




随着 DeepSeek 的开源,大模型发展迎来重要变革,医疗行业在这一技术浪潮中处于前沿。
据蓝海大脑研究数据显示,仅在 2025 年 3 月,涉及 DeepSeek 的相关项目规模就颇为可观。
众多医疗机构积极引入 DeepSeek 相关技术,以下是 2025 年 3 月 29 日部分医院的部署情况:
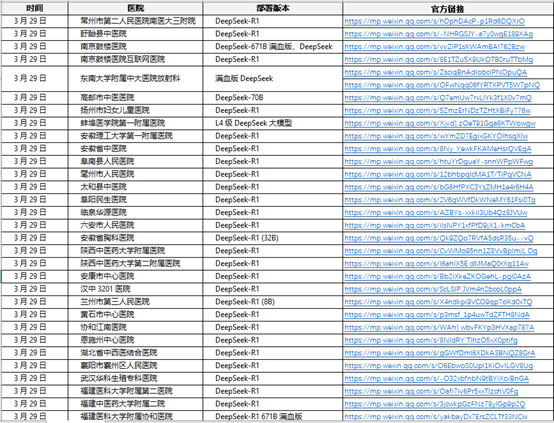
2025 年 3 月 29 日部分医院 DeepSeek 技术部署情况
近日某大学三甲医院部署 H20 相关设备,具体配置及性能数据如下:
-
单台 NVIDIA H20 配置 141GB 显存的一体机,用户并发数量为 128,token 量为 1052.92token/s。
-
双机配置下,2 台配置 96GB 显存的一体机,用户并发数量为 1024,token 量为 3113.38token/s。

据公开资料,在使用 DeepSeek R1 进行带思维链深度思考的短输入长输出问答场景时:
-
单个用户并发时,解码性能为 33.3tokens/s。
-
16 个用户并发时,每个用户的解码性能约为 20tokens/s。
-
64 个用户并发时,每个用户的解码性能约为 10.4tokens/s。
-
1024 个用户并发时,单台 H20 141G 八卡机实现了 3975.76tokens/s 的吞吐性能。
大型语言模型(LLM)在医疗保健领域具有显著的应用潜力,其应用范围涵盖从诊断决策到患者分诊等多个方面。常通过标准化医学考试,如美国医师执照考试(USMLE)对语言模型在医疗领域的能力进行评估。然而近期研究指出,单纯依据考试成绩评估临床实践能力存在局限性,类似于仅通过交通规则笔试来评估驾驶能力。
尽管 LLM 能够针对医疗保健问题生成复杂的回答,但其在实际临床应用中的表现仍有待深入检验。JAMA 的一项审查显示,仅有 5% 的评估使用真实患者数据,且多数研究聚焦于标准化体检表现的评估。这一现状凸显了构建更完善评估体系的紧迫性,该体系应尽可能基于真实临床数据,以准确衡量模型在实际医疗任务中的表现。
在医疗行业加速迈进智能化的进程中,大型语言模型(LLM)的应用愈发广泛,从辅助诊断决策到优化患者分诊流程,其潜力不断被挖掘。然而,如何精准衡量这些模型在真实医疗场景中的表现,成为了亟待解决的关键问题。过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









