







 本文介绍了Java中Set接口的基本概念及其实现类HashSet、LinkedHashSet、TreeSet的特点与应用场景。详细解释了不同Set实现如何保证元素的唯一性,以及它们之间的区别。
本文介绍了Java中Set接口的基本概念及其实现类HashSet、LinkedHashSet、TreeSet的特点与应用场景。详细解释了不同Set实现如何保证元素的唯一性,以及它们之间的区别。
简要介绍:
public interface Set<E> extends Collection<E>一个不包含重复元素的 collection。更确切地讲,set 不包含满足
e1.equals(e2)的元素对e1和e2,并且最多包含一个 null 元素。正如其名称所暗示的,此接口模仿了数学上的 set 抽象。在所有构造方法以及
add、equals和hashCode方法的协定上,Set接口还加入了其他规定,这些规定超出了从Collection接口所继承的内容。出于方便考虑,它还包括了其他继承方法的声明(这些声明的规范已经专门针对Set接口进行了修改,但是没有包含任何其他的规定)。对这些构造方法的其他规定是(不要奇怪),所有构造方法必须创建一个不包含重复元素的 set(正如上面所定义的)。 (引用JDK_API_1.6版本)
1.Set接口的基础特点
①Set这个接口没有扩展Collection的方法,但它的实现类们对Collection的方法更为严格;
②Set系列的集合中的元素是不能重复 ;
代码演示1:
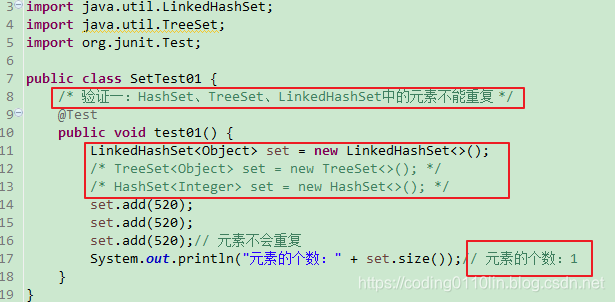
③Set和Collection一样,支持foreach、Iteratord迭代器;
④Set的实现类有:HashSet、TreeSet、LinkedHashList。
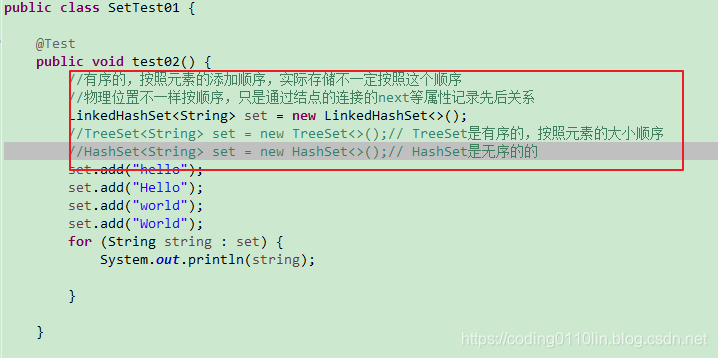
2.为什么我们不讨论Set的顺序?
因为Set有序无序有争议,从存储的结构、物理的结构来说,是无序的;从遍历的结果来说,是有序的,其中TreeSet是按照大小顺序,LinkedHashSet是按照添加的顺序。
代码演示2:
3.Set的不可重复性表现在哪?
①HashSet :添加到HashSet中的元素,不可重复,依赖于hashCode和equals方法;
代码演示3:
package com.daxia.case4;
import java.util.HashSet;
import org.junit.Test;
/**/
public class SetTest02 {
@Test
public void test02() {
// 此时泛型是Student,引用数据类型
HashSet<Student> set = new HashSet<>();
set.add(new Student("1", "大侠"));
set.add(new Student("1", "大侠"));
set.add(new Student("1", "大侠"));
/* 如果没有重写hashCode和equals方法,等价于"==" */
// System.out.println("元素的个数:"+set.size());//元素的个数:3
/* 如果重写hashCode和equals方法,就按重写的来比较 */
System.out.println("元素的个数:" + set.size());// 元素的个数:1
}
}
class Student {
private String id;
private String name;
public Student(String id, String name) {
super();
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((id == null) ? 0 : id.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (id == null) {
if (other.id != null)
return false;
} else if (!id.equals(other.id))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
②LinkedHashSet :添加到LinkedHashSet中的元素,不可重复,依赖于hashCode和equals方法;
代码演示4(原理同上):
@Test
public void test03() {
// 此时泛型是Student,引用数据类型
LinkedHashSet<Student> set = new LinkedHashSet<>();
set.add(new Student("1", "大侠"));
set.add(new Student("1", "大侠"));
set.add(new Student("1", "大侠"));
/* 如果没有重写hashCode和equals方法,等价于"==" */
// System.out.println("元素的个数:"+set.size());//元素的个数:3
/* 如果重写hashCode和equals方法,就按重写的来比较 */
System.out.println("元素的个数:" + set.size());// 元素的个数:1
}
③TreeSet:
(1)添加到TreeSet中的元素必须实现Comparble接口,元素不可重复调用compareTo()比较的,它认为大小相等的
就是重复的元素;
代码演示5:
public class SetTest02 {
@Test
public void test03() {
//如果学生的对象没有实现java.lang.comparable接口,就不能添加到TreeSet中
//TreeSet是要按元素的大小顺序存储和遍历,无法比较大小
TreeSet<Student> set = new TreeSet<>();
set.add(new Student(1, "大侠"));
set.add(new Student(1, "大侠"));
set.add(new Student(1, "大侠"));
System.out.println("元素的个数:" + set.size());// 元素的个数:1
}
}
class Student implements Comparable<Student> {
private int id;
private String name;
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public int compareTo(Student o) {
return this.id-o.id;
}
}
(2)如添加到TreeSet中的元素没有实现Comparable接口,或者实现Comparable接口的方式不满足当前的排序需
求,那么需要给TreeSet指定一个Comparator定制比较器对象。
代码演示6:
public class SetTest02 {
@Test
public void test03() {
// 如果学生的对象没有实现java.lang.comparable接口,
//指定一个<font color =red size=3>Comparator定制比较器</font>对象
TreeSet<Student> set = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getId() - o2.getId();
}
});
set.add(new Student(1, "大侠"));
set.add(new Student(1, "大侠"));
set.add(new Student(1, "大侠"));
System.out.println("元素的个数:" + set.size());// 元素的个数:1
}
}
class Student {
private int id;
private String name;
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
4.总结
①HashSet:依赖元素hashCode()和equals()方法,底层存储的是哈希表;
②TreeSet:依赖元素compareTo()和定制比较器compare(),只有当你要求元素按照大小
顺序(Comparable|Comparator),并不可重复,才使用它;
③LinkedHashSet:依赖元素hashCode()和equals()方法;它是HashSet的子类;比HashSet中的结点类型,多维
护了一个前后结点的引用。
(1)场景应用:
如果既要保证元素的添加的顺序(有序),又要保证元素不可重复,那么就选择LinkedHashSet;
如果不需要保证元素添加顺序(无序),只是不可重复,就用HashSet。因为如果你每次添加、删除的时
候,还要维护前后元素的关系,效率就比较低。
(2)Set系列其实本质上就是Map
①HashSet内部是HashMap,添加到HashSet中的元素是作为HashMap的key,value使用一个Object;
②TreeSet内部是TreeMap,添加到TreeSet中的元素是作为TreeMap的key,value使用一个Object;
③LinkedHashSet内部是LinkedHashMap,添加到LinkedHashSet中的元素是作为LinkedHashMap的key,value使用一个Object。
推荐阅读往期博文:
•JavaSE集合篇#Collection&Map等系列#结构关系图解
•JavaSE集合篇#List之实现类ArrayList&Vector&LinedList&Stack浅析
•JavaSE集合篇#Map集合之实现类HashMap&Hashtable&TreeMap&LinkedHashMap&Properties浅析
#轻松一刻

☝上述分享来源个人总结,如果分享对您有帮忙,希望您积极转载;如果您有不同的见解,希望您积极留言,让我们一起探讨,您的鼓励将是我前进道路上一份助力,非常感谢!我会不定时更新相关技术动态,同时我也会不断完善自己,提升技术,希望与君同成长同进步!
☞本人博客:https://coding0110lin.blog.youkuaiyun.com/ 欢迎转载,一起技术交流吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









