



算力作为数字经济的核心基础设施,其技术突破与产业升级已成为推动数字经济高质量发展的关键动力。本文基于公开行业报告、技术白皮书及企业实践案例,系统拆解 AI 服务器、高速光模块、液冷技术、算力芯片四大核心赛道的技术迭代逻辑、国产化突破路径与未来发展趋势,为技术从业者、行业研究者提供兼具专业性与参考价值的深度分析。
一、AI 服务器:从硬件整合到软硬协同的技术跃迁
1. 技术演进逻辑
AI 服务器的核心竞争力已从早期 “GPU + 主板 + 电源” 的硬件堆砌,转向 “硬件配置优化 + 软件栈适配 + 场景化定制” 的软硬协同体系。关键技术升级体现在三方面:
- 硬件架构:多 GPU 集群设计成为主流,PCIe 5.0 接口、NVLink 高速互联技术普及,提升多芯片协同效率;
- 软件适配:配套 AI 框架(如 MindSpore、TensorFlow)与开发平台的深度优化,降低模型训练与推理的适配成本;
- 定制化能力:针对工业质检、金融风控等场景,优化接口协议、数据处理延迟等核心指标,满足垂直行业需求。
2. 国产化进展
国产 AI 服务器已实现从 “跟跑” 到 “并跑” 的突破:
- 整机制造:浪潮信息、中科曙光等企业全球市场份额分别达 18%、12%,跻身全球 TOP5,在政务、国企等领域实现规模化应用;
- 核心部件替代:海光信息 Hygon D 系列 CPU 兼容 x86 架构,政务领域渗透率达 20%;寒武纪思元 590 GPU 算力达 128 TOPS,智能安防场景推理效率达行业主流水平的 85%;
- 生态构建:华为 Atlas 系列服务器搭建 “昇腾 GPU+MindSpore 框架 + ModelArts 平台” 完整生态,在智能驾驶、智慧城市等场景形成解决方案闭环。
二、高速光模块:速率迭代与技术创新的双重驱动
1. 技术迭代路径
高速光模块的速率演进遵循 “每两年翻倍” 的规律,核心技术突破聚焦三大方向:
- 速率升级:400G 光模块逐步退出主流,800G 凭借 “4×200G” 并行传输方案实现规模化部署,1.6T 光模块通过硅光芯片、紧凑封装技术完成技术验证,2026 年有望成为超算中心主流;
- 性能优化:通过优化光芯片耦合效率、降低信号损耗,在速率提升的同时控制功耗增长,800G 光模块功耗较 400G 仅增加 30%;
- 下一代技术:CPO(共封装光学)技术将光模块与芯片封装集成,缩短信号传输路径,可降低 30% 功耗、20% 延迟,目前微软、谷歌已启动测试,国内企业处于原型机验证阶段。
2. 国产化竞争格局
国产光模块企业在全球市场占据核心地位:
- 市场份额:中际旭创、新易盛全球市场份额合计达 35%,800G 光模块出货量占全球 30% 以上,主要供应海外云厂商;
- 技术布局:在 1.6T 光模块领域,国产企业已实现核心技术突破,部分产品进入小批量试产;CPO 技术方面,中际旭创原型机通过客户测试,天孚通信光器件实现量产;
- 成本优势:依托国内完整的产业链配套,国产光模块在中高端市场的成本较海外产品低 15%-20%,性价比优势显著。
三、液冷技术:高密度算力场景的散热解决方案升级
1. 技术路线对比与演进
液冷技术已成为解决 AI 服务器高算力密度散热问题的核心方案,两大技术路线并行发展:
- 冷板式液冷:通过金属冷板贴合 CPU、GPU 等发热部件,液体循环带走热量,改造难度低、成本可控,当前占液冷市场 90% 以上份额,PUE 可降至 1.2 以下,广泛应用于互联网、政务数据中心;
- 浸没式液冷:将服务器整机浸泡在绝缘冷却液中,散热效率是风冷的 5-10 倍,PUE 可低至 1.1 以下,但成本较高、改造复杂,主要用于超算中心、高端 AI 训练集群,曙光数创方案已支撑 “天河” 超算稳定运行。
2. 国产化产业生态
国内液冷产业已形成 “设备制造 + 核心部件 + 运维服务” 的完整链条:
- 设备端:英维克、曙光数创合计占据 45% 市场份额,冷板式液冷系统已通过腾讯、阿里等企业验证;
- 核心部件:巨化股份氟化液、润禾材料矿物油通过华为、浪潮认证,中航光电液冷连接器国产数据中心渗透率达 60%;
- 政策与需求驱动:“东数西算” 工程要求新建数据中心 PUE 低于 1.3,倒逼液冷技术渗透,2024 年 AI 服务器液冷渗透率已达 25%,预计 2027 年提升至 60%。
四、算力芯片:国产化突破与差异化竞争路径
1. 技术突破方向
国产算力芯片围绕 “制程受限下的性能提升” 核心命题,形成两条关键路径:
- 中低端替代:针对边缘计算、简单推理等场景,研发适配主流 AI 框架的 GPU 产品,寒武纪思元 590、海光 DCU 等产品在推理效率、兼容性上已接近行业主流水平,价格仅为同类海外产品的 70%;
- 差异化创新:面向垂直场景研发 ASIC 芯片,通过定制化电路设计提升算力效率,芯原股份、翱捷科技等企业产品在智能安防、金融支付场景的算力效率较通用 GPU 提升 30%-50%;
- 先进封装:Chiplet(芯粒)技术成为突破制程限制的关键,长电科技方案将两颗 14nm 芯片集成,性能达 7nm 单芯片的 90%,成本降低 30%,2024 年国内渗透率达 12%。
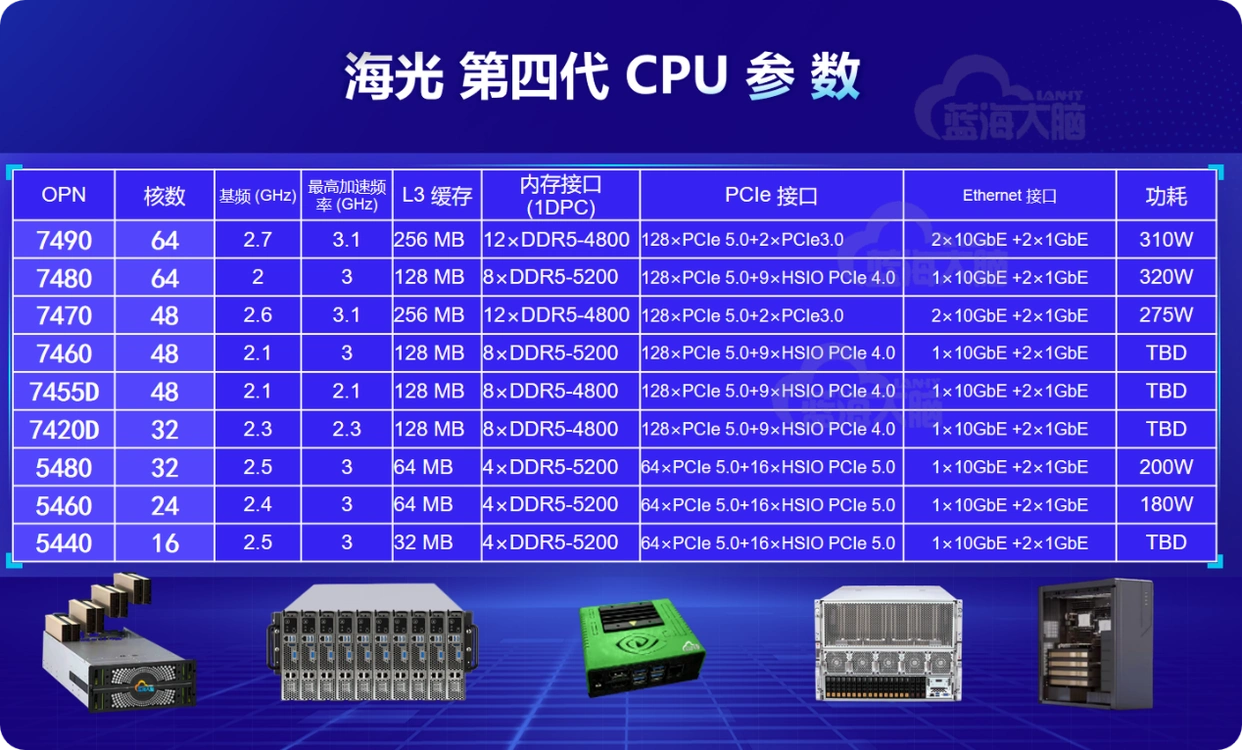
2. 场景渗透与生态构建
国产算力芯片已在多场景实现规模化应用:
- 政务领域:渗透率达 25%,支撑智慧政务、社保核验等场景的数据处理需求;
- 工业领域:用于零部件缺陷检测、数字孪生等场景,某汽车厂商应用海光 DCU 后,检测效率提升 3 倍;
- 生态适配:通过兼容 CUDA 框架、适配主流 AI 模型,降低开发者迁移成本,海光 DCU 在金融风控场景的适配效率达 90%。
五、算力产业发展的核心趋势与启示
- 技术迭代聚焦效率与适配:各赛道均向 “高性能 + 低功耗 + 场景化” 方向演进,软硬协同、跨技术融合成为关键;
- 国产化进入 “深水区”:从整机替代向核心部件、底层技术突破延伸,生态构建成为长期竞争的核心;
- 行业算力成增长核心:工业、医疗、交通等垂直领域的定制化算力需求爆发,“算力 + 算法 + 服务” 一体化方案更具竞争力;
- 产业链协同至关重要:华为、阿里等企业通过构建产业联盟,整合上下游资源,加速技术落地与场景渗透。
算力产业的发展不仅是技术层面的突破,更是数字经济核心竞争力的体现。未来五年,随着国产化技术持续迭代、应用场景不断拓展,中国算力产业有望实现从 “规模领先” 到 “技术引领” 的跨越,为数字经济高质量发展提供坚实支撑。
#算力 #AI 服务器 #高速光模块 #液冷技术 #算力芯片 #国产化 #Chiplet #CPO 技术 #数据中心

















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









