







 本文详细介绍了如何在Ubuntu系统中利用Hadoop进行MapReduce操作,以实现对《老古董店》英文版txt文件的词频统计。步骤包括安装Ubuntu、配置Java环境、数据上传到HDFS、编写并编译WordCount Java程序、运行程序以及下载和展示处理结果。通过这个过程,展示了MapReduce在大数据处理中的应用。
本文详细介绍了如何在Ubuntu系统中利用Hadoop进行MapReduce操作,以实现对《老古董店》英文版txt文件的词频统计。步骤包括安装Ubuntu、配置Java环境、数据上传到HDFS、编写并编译WordCount Java程序、运行程序以及下载和展示处理结果。通过这个过程,展示了MapReduce在大数据处理中的应用。
一、 需求描述
Hadoop综合大作业 要求:
1.将待分析的文件(不少于10000英文单词)上传到HDFS。
2.调用MapReduce对文件中各个单词出现的次数进行统计。
3.将统计结果下载本地。
4.写一篇博客描述你的分析过程和分析结果。
本次大作业,我们需要实现的是调用MapReduce对文件中各个单词出现的次数进行统计。要求在Linux系统中实现上述操作。首先要安装Ubuntu系统,然后要配置Java环境,安装JDK。Ubuntu提供了一个健壮,功能丰富的计算环境。
二、环境介绍
jdk-8u301-linux-x64

hadoop-3.2.2
eclipse-4.7.0-linux.gtk.x86_64
三、数据来源及数据上传
The Old Curiosity Shop(老古董店英语版)txt下载-电子书下载-拉米阅读 (lmeee.com)
四、数据上传结果查看
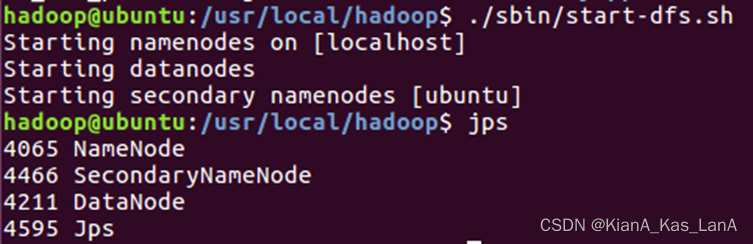
1、首先启动hdfs
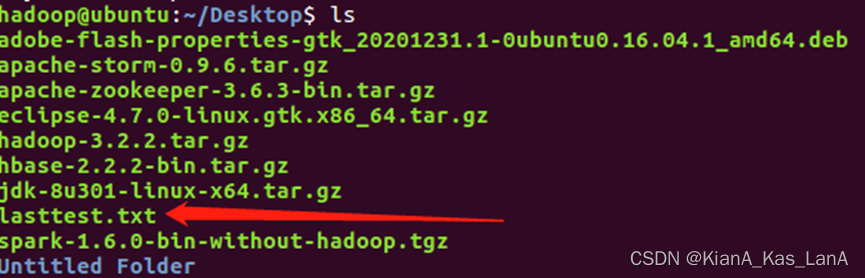
2、将桌面的lasttest.txt上传到hdfs


五、数据处理过程的描述
-
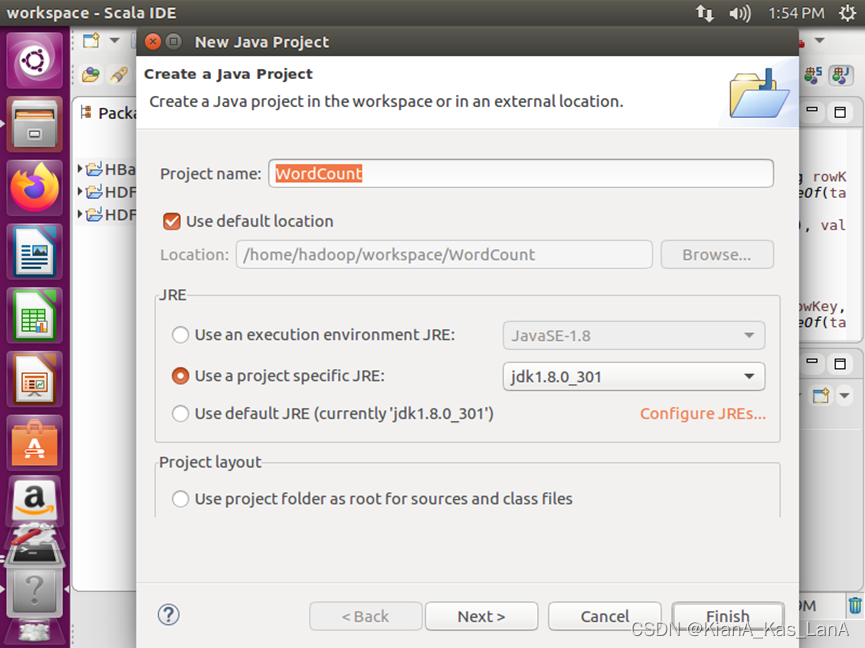
在Eclipse中创建项目
在“Project name”后面输入工程名称“WordCount”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/WordCount”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如jdk1.8.0_162。然后,点击界面底部的“Next>”按钮,进入下一步的设置。
 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









