







设计背景
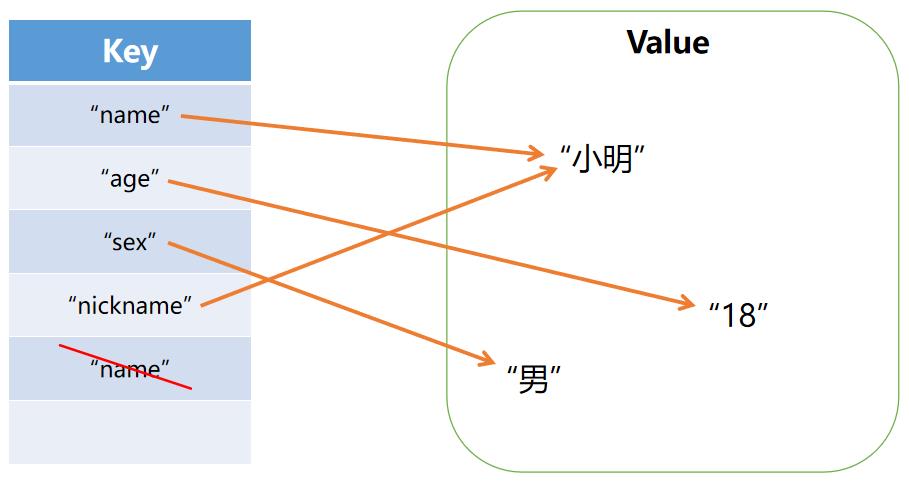
在信息存储的场景中,我们经常遇到“一个值对应着另一个值”的情况,这种关系在数学中被称作函数(function)或者映射(mapping)。在数据结构中也有这样一种设计类型,每一个节点存储着一个key键和一个value值,两者合称“键值队”(key-value),用户可以通过key键定位到value值,这种结构类型被称为映射(Map)。
映射中key的值不能重复,而value得值可以重复,多个key可以映射到同一个value上。
结构分析
【底层实现】链表(LinkedList)/ 二分搜索树(BST)
【核心方法】
public void add(K key, V value); //向映射中添加键值队
public V remove(K key); //移除指定键值队
public void set(K key, V newValue); //修改指定键所对应的值
public V get(K key); //获取指定键所对应的值
【差异分析】
因为使用链表实现的映射(LinkedListMap)进行增加、删除等操作时,都需要对链表元素进行遍历,故其性能较低(时间复杂度为O(n)级别);而使用二分搜索树实现的映射(BSTMap)在理想状态下(满二叉树)最多只会遍历h个元素(时间复杂度为O(h)级别,从数值上看为O(logn)级别),所以通常BSTMap的性能与LinkedListMap的性能差异巨大。
代码实现
1. 利用LinkedList实现
public class LinkedListMap<K, V> implements Map<K, V> {
/**
* 内部类:节点
*/
private class Node {
/**
* 实例域:key值、value值、节点引用
*/
public K key;
public V value;
public Node next;
/**
* 构造器:对实例域进行初始化
*
* @param key 键
* @param value 值
* @param next 引用
*/
public Node(K key, V value, Node next) {
this.key = key;
this.value = value;
this.next = next;
}
public Node(K key) {
this(key, null, null);
}
public Node() {
this(null, null, null);
}
}
private Node dummyHead;
private int size;
public LinkedListMap() {
dummyHead = new Node();
size = 0;
}
/**
* 方法:通过key值查找其所在的节点
*
* @param key 键
* @return 键所在的节点
*/
private Node getNode(K key) {
Node cur = dummyHead.next;
while (cur != null) {
if (cur.key.equals(key)) {
return cur;
}
cur = cur.next;
}
return null;
}
@Override
public void add(K key, V value) {
Node node = getNode(key);
if (node = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









