







 本文深入探讨了Spark Streaming,一个基于Spark构建的高性能流处理框架。介绍了Spark Streaming的特点,如高吞吐量、容错处理,以及其DStream抽象,用于表示时间序列的数据流。文章详细讲解了Spark Streaming的架构,接收器如何处理数据并将其保存为RDD,以及如何通过DStream进行转换和输出操作。此外,还展示了如何实现实时分析端口、Kafka和Flume数据源的例子,以及Spark Streaming的运行流程。
本文深入探讨了Spark Streaming,一个基于Spark构建的高性能流处理框架。介绍了Spark Streaming的特点,如高吞吐量、容错处理,以及其DStream抽象,用于表示时间序列的数据流。文章详细讲解了Spark Streaming的架构,接收器如何处理数据并将其保存为RDD,以及如何通过DStream进行转换和输出操作。此外,还展示了如何实现实时分析端口、Kafka和Flume数据源的例子,以及Spark Streaming的运行流程。
目录:
一、Spark Streaming概述
Spark Streaming是构建在Spark上的流式处理框架。
Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用Spark Core进行快速处理。Spark Streaming支持多种数据输入源,如Kafka,Flume和TCP套接字等。
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流作为抽象表示,叫做DStream。DStream是随着时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD存在,而DStream就是由这些RDD组成的序列(因此,得名"离散化")

DStream可以从各种输入源中创建,比如Flume、kafka或者HDFS。创建出来的DStream支持两种操作,一种是转换操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream提供了许多与RDD所支持的操作相类似的操作支持,还增加了与时间相关的新操作,例如滑动窗口。
二、Spark Streaming特点
(1) 易用
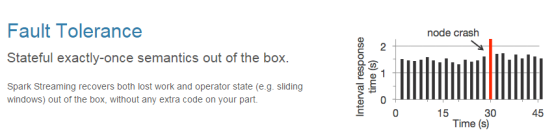
(2) 容错
(3) 易整合到Spark体系

三、Spark Streaming架构
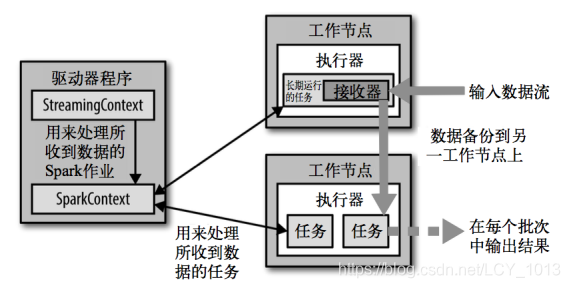
Spark Streaming在Spark的驱动器程序—工作节点的结构的执行过程如上图所示。Spark Streaming为每个输入源启动对应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为 RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默 认行为)。数据保存在执行器进程的内存中,和缓存 RDD 的方式一样。驱动器程序中的 StreamingContext 会周期性地运行Spark 作业 来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。
四、Spark Streaming代码实时分析数据
1.实时分析端口或目录中的数据
pom.xml 加入以下依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.0</version>
</dependency>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









