




 本文深入介绍了XPath语言,一种在XML文档中查找信息的强大工具,以及如何使用lxml库结合XPath进行网页爬取。文章详细解释了XPath的基本语法、谓语使用、通配符选取等,并提供了使用lxml库解析HTML和XML文件的具体示例。
本文深入介绍了XPath语言,一种在XML文档中查找信息的强大工具,以及如何使用lxml库结合XPath进行网页爬取。文章详细解释了XPath的基本语法、谓语使用、通配符选取等,并提供了使用lxml库解析HTML和XML文件的具体示例。
XPath简介
XPath(XML Path Language) 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。因此,对 XPath 的理解是很多高级 XML 应用的基础。
XPath开发工具
- Chrome插件XPath Helper
- Firefox插件Try XPath
XPath基本语法
- 选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
| 表达式 | 作用 | 示例 | 结果 |
|---|---|---|---|
| nodename | 选取此节点的所有子节点。 | bookstore | 选取 bookstore 元素的所有子节点。 |
| / | 从根节点选取。 | /bookstore | 选取根元素 bookstore。假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 | //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| . | 选取当前节点。 | ./book | 选取当前节点下的book子元素 |
| @ | 选取属性。 | //@lang | 选取名为 lang 的所有属性。 |
- 谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()< 3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
- 选取未知节点
XPath 通配符可用来选取未知的 XML 元素
| 通配符 | 描述 | 示例 | 结果 |
|---|---|---|---|
| * | 匹配任何元素节点。 | /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| @* | 匹配任何属性节点。 | //* | 选取文档中的所有元素。 |
| node() | 匹配任何类型的节点。 | //title[@*] | 选取所有带有属性的 title 元素。 |
- 选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
lxml库
lxml是功能最丰富且易于使用的库,用于处理Python语言中的XML和HTML。它的独特之处在于它将这些库的速度和XML特性完整性与原生Python API的简单性相结合,大多数兼容但优于众所周知的 ElementTree API。最新版本适用于2.7到3.7的所有CPython版本
遇到的问题
from lxml import etree
显示有错误
Cannot find reference 'etree' in '__init__.py' more... (Ctrl+F1)

这个其实不是错误,不影响正常使用。无视就可以了。。
基本使用
解析html字符串
from lxml import etree
import requests
url = 'https://jobs.51job.com/all/co4229797.html#syzw'
r = requests.get(url)
# etree.HTML()解析HTML格式的文本
html = etree.HTML(r.text)
#由于html是字节流,需要转换成字符串
print(etree.tostring(html, encoding='utf-8').decode('utf-8'))
解析html文件
from lxml import etree
import requests
#如果是XML格式可以创建XML解析器
#创建XML解析器示例:
#parser = etree.XMLParser(encoding='utf-8')
#创建HTML解析器
parser = etree.HTMLParser(encoding='utf-8')
# 用创建的解析器解析文本
html = etree.parse(‘文件名’,parser=parser)
#由于html是字节流,需要转换成字符串
print(etree.tostring(html, encoding='utf-8').decode('utf-8'))
XPath和lxml库结合爬取51job某公司招聘的职位列表
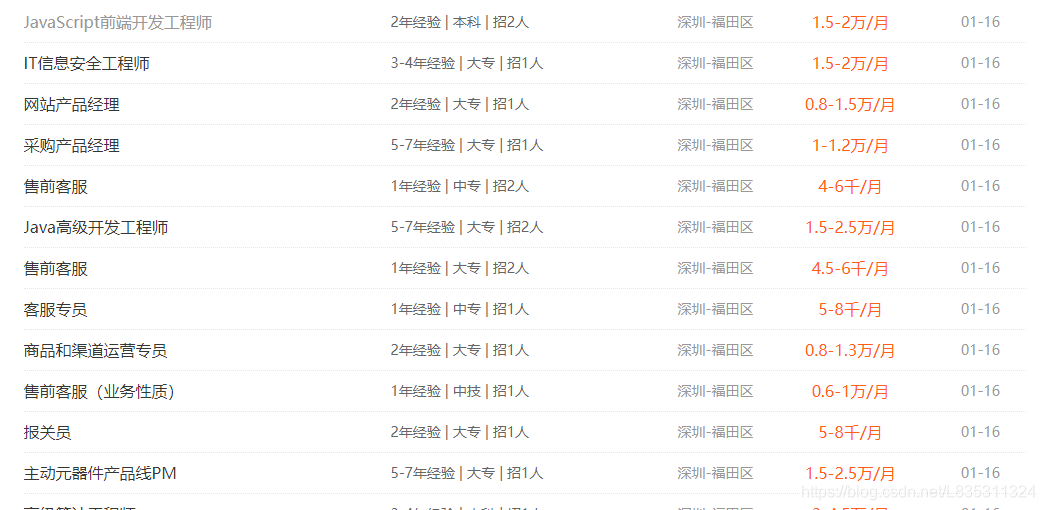
网页
from lxml import etree
import requests
url = 'https://jobs.51job.com/all/co4229797.html#syzw'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
r = requests.get(url,headers=headers)
html = etree.HTML(r.text)
divs = html.xpath('//div[@class="el"]')
positions = []
for div in divs:
href = div.xpath('./p/a/@href')[0]
title = div.xpath('./p/a/@title')[0]
requirement = div.xpath('.//span/text()')[0]
address = div.xpath('.//span/text()')[1]
salary = div.xpath('.//span/text()')[2]
date = div.xpath('.//span/text()')[3]
position = {
'链接':href,
'职位':title,
'要求':requirement,
'地址':address,
'薪资':salary,
'日期':date
}
positions.append(position)
for i in positions:
for key,value in i.items() :
print("{!s}:{!s}".format(key,value))
效果

# divs = html.xpath('//div[@class="el"]')
# XPath获取到的结果,返回的是个列表,这是只是第一个元素,并不是全部
<div class="el">
<p class="t1"><a target="_blank" href="https://jobs.51job.com/shenzhen-ftq/106687916.html?s=04" class=" zw-name" title="JavaScript前端开发工程师">JavaScript前端开发工程师</a></p>
<span class="t2">2年经验 | 本科 | 招2人</span>
<span class="t3">深圳-福田区</span>
<span class="t4">1.5-2万/月</span>
<span class="t5">01-16</span>
</div>
参考链接

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









