






项目源码:https://github.com/jiawen-zhu/ViPT
Abstract
本文提出视觉提示多模态跟踪 ViPT,通过学习与模态相关的提示,使得冻结的与训练模型适应各种下游任务。
仅基于RGB序列的目标跟踪在一些复杂场景(如极端光照、背景杂乱和运动模糊)中仍容易失败。因此,多模态跟踪因其能够通过利用不同模态之间的互补性来实现更稳健的跟踪而受到越来越多的关注。然而,作为RGB基础跟踪的下游任务,多模态跟踪面临的主要问题是缺乏大规模数据集。由此产生了用预训练的RGB跟踪器在目标任务上微调的方法。
这些方法仍存在问题:(i)全量微调模型耗时且效率低下,参数存储负担大,对众多应用不友好,部署繁琐。(ii)由于标注样本有限,全量微调无法获得泛化表示,无法利用在大规模数据集上预训练的基础模型的知识。
直观上,多模态和单RGB模态跟踪之间存在很大的继承性,应在特征提取或注意力模式上共享大部分先验知识。基于此提出了该模型ViPT,冻结整个基础模型,仅学习少量特定于模态的视觉提示,最大限度地继承了在大规模训练的RGB基础模型参数。
创新点:
- 面向下游任务的多模态跟踪,适用于RGB-D、RGB-T和RGB-E跟踪
- 设计了一种模态互补提示器(MCP),为面向任务的多模态跟踪生成有效的视觉提示。辅助模态输入被简化为少量提示,而不是设计额外的网络分支。
- 达到sota
Method
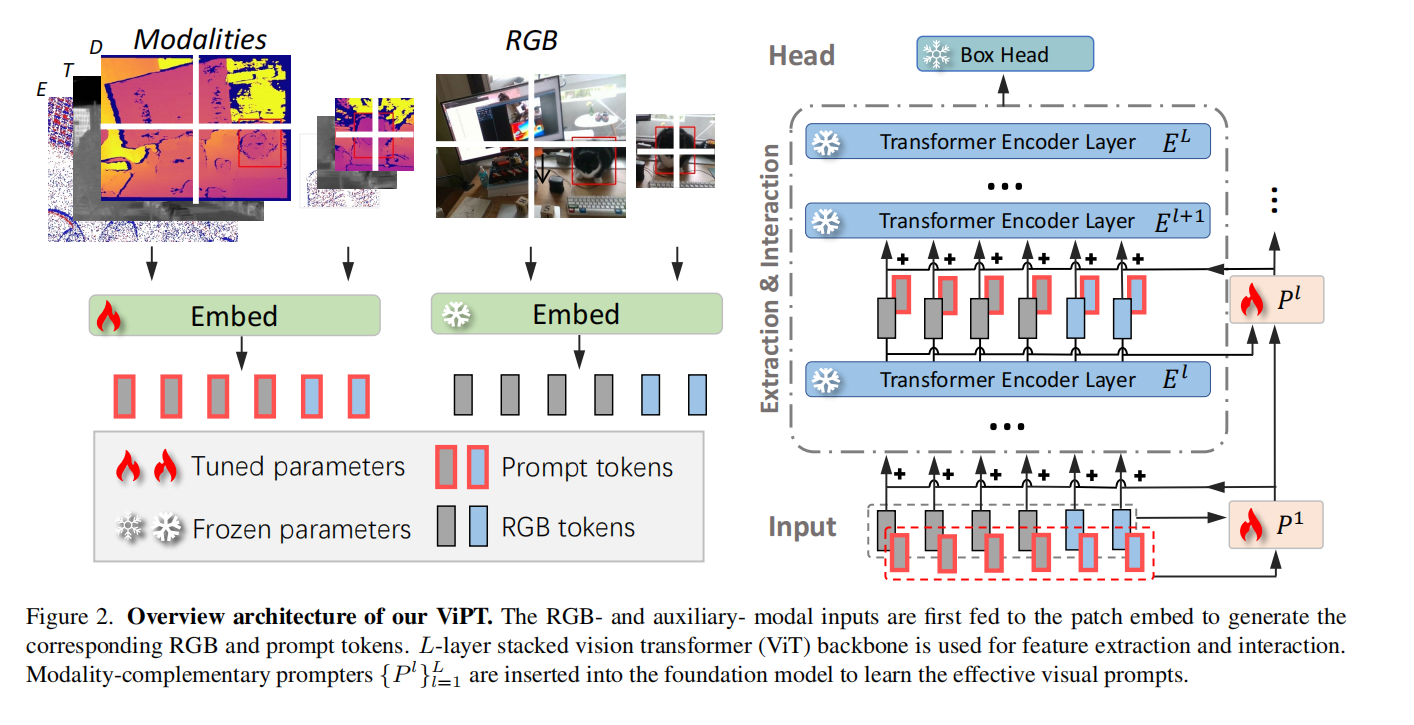
问题设定
对于基础RGB跟踪:问题可以描述为:学习一个跟踪器F-RGB
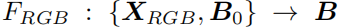
其中X-RGB表示的是RBG视频帧,B-0表示初始帧的搜索框
B表示跟踪器输出的后续帧的目标框
对于多模态视觉跟踪问题,问题可以描述为学习一个跟踪器 F-MM
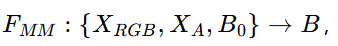
X-A是增加的每一帧的模态信息
基础模型
跟踪器可以分解为一个特征提取函数f和一个box head 将特征映射为目标框。
在跟踪开始的第一帧,数据提供的一个初始目标框 input exemplar 和搜索帧 被embed成patch,然后flatten为一维token。

这里解释一下:其实做的事情相当于ViT中的embed 部分,将input exemplar分为多个patch,每个patch都映射为一个embedding,同样的,整张图象X-RGB进行同样的处理。D表示的就是在映射后embedding的维度,这是由卷积时卷积核的数量决定的。Nz和Nx 不同是由于 Z-RGB 和 X-RGB 图像的大小不一样,自然,分成的patch数量也不一样,最终得到的embedding数量也不一样。
然后将这些embedding concat之后输入transformer层里进行encode,完成特征提取和特征融合。
多模态提示跟踪
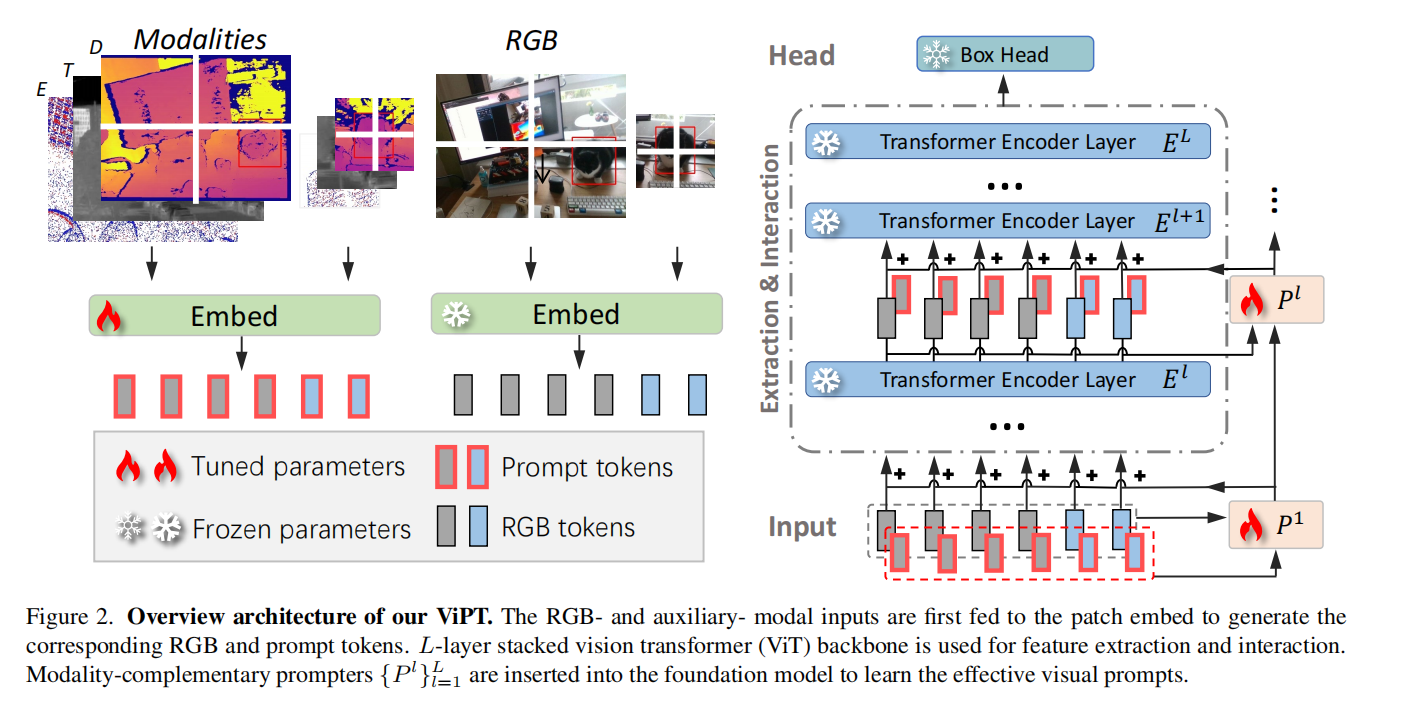
多模态跟踪在RGB图像流之外还提供了一个额外的模态流(如红外,深度,事件等),该模态流在时间上与RGB同步且在空间上与其对齐。
在本文的工作ViPT中,每个流被映射为embedding,RGB的embedding记为H-RGB,辅助模态的embedding记为H-A。H-RGB 和 H-A 被输入 模态互补提示器(MCP),用以生成模态流的提示,学习到的提示以残差的形式添加到 H - RGB中,输入到基础模型里。
在基础模型的每层里,进行同样的操作,将该层输出的token与辅助模态的embedding再输入到 模态互补提示器MCP中,输出的提示仍以残差的形式添加到原输出token中,然后输入下一层。
值得注意的是:在该工作中,所有与原RGB模态相关的网络参数都被冻结,包括对RGB图像的patch embedding,feature extraction等。只是在原基础模型上添加了提示信息。
模态互补提示模块MCP
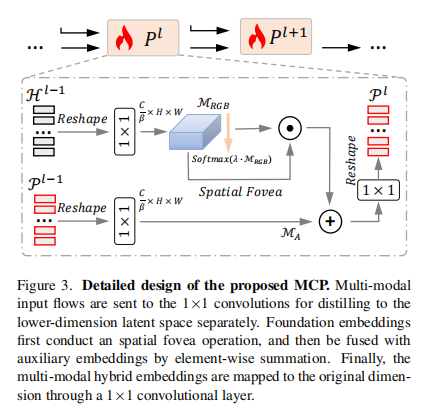
该模块旨在通过在预训练的模型中引入一些可训练的参数来学习辅助模态中的有效的视觉提示。
MCP模块有两个主要的分支,即基础流H 和辅助流P,MCP模块的主要步骤包括:
- 投影到低维的潜在embedding
- 生成多模态内部互补表示
- 投影回到原维度并生成视觉提示
考虑到单模态流具有一定的冗杂特征,并且提示块应尽量包含更少的参数,通过一种方式将每个流投影到低维:
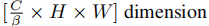
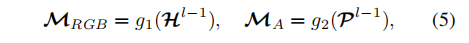
实际上是减少了通道数(利用1* 1卷积),β是通道减少因子。公式中的g指的就是1 * 1 卷积。
然后对RGB的嵌入(上面公式中经过卷积的M-RGB)做spatial fovea 操作,首先在所有空间维度上应用 λ-smoothed 空间softmax,然后通过 channel-wise 空间注意力类似的掩码 M-fovea 生成增强嵌入。
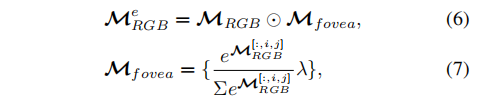
其中λ 是每个块的可学习加权参数。
最后将增强的嵌入与模态嵌入相加,然后调整通道得到MCP输出的embedding
优化
由于仅更新视觉提示学习部分的参数,因此仅包含0.84M个可训练参数,且在各模态的分支情况下击败了全微调模型。
总的损失函数为:
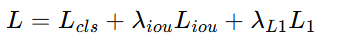
实验部分
在RGB-D,RGB-T, RGB-E跟踪中都进行了实验。
实验设置
- 2 * A100
- 60epoch
- AdamW
- Xavier均匀初始化
MCP模块的数量分析
研究了在基础模型中插入MCP模块的数量对性能的影响,可以看到,随着插入MCP模块的增加,性能有了明显的提升。(这里的插入方式是每隔一定层数插入一个MCP模块)
关于调优跟踪的讨论
- 与全微调相比,提示调优在下游任务中展示出更好的适应性,在下游数据集上的全微调会破坏原预训练参数的质量
- 提示调优使得RGB和辅助模态之间的跟踪关系更加紧密
- 参数量的显著降低。
。(这里的插入方式是每隔一定层数插入一个MCP模块)
关于调优跟踪的讨论
- 与全微调相比,提示调优在下游任务中展示出更好的适应性,在下游数据集上的全微调会破坏原预训练参数的质量
- 提示调优使得RGB和辅助模态之间的跟踪关系更加紧密
- 参数量的显著降低。

















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









