



- 开场白
- 访谈环节Tensor 为什么和设备有关
- Tensor 在设备上的分布怎么计算
- 形式化表达
- 从具体分布倒推设备矩阵
- 问题分析实战
- Tensor 在设备上的分布怎么计算
- 自由提问环节
- 大腿带躺环节
- 免责声明
- 致谢
开场白
【主持人致辞】: 大家好,欢迎大家莅临本期的《重生之大腿带我征服 MindSpore》栏目。今天,我们很荣幸地邀请到并行大神-->小章哥哥,带领我们探索在 mindspore 中tensor 的分布策略,欢迎小章哥哥!!
【小章哥哥】: 咳咳咳,谢谢大家。
【观众】:鼓掌!
【小章哥哥】:你这个栏目的名字为什么这么奇怪,为什么叫 《 Tensor 失忆了,请别让他被坏设备拐走了!》,我大概理解你的意思,就是有点奇怪。
【主持人】:嗯嗯,是的,我回去看看一下。 其实是因为我是《标题党》
============【快速进入正题】 ==========
【主持人】本期栏目聚焦于在多个设备的场景,需要对某一个数据进行切分时,计算该部分数据归属于哪一个设备。也就是说,假如大家是一个 Tensor,面临着切分的情况,即需要把自己分给若干个设备,如果去错了设备,就会导致计算错误。因此,请不要让某个设备把不属于自己的 Tensor 带回家! (强行点题)
访谈环节
Tensor 为什么和设备有关
【问题1】:小章哥哥,在 mindspore 中,Tensor 和设备有什么关系呢?它不是就是在某台机器上申请的,为什么会和设备有关呢?
【小章哥哥】:咳(战术清嗓),是这样的,如果你是在单卡上跑程序的话,那么你的理解是对的。但是,在大模型训练的时候呢,往往一张卡是存不下这个模型下的所有 tensor 的,这个卡你就理解为设备,比如910A,910B什么的。然后呢,当你模型很大的时候,就需要对它里面的 tensor 做一些拆分,可能是某一个 tensor 不同卡上,这个叫做模型并行。也可以是连续几层的 tensor 在某一张卡,然后另外几层的 tensor 在另外一张卡,这个就叫做流水行并行。这样呢,你就要知道哪些 tensor 会被放到哪些设备上,然后把它的计算结果整合起来。
【主持人】:噢噢,就是说某一个 tensor 可能被拆分到多个设备上,这个就是模型并行。然后连续几层的tensor 被拆分到多个设备上,这个就是流水并行。
【小章哥哥】:差不多吧。
Tensor 在设备上的分布怎么计算
【问题2】:小章哥哥,既然一个模型的 tensor 可能在多个设备上进行分布,那么某个tensor 会被分配到哪个设备上,这个应该怎么算呢?
【小章哥哥】:我举一个简单的例子吧,模型并行呢,就是说要把一个权重分开放到不同的设备上,先算一下2张卡的情况。MatMul 是现在大模型里面最常用的算子之一了,这里我就结合 matmul 来讲了。MatMul 不是有2个输入吗,我们记成 XX 和 WW, 那matmul 的输出可以记成 Y=XWY=XW。
我们一共有2张卡,那就有 Y=[X1,X2][W1W2]=X1W1+X2W2Y=[X1,X2][W1W2]=X1W1+X2W2,
这里的 X 做的是列切,就是说一个shape是 [512,512] 的向量,会被切成2个 [512, 256]的向量。W 做的是行切,是一个 shape 是 [512,512] 的向量被切成shape 是 [256, 512] 的两个向量。
那咱们一共两张卡,X1,X2,W1,W2X1,X2,W1,W2 怎么放呢?
可以看到 X1,W1X1,W1 会进行计算,X2,W2X2,W2 会进行计算,那么很自然地,我们就会认为 X1,W1X1,W1 会放在 0卡,X2,W2X2,W2 就会放到 1卡。因为不可能你去别的卡拿数据,也就是做通信,然后再运算。
【主持人】:噢噢,这个懂了。但是这个是手算的,有没通用的公式或者算法啥的。
【观众】:(内心OS:就这就这?)
【小章哥哥】:(内心OS:哼哼,好戏才开始)
好的,这个大家都懂了吧,接下来咱们弄一个难一点的。
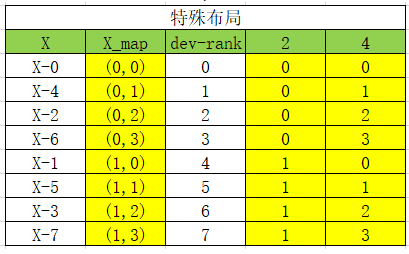
还是一个 MatMul,但是输入X 的切分策略是(2,4),横切两刀,纵切4刀。输入W的切分是(4,2),横切4刀,纵切两刀。那照这样呢,就需要 16 张卡对吧,那我们就把 X 和 W 的分布画一下(注意,后面会用该分布来计算坐标):
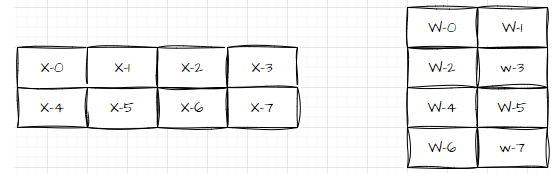
【某观众】:(这是弄啥嘞?)X-0 -> W-0, X-1 -> X-1, ... ,
【小章哥哥】:现在我们要给 X 和 W 找到对应的设备的 rank,我们先画把 rank 按顺序写出来:
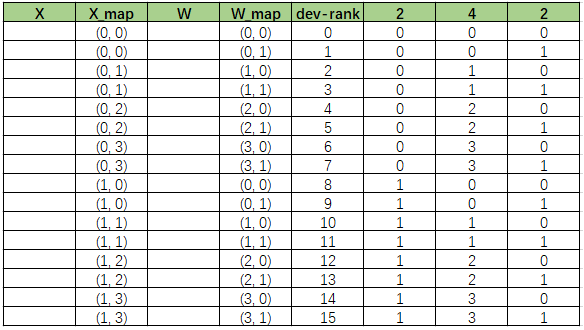
注意到,前面我们给 XX 和 WW 设置的分布分别是(2,4),(4,2)。因为这里的 4是相关维(即对应相乘),所以可以缩写成 (2,4,2),这个就叫做设备矩阵(device-matrix). 然后我们再把对应的3列进行扩写。 X-map 就是对应3列中的前2列,W-map 就是后2列,然后我们就可以填充 X_map 和 W_map,这两个map 组装起来的值也叫做张量映射(tensor map),维度和 device-matrix 一致。
【某观众】:神游太虚~
【某观众】:嚯,这位爷注意力惊人呐~
【 ===== 敲敲小黑板 =====】
好了,有了这张表呢,我们就算一下Tensor 每一个部分的位置吧。
以 X-5为例,X的分布是(2,4),他的坐标就是(1,1),所以我们需要找到 X_map 为 (1,1)的格子,给他填上 X-5。可以看到,rank 10 和 rank 11 这里的高2维是 (1,1),所以我们 X-5 对应的格子就是 rank 10,rank 11.
然后咱们再算一下 W-3,W-3的排列是(4,2),所以它的坐标也是(1,1),我们找到 W_map 为(1,1)的格子,分别是 rank 3和 rank11.所以W-3 放的位置就是 rank 3和 rank 11.
形式化表达
那么,有没有形式化的表述呢?当然是有的。对于设备矩阵 [m1,m2,m3][m1,m2,m3], tensor 的索引 [k1,k2,k3][k1,k2,k3], 对于张量映射对应的高维 tensor,其对应的索引为 k1,k2k1,k2, 则其对应的 rank 索引为 k1∗(m2∗m3)+k2∗m3+[0...k3]k1∗(m2∗m3)+k2∗m3+[0...k3]。
接下来,我们做一下验算。以X-5 为例,其坐标为 [1,1], 其索引为 1∗(4∗2)+1∗2+[0,1]=[10,11]1∗(4∗2)+1∗2+[0,1]=[10,11].
类比地,对于低维 tensor,其索引为 k2,k3k2,k3, 其对应的 rank 索引为 [0−k1]∗(m2∗m3)+k2∗m3+k3[0−k1]∗(m2∗m3)+k2∗m3+k3。我们以 W-3 为例做一下演算,其坐标为 [1, 1], 则有其rank 索引为 [0,1]∗(2∗4)+1∗2+1[0,1]∗(2∗4)+1∗2+1 = [3, 11]。
【小章哥哥】:当然,这里我只是做了简单的讲解,深度比较浅,有兴趣继续探索的同学可以参考者自己查阅 mindspore 的源码。 这样,我们就可以得到如下的表,得到 X 和W 每个部分在设备上的分布了
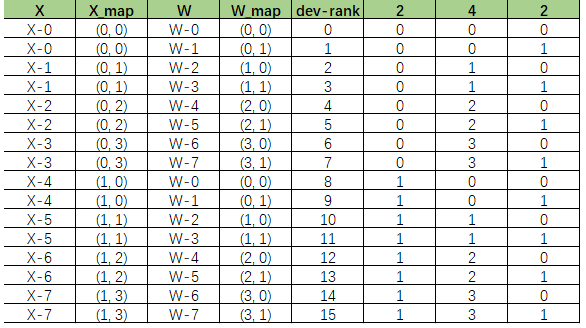
从具体分布倒推设备矩阵
【主持人】小章哥哥!这个tensor_map 有啥用啊,目前我们都没用过呀。
【小章哥哥】别急,来了(哼哼)。
我们目前的格式矩阵通常都是按顺序的,例如这种排布:
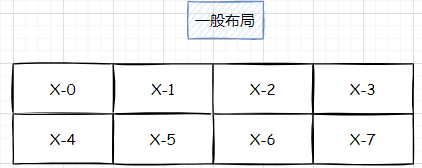
它对应的设备矩阵排布如下:
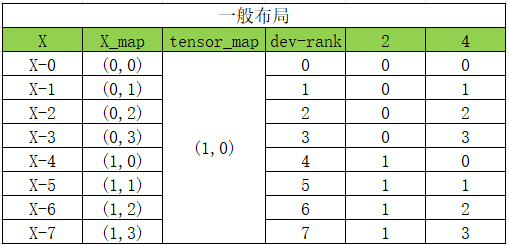
当然,他也可以做到这样的分布,调转 tensor_map 从(1,0) 到(0,1):
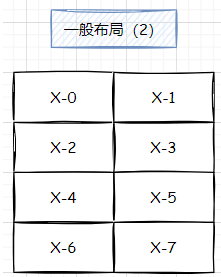
对应的表格如下:
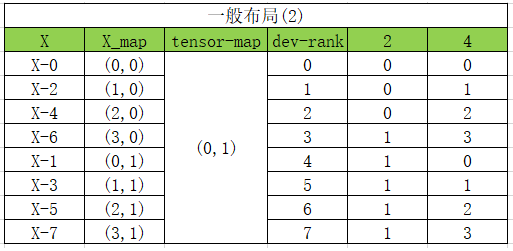
由于这里的 tensor-map 是(0,1) 与 device matrix 的默认编号(1,0) 不同,所以X_map 这里需要做一个映射。因此, X_map 这一列的值与设备矩阵最右侧的排列是相反的。
那假如,我们想要任意分布的情况,例如如下的情况,怎么做到呢?
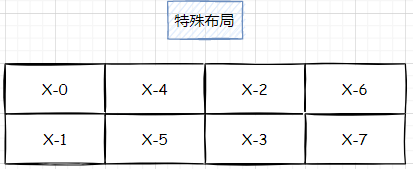
依葫芦画瓢,发现写出的设备矩阵排布是这样的,但是我们无法得到一个 tensor map 来做形式化表达!
例如 X-4 我们期望他在 rank_1,但是 (0,1) 无论怎么调换顺序,都无法得到 4, 只能得到 0∗2+1∗1=10∗2+1∗1=1 或者 1∗2+1∗0=21∗2+1∗0=2 这两种结果。
【注】:这里代表tensor map 的高低维切换。
那两维做不到,那我们试试三维?
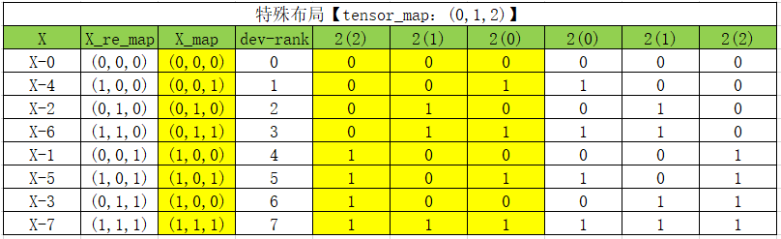
诶,是不是可以?我们来看看 X_re_map 的实现,这个和我们默认的tensor map 的顺序就是调换了一下高维和低维的顺序。也就是说,通过tensor_map 从(2,1,0)变化到 (0,1,2),就可以找到特定排布对应的设备矩阵和tensor map。
问题分析实战
【主持人】:振章哥哥,目前大家应该消化好了相关内容,有没有相关的问题可以让大家实践一下呢?
【小章哥哥】:嗯,我也觉得可以。这里有一个切分策略的问题,看看大家能不能看出来什么问题。
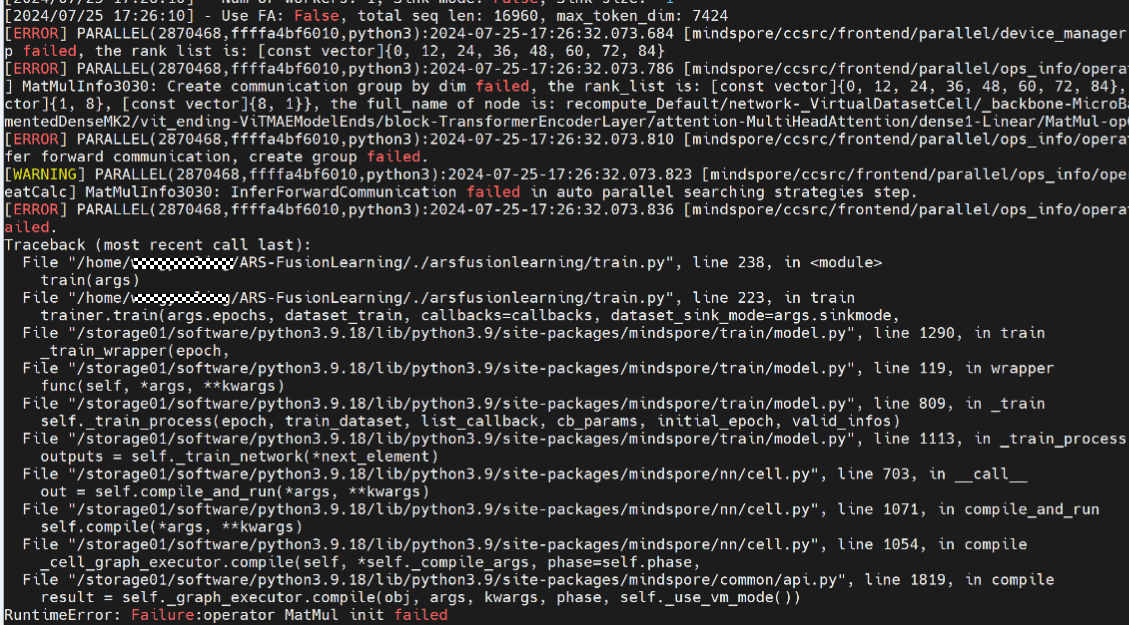
【现场】:很安静,只有🖊在纸上摩擦的声音。。
【观众1】:(喃喃自语)matmul 的策略是 (1,8),(8,1). rank list 怎么是 0, 12, 24, ... ?
【观众2】:这不是 8卡吧? 超纲了~
【小章哥哥】:我看大家都弄得差不多了,我们一起看下有什么问题。
这里的报错主要是创建通信组失败。可以看到根因是 matmul 算子初始化失败,他的策略配置的是(1,8),(8,1).按照预期来说,matmul 配置列切时,其只在单机内走 AllReduce,也就是说它对应的 rank_list 应该是{0-7}。
并且,如果配置了dp、pp等策略的话,tp的优先级也会是最高的,这里的优先级指的是单机内的分配顺序。例如 dp=tp=pp=2 时候,tp 通信组共有4个,分贝是{0,1}, {2,3}, {4,5}, {6,7}。 dp 的通信组是{0,2}, {1,3}, {4,6}, {5,7}.
只有在重复计算的情况下,tp的优先级才会变低。重复计算就是说,你有1个模型,但是你设备没有用满,导致不同的设备做重复的计算。最简单的就是 4卡的情况,matmul 配置的策略是(1,2),(2,1),这样呢,就会导致{0,2},{1,3} 卡做重复计算。
回到我们的问题,这里的原因可能是配置了96卡,但是只配置了(1,8),(8,1) 的策略,导致 tp 对应的allreduce 通信域跨机,我们把策略改成(12,8),(8,1) 就可以了。
自由提问环节
大腿带躺环节
免责声明
本文中提到的人物对话【纯属虚构】,如有雷同,纯属巧合,请【勿对号入座】。
致谢
感谢本期嘉宾:小章哥哥
感谢本栏目的常驻嘉宾:bin总。
感谢以下工作人员:我自己。
感谢观众。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









