




 在Kafka中,为了保证消息的消费顺序,通常有两种方法:一是创建单个Partition,确保所有消息按顺序存储和消费;二是通过生产者指定Partition,将相同行为的消息发送到同一Partition,以达到顺序消费的目的。但需注意,Kafka仅保证分区内的消息顺序,不保证跨分区的整体顺序。
在Kafka中,为了保证消息的消费顺序,通常有两种方法:一是创建单个Partition,确保所有消息按顺序存储和消费;二是通过生产者指定Partition,将相同行为的消息发送到同一Partition,以达到顺序消费的目的。但需注意,Kafka仅保证分区内的消息顺序,不保证跨分区的整体顺序。
一、前言
在Kafka中Partition(分区)是真正保存消息的地方,发送的消息都存放在这里。Partition(分区)又存在于Topic(主题)中,并且一个Topic(主题)可以指定多个Partition(分区)。
在Kafka中,只保证Partition(分区)内有序,不保证Topic所有分区都是有序的。
所以 Kafka 要保证消息的消费顺序,可以有2种方法。
二、1个Topic(主题)只创建1个Partition(分区)
1个Topic(主题)只创建1个Partition(分区),这样生产者的所有数据都发送到了一个Partition(分区),保证了消息的消费顺序。
三、生产者在发送消息的时候指定要发送到哪个Partition(分区)
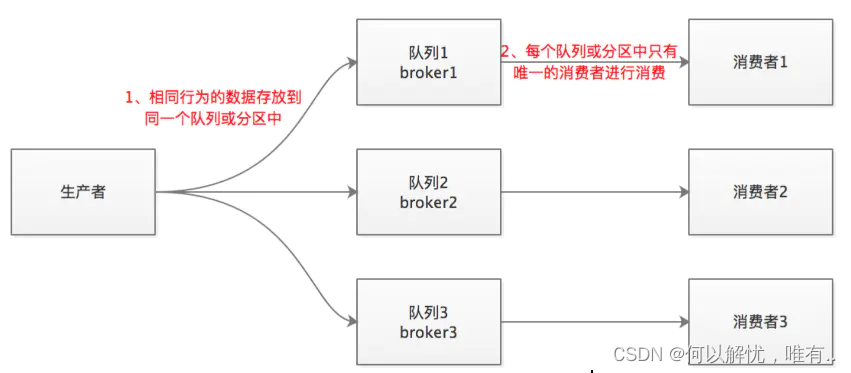
那么问题来了:在1个topic中,有3个partition,那么如何保证数据的消费?
a、相同行为的消息存放到同一个MQ服务器中
b、最终只会有单个消费者去消费

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









