




视频讲解1:BiliBili视频讲解
视频讲解2:https://www.douyin.com/video/7578709508256582918
论文下载:https://arxiv.org/abs/2303.02001
代码下载:https://github.com/cvlab-stonybrook/zero-shot-counting
基于Zero-Shot的计数算法详解(T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting)
统一的人群计数训练框架(PyTorch)——基于主流的密度图模型训练框架
算法VLCount详解(VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting)
人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
基于Zero-Shot的目标计数算法详解(Open-world Text-specified Object Counting)
目录

现有方法的局限性
1类别特定计数方法的封闭性局限
类别特定对象计数方法专注于计数预定义类别(如人群、车辆、动物等),这些方法可分为基于检测的方法和基于回归的方法。它们的核心局限性在于封闭世界假设——只能识别训练过程中见过的特定类别。当需要计数任意未知类别时,这些方法完全失效,无法适应开放世界的实际应用需求。
2 类别无关计数方法对人工样例的依赖
类别无关计数方法通过少量视觉示例指定要计数的对象类别,如GMN、FamNet、BMNet等方法。虽然这类方法可以处理未知类别,但存在两个关键缺陷:需要人工标注样例:推理时必须由用户提供目标对象的边界框示例,这在自主系统中不切实际;操作流程复杂:需要人工介入提供示例,限制了在野生动物监测、视觉异常检测等全自动系统中的适用性。
3 现有无示例计数方法的局限性
RepRPN是当前唯一的无示例类别无关计数方法,它通过区域提议网络识别图像中出现最频繁的对象作为计数示例。然而,这种方法存在严重缺陷:
•无法指定目标类别:只能计数图像中占主导地位的类别,无法根据用户需求计数特定类别;
•适用场景有限:仅适用于单一主导类别的图像,在多类别场景中完全失效。

提出方法
针对上述局限性,本文提出了零样本目标计数新任务,仅需类别名称即可计数特定类别的对象实例,无需任何人工标注样例。如图1所示,ZSC使计数系统能够完全自主运行,用户只需提供类别名称即可指定计数目标。
1 两阶段示例块选择框架
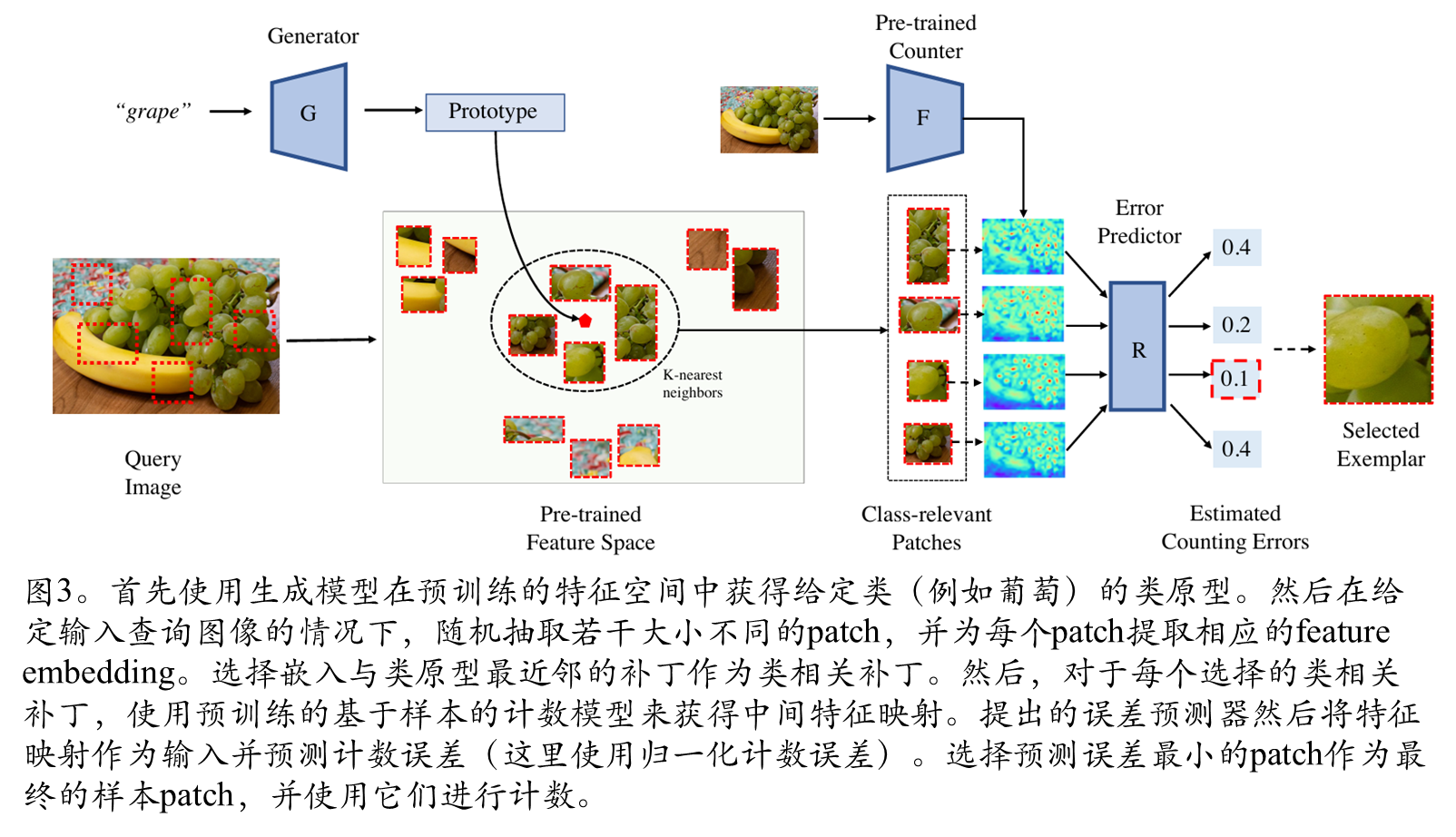
本文核心创新在于提出了一个两阶段示例块选择方法,能够自动识别输入图像中最适合作为计数示例的图像块。
1.1 基于类原型的类别相关块选择
首先通过条件变分自编码器在预训练特征空间中生成类原型,用于识别包含目标对象的图像块:类原型生成:训练条件VAE模型,根据类别的语义嵌入生成对应类别的特征表示。给定目标类别名称y,通过解码器生成特征集合Gy,并计算其均值作为类原型p^y。类别相关块选择:在查询图像中随机采样多种尺寸的图像块,提取其ImageNet特征,选择与类原型距离最近的k个近邻作为类别相关块。
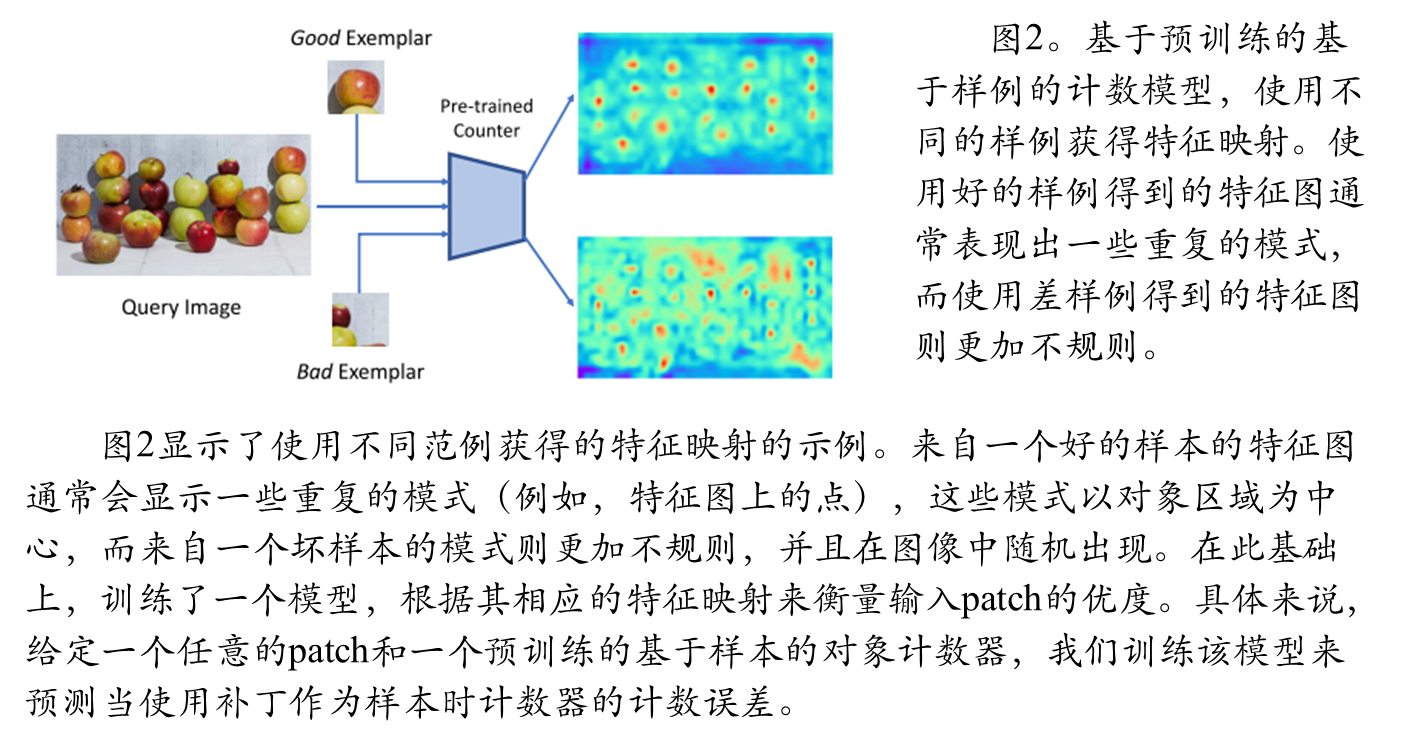
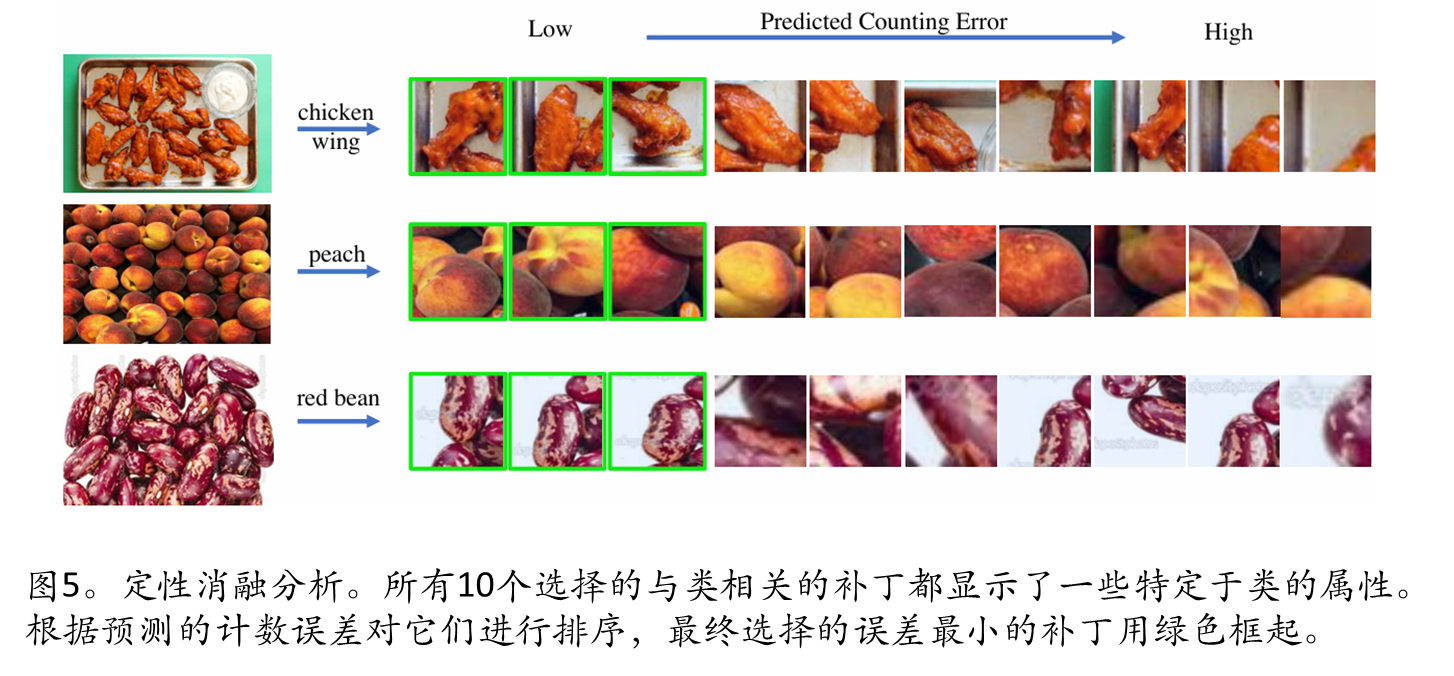
1.2 基于误差预测器的最优示例选择
本文训练了一个误差预测器来定量评估任意图像块作为计数示例的适用性:预测基础计数模型使用该示例块时的计数误差,误差越小表明示例质量越高;从类别相关块中选择预测误差最小的top-s个块作为最终计数示例。
2 基础计数模型架构
基础计数模型采用基于示例的计数架构,包含特征提取器F和计数器C:使用ResNet-50 backbone提取查询图像和示例块的特征;通过特征相关性计算相似度图;将图像特征图与相似度图拼接后输入计数器,预测密度图并求和得到最终计数。
具体方法
好的样例和差的样例选择
训练基础统计模型

类别原型生成

类别相关的patch选择

选择样例patch用于统计

FSC_147数据集介绍
1 数据集背景与定位
FSC-147(Few-Shot Counting 147)是第一个大规模类别无关计数数据集,专门为推进少样本和零样本物体计数研究而创建。该数据集突破了传统类别特定计数(如只计数人群、车辆)的限制,使模型能够计数任意类别的物体实例。其核心目标是开发通用型物体计数器,仅需少量示例(甚至零示例)即可计数从未见过的新类别。
2 数据内容与统计信息
根据文档内容,FSC-147数据集包含6,135张图像,覆盖了147个完全不同的物体类别。这些类别具有极高的多样性,涵盖了动物、厨房用具、交通工具等各种日常物品。
数据集划分特点:
- 训练集:包含来自89个类别的图像
- 验证集:包含来自29个类别的图像
- 测试集:包含来自29个类别的图像
- 关键特性:训练集、验证集和测试集中的类别是完全不相交的,这确保了评估的公平性,能够真实反映模型对全新类别的泛化能力。
标注信息:
- 每张图像都标注了物体中心的点级标注,可用于生成真实密度图(npy格式)
- 提供每个图像的类别名称信息
- 为每张图像提供3个视觉示例(边界框box),用于指定要计数的物体
实验结果
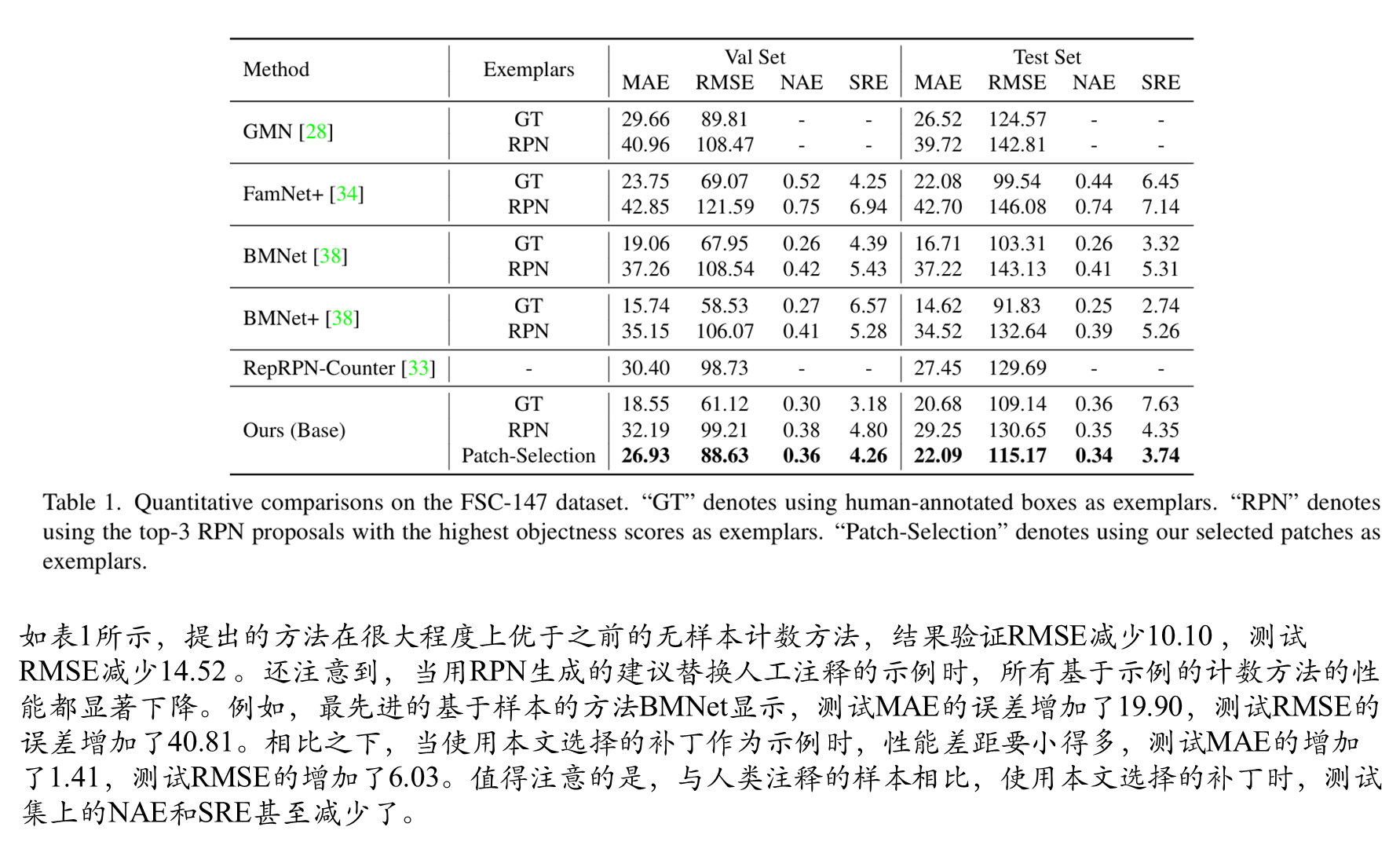
综合比较
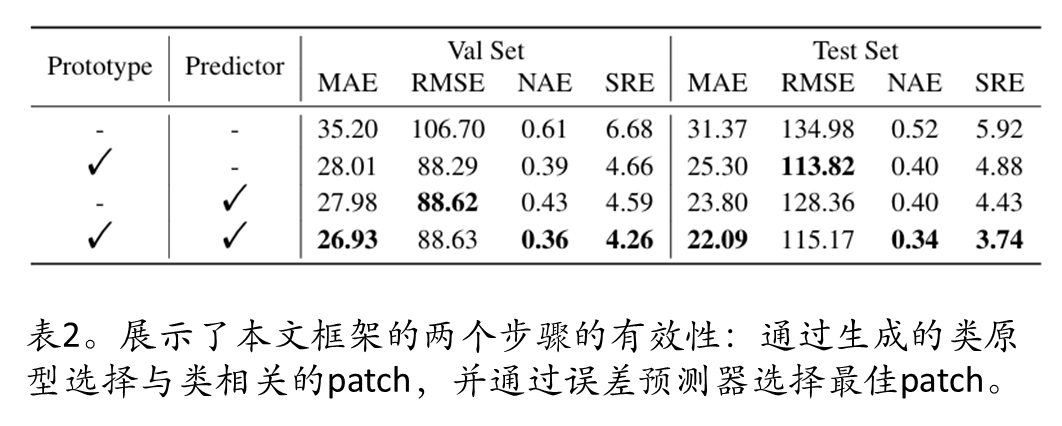
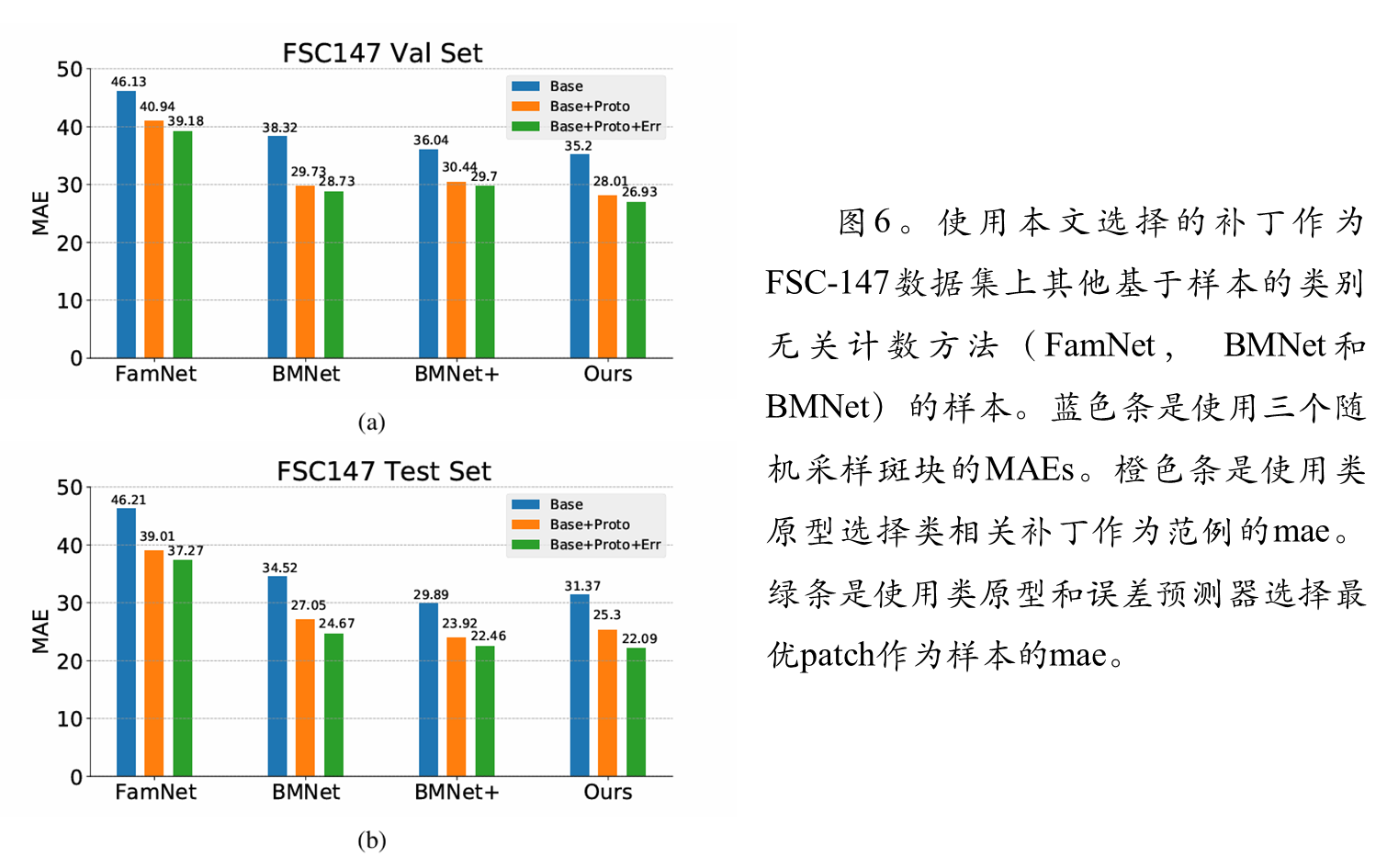
消融结果
可视化结果




















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









