
package com.codinglin.bean;
public class Student {
private String id;
private String name;
private String age;
private String post;
public Student() {
super();
}
public Student(String id, String name, String age, String post) {
super();
this.id = id;
this.name = name;
this.age = age;
this.post = post;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
public String getPost() {
return post;
}
public void setPost(String post) {
this.post = post;
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + ", age=" + age + ", post=" + post + "]";
}
}
(1)STS下的静态工程结构
(2)新建测试类–TestXml【Dom4j解析关键步骤】
package com.codinglin.xml;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import com.codinglin.bean.Student;
public class TestXml {
public static void main(String[] args) {
try {
//(1)创建解析器
SAXReader reader = new SAXReader();
//(2)通过解析器将文件解析为Document
Document document = reader.read("student.xml");
//(3)通过document对象获取根元素
Element rootElement = document.getRootElement();
//通过document对象添加根元素
//Element rootElementNew = document.addElement("students");
//(4)通过根元素获取所有的子元素
List<Element> elements = rootElement.elements();
for (Element e : elements) {
//(5)获取属性值
String id =e.attributeValue("id");
//(6)获取文本值
String name =e.elementText("name");
String age=e.elementText("age");
String post=e.elementText("post");
Student stu = new Student(id,name,age,post);
System.out.println(stu);
}
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行结果:
Student [id=1, name=林大侠, age=18, post=Java开发工程师]
Student [id=2, name=猪猪侠, age=19, post=大数据开发工程师]
Student [id=3, name=键盘侠, age=19, post=实施开发工程师]
5.Xpath查询
5.1.Xpath介绍
(1)Path 是在 XML 文档中查找信息的语言;【高效率查找】
(2)2XPath通过元素和属性进行查找,简化了Dom4j查找节点的过程,是W3C组织发布的标准;
(3)使用XPath必须导入jaxen-1.1-beta-6.jar包;
两个重要方法:
①document.selectSingleNode("/students/student[@id=‘1’]")
②document.selectNodes("/students/student")
5.2.Xpath案例应用
(1)STS下的静态工程结构
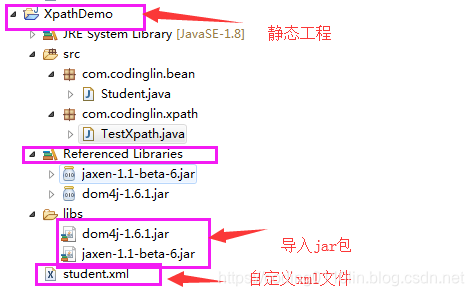
(2)新建测试类–TestXpath【Xpath解析关键步骤】,其他代码与XM部分相同!
package com.codinglin.xpath;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class TestXpath {
public static void main(String[] args) {
// TODO Auto-generated method stub
try {
// 创建解析器
SAXReader reader = new SAXReader();
// 通过解析器将文件解析为Document
Document document = reader.read("student.xml");
// Xpath解析
Element element = (Element) document.selectSingleNode("/students/student[@id='3']");
String id = element.attributeValue("id");
String name = element.elementText("name");
String age = element.elementText("age");
String post = element.elementText("post");
System.out.println("id=" + id + ",name=" + name + ",age=" + age + ",post=" + post);
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行结果:
id=3,name=键盘侠,age=19,post=实施开发工程师

☝上述分享来源个人总结,如果分享对您有帮忙,希望您积极转载;如果您有不同的见解,希望您积极留言,让我们一起探讨,您的鼓励将是我前进道路上一份助力,非常感谢!我会不定时更新相关技术动态,同时我也会不断完善自己,提升技术,希望与君同成长同进步!
☞本人博客:https://coding0110lin.blog.youkuaiyun.com/ 欢迎转载,一起技术交流吧!

















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









