




一、引言
在分布式环境下,如果舍弃SpringCloud,使用其他的分布式框架,那么注册心中,配置集中管理,集群管理,分布式锁,队列的管理想单独实现怎么办。
二、Zookeeper介绍
Zookeeper本身是Hadoop生态圈的中的一个组件,Zookeeper强大的功能,在Java分布式架构中,也会频繁的使用到Zookeeper。

三、Zookeeper安装
[root@mastera zsq1]# cd zsq1
[root@mastera zsq1]# mkdir docker-compose-zk1
[root@mastera zsq1]# cd docker-compose-zk1/
[root@mastera docker-compose-zk1]# vim docker-compose.yaml
docker-compose.yml 文件如下
version: "3.1"
services:
zk:
image: daocloud.io/daocloud/zookeeper:latest
restart: always
container_name: zk
ports:
- 2181:2181
启动
docker-compose up
进入容器中的docker
root@7c986e60ff1f:/opt/zookeeper# ./bin/zkCli.sh
四、Zookeeper架构【重点】
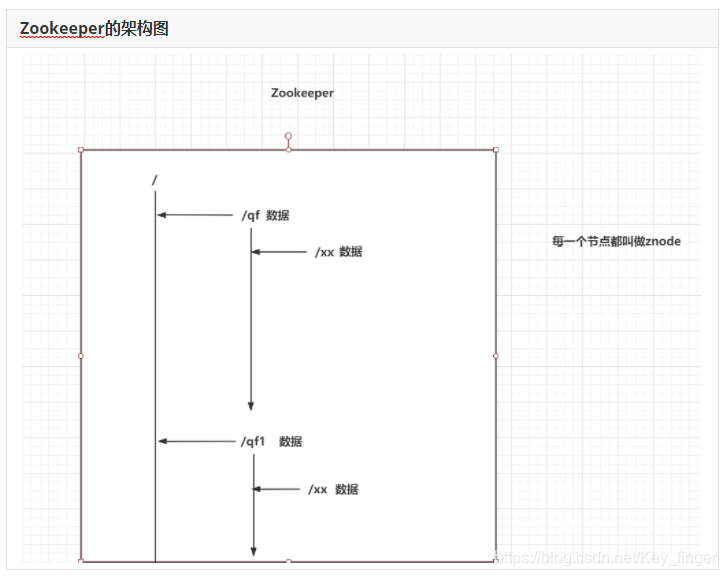
4.1 Zookeeper的架构图
每一个节点都称为znode
每一个znode中都可以存储数据
节点名称是不允许重复的
4.2 znode类型
四种Znode
-
持久节点:永久的保存在你的Zookeeper
-
持久有序节点:永久的保存在你的Zookeeper,他会给节点添加一个有序的序号。 /xx -> /xx0000001
-
临时节点:当存储的客户端和Zookeeper服务断开连接时,这个临时节点自动删除
-
临时有序节点:当存储的客户端和Zookeeper服务断开连接时,这个临时节点自动删除,他会给节点添加一个有序的序号。 /xx -> /xx0000001
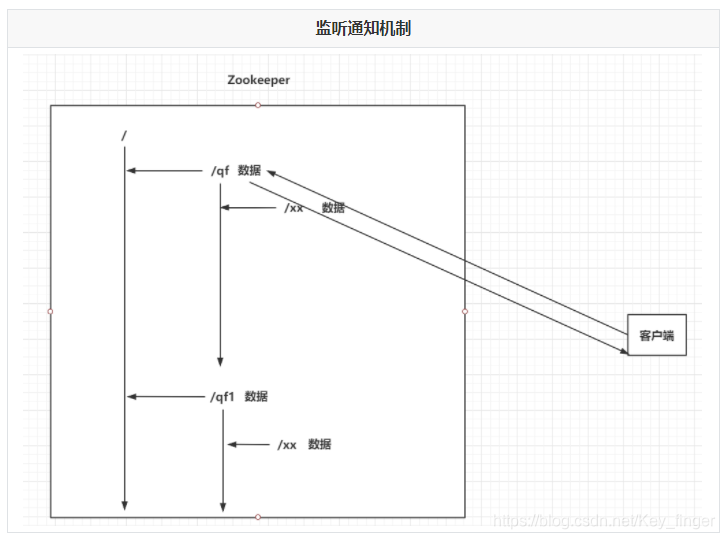
4.3 Zookeeper的监听通知机制
客户端可以去监听Zookeeper中的Znode节点。
Znode改变时,会通知监听当前Znode的客户端
五、Zookeeper常用命令
# 查询当前节点下的全部子节点
ls 节点名称
# 例子 ls /
# 查询当前节点下的数据
get 节点名称
# 例子 get /zookeeper
# 创建节点 临时节点 当client 断开时则删除
create [-s] [-e] znode名称 znode数据
# -s:sequence,有序节点
# -e:ephemeral,临时节点
create -s -e /node1 b
# 修改节点值
set znode名称 新数据
set /node10000000001 c
# 删除节点
delete znode名称 # 没有子节点的znode
delete /node2/node1
rmr znode名称 # 删除当前节点和全部的子节点
rmr /node2
六、Zookeeper集群【重点】
6.1 Zookeeper集群架构图
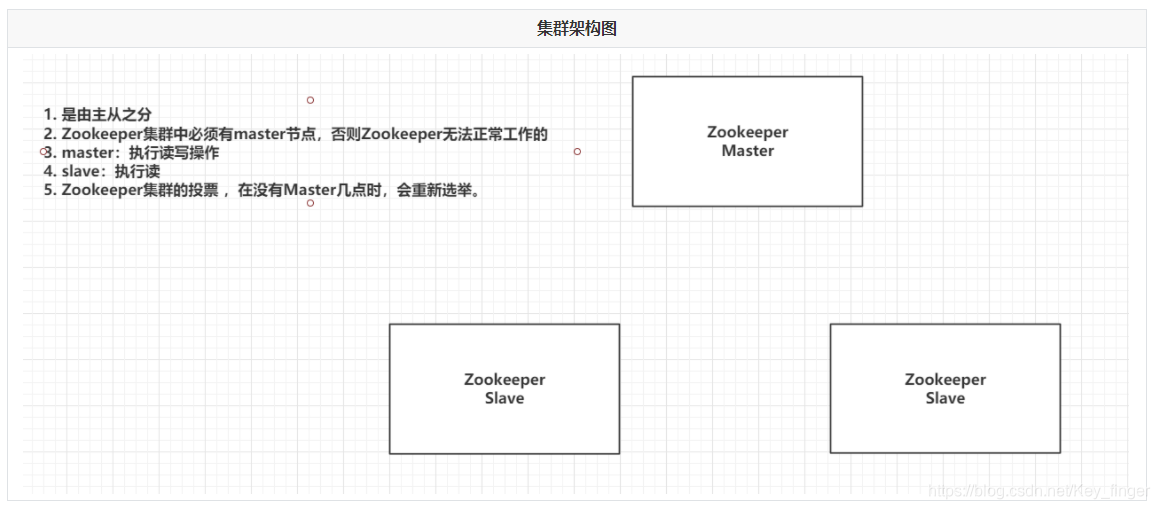
6.2 Zookeeper集群中节点的角色
- Leader:Master主节点
- Follower (默认的从节点):从节点,参与选举全新的Leader
- Observer:从节点,不参与投票
- Looking:正在找Leader节点
6.3 Zookeeper选举机制
(1)Zookeeper集群中只有超过半数以上的服务器启动,集群才能正常工作;
(2)在集群正常工作之前,myid小的服务器给myid大的服务器投票,直到集群正常工作,选出Leader;
(3)选出Leader之后,之前的服务器状态由Looking改变为Following,以后的服务器都是Follower。
6.4 搭建Zookeeper集群
yaml文件
version: "3.1"
services:
zk1:
image: zookeeper
restart: always
container_name: zk1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk2:
image: zookeeper
restart: always
container_name: zk2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk3:
image: zookeeper
restart: always
container_name: zk3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
端口说明
1、2181:对cline端提供服务
2、3888:选举leader使用
3、2888:集群内机器通讯使用(Leader监听此端口)
七、Java操作Zookeeper
7.1 Java连接Zookeeper
1、创建maven环境
2、引入依赖
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
3、编写连接Zookeeper集群的工具类
public class ZkUtil {
public static CuratorFramework cf(){
RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,2);
CuratorFramework cf = CuratorFrameworkFactory.builder()
.connectString("192.168.199.109:2181,192.168.199.109:2182,192.168.199.109:2183")
.retryPolicy(retryPolicy)
.build();
cf.start();
return cf;
}
}
4、测试
7.2 Java操作Znode节点
查询
public class Demo2 {
CuratorFramework cf = ZkUtil.cf();
// 获取子节点
@Test
public void getChildren() throws Exception {
List<String> strings = cf.getChildren().forPath("/");
for (String string : strings) {
System.out.println(string);
}
}
// 获取节点数据
@Test
public void getData() throws Exception {
byte[] bytes = cf.getData().forPath("/qf");
System.out.println(new String(bytes,"UTF-8"));
}
}
添加
@Test
public void create() throws Exception { cf.create().withMode(CreateMode.PERSISTENT).forPath("/qf2","uuuu".getBytes());
}
修改
@Test
public void update() throws Exception {
cf.setData().forPath("/qf2","oooo".getBytes());
}
删除
@Test
public void delete() throws Exception {
cf.delete().deletingChildrenIfNeeded().forPath("/qf2");
}
查看znode的状态
@Test
public void stat() throws Exception {
Stat stat = cf.checkExists().forPath("/qf");
System.out.println(stat);
}
7.3 监听通知机制
实现方式
public class Demo3 {
CuratorFramework cf = ZkUtil.cf();
@Test
public void listen() throws Exception {
//1. 创建NodeCache对象,指定要监听的znode
NodeCache nodeCache = new NodeCache(cf,"/qf");
nodeCache.start();
//2. 添加一个监听器
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
byte[] data = nodeCache.getCurrentData().getData();
Stat stat = nodeCache.getCurrentData().getStat();
String path = nodeCache.getCurrentData().getPath();
System.out.println("监听的节点是:" + path);
System.out.println("节点现在的数据是:" + new String(data,"UTF-8"));
System.out.println("节点状态是:" + stat);
}
});
System.out.println("开始监听!!");
//3. System.in.read();
System.in.read();
}
}

















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









