







 本文介绍了SparkSQL在大数据生态系统中的作用及其与Hive、Cassandra等组件的集成方式。此外,还详细阐述了SparkSQL中DataFrame、Dataset及RDD之间的转换关系。
本文介绍了SparkSQL在大数据生态系统中的作用及其与Hive、Cassandra等组件的集成方式。此外,还详细阐述了SparkSQL中DataFrame、Dataset及RDD之间的转换关系。
一、开发环境
1、hadoop-2.7.3
2、hive-1.2.2
3、spark-2.0.2
4、cassandra-3.11.2
5、jdk1.8.0_121
6、scala-2.12.3
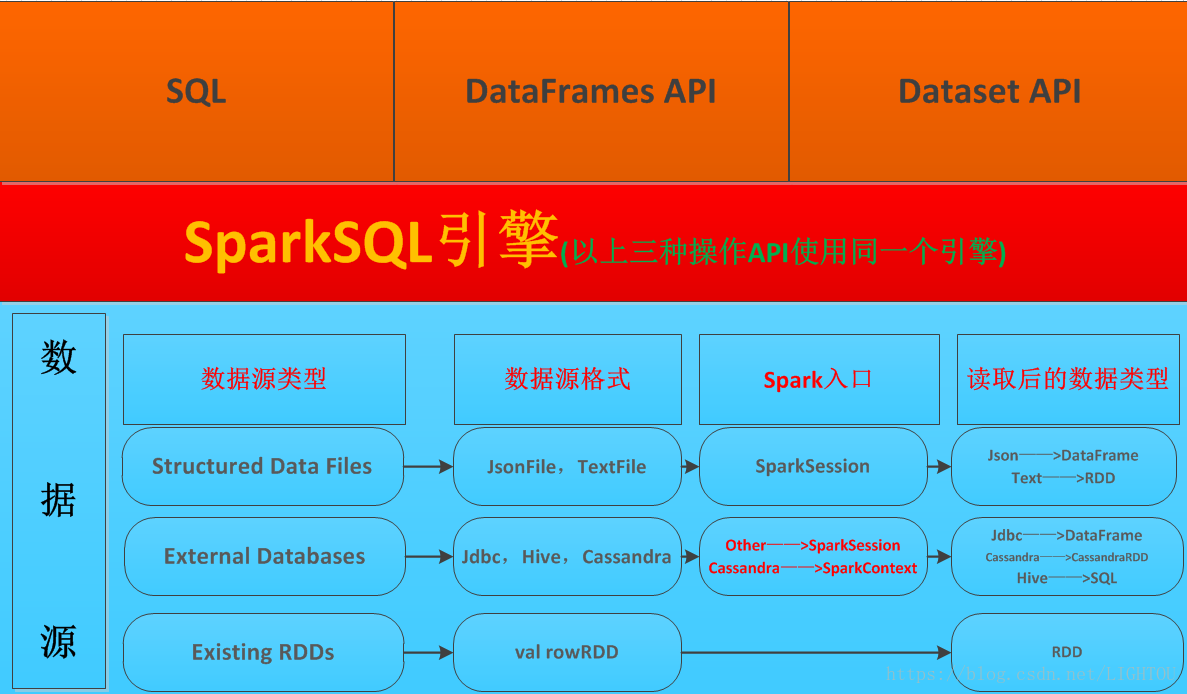
二、SparkSQL架构图
根据自己的理解绘制如下架构图,说明:
1、SparkSQL支持读取多种数据源
1.1 天然支持Hive,通过SparkSession.sql("sql语句")的方式直接操作hive表
1.2 支持jdbc以及json数据,通过SparkeSession.read.***方式读取,生成DataFrame
1.3 SparkSession.textFile()读取文本文件
1.4 通过SparkContext读取Cassandra生成CassandraRdd,利用spark-cassandra-connector驱动进行操作
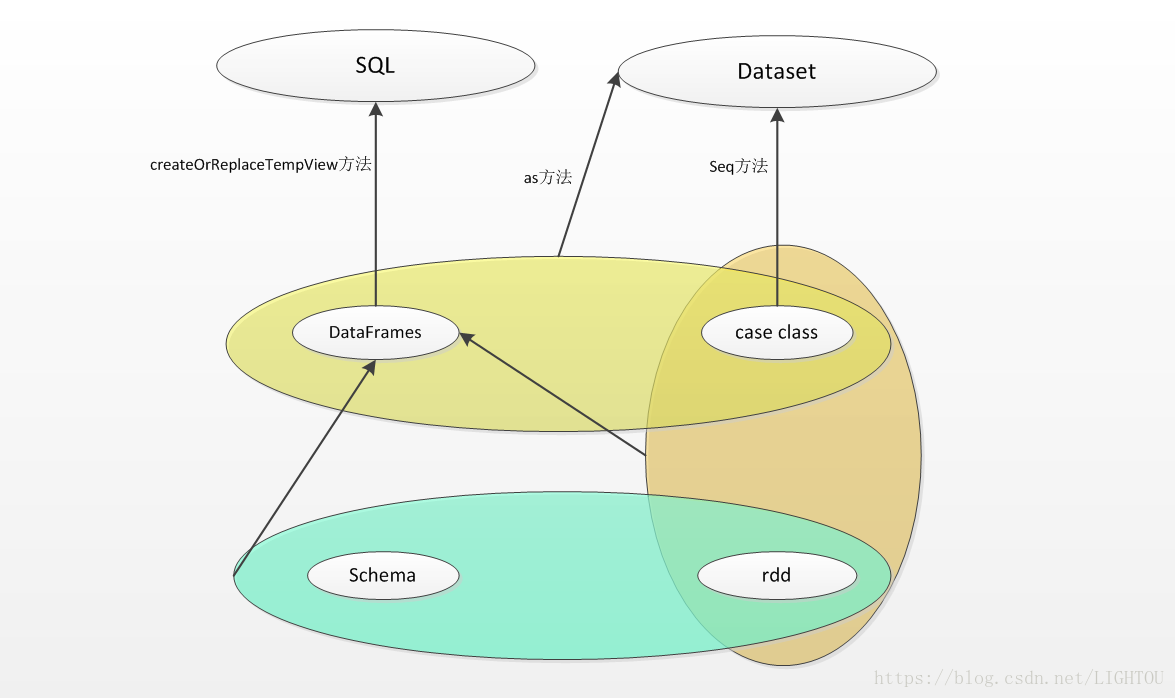
2、SparkSQL三种API关系以及转换方式
最开始接触SparkSQL难免被DataFrame、Dataset、RDD搞乱,这里记录一下自己理解的关系,图丑,勉强看:
2.1、RDD+Schema=DataFrame
2.2、RDD+case class=DataFrame
2.3、DataFrame as[case class] 生成 Dataset
2.4、case class 序列化 生成 Dataset
2.5、DataFrame 创建视图 生成SQL视图,SQL视图可以用SparkSession.sql("sql语句")方式操作


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









