






视频讲解1:https://www.bilibili.com/video/BV1nLn3zvEoJ/?pop_share=1&vd_source=b2eaaddb2c69bf42517a2553af8444ab
视频讲解2:https://www.douyin.com/video/7554304018835705103
主页:https://minigpt-v2.github.io/
论文下载地址:https://arxiv.org/abs/2310.09478
代码下载地址:https://github.com/Vision-CAIR/MiniGPT-4
目录
Visual Question Answering (VQA) — 视觉问答
Referring Expression — 指代表达(理解/解析)
Grounded Image Caption — 带定位的图像描述(可看作“有根源的图像描述”)
Region Identification — 区域识别 / 区域定位
Object parsing and grounding—目标解析和定位输出
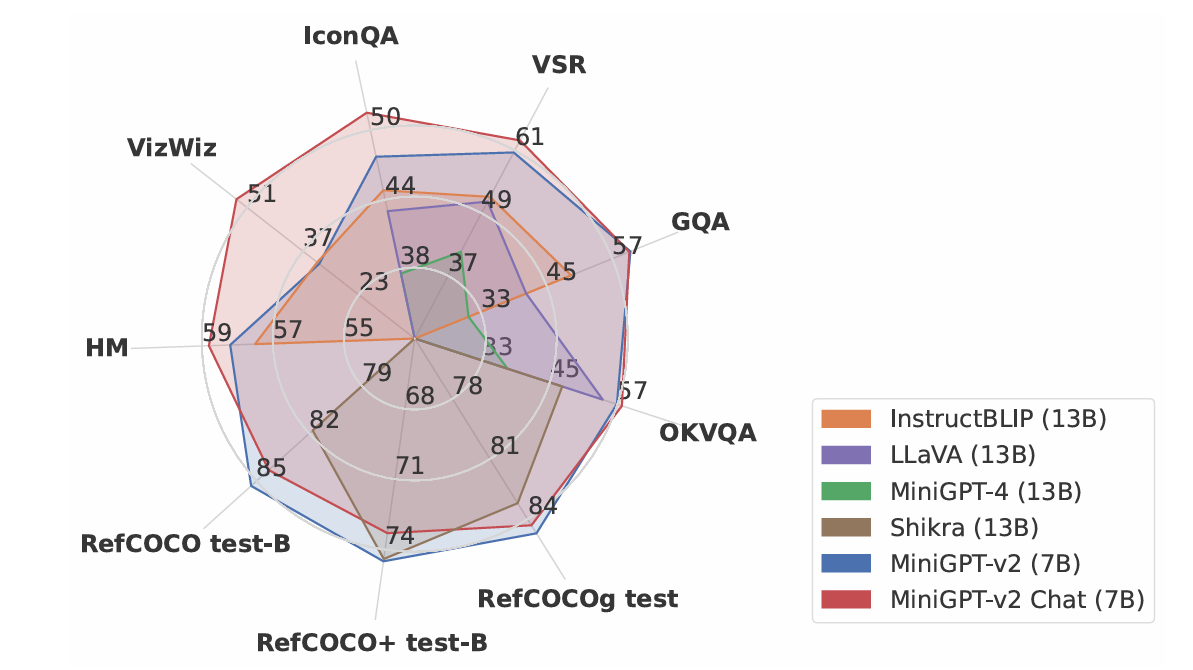
- Visual Question Answering (VQA) — 视觉问答
- Image Caption — 图像描述 / 图像字幕
- Referring Expression — 指代表达(理解/解析)
- Grounded Image Caption — 带定位的图像描述(可看作“有根源的图像描述”)
- Region Identification — 区域识别 / 区域定位
- Object parsing and grounding—目标解析和定位输出
- object identification—目标身份验证
Visual Question Answering (VQA) — 视觉问答
•定义:给定一张图片和一个关于图片的自然语言问题,模型需要基于图像(和问题)给出一个正确的答案(通常是短文本:单词、短语或数字)。
•输入:图像 + 问题(自然语言)
•输出:答案(文本,可能是短语或分类标签)
•核心目标:理解图像内容并结合问题推理、识别细节、计数、比较等能力。
•典型示例:图像 + “图片里有多少个人?” → “3”
•注意点:答案与问题紧密相关;可能需要世界知识或视觉常识;通常不要求返回图像区域(但一些扩展任务会要求提供根据问题定位到的区域)。
Image Caption — 图像描述 / 图像字幕
•定义:给定一张图片,自动生成一段自然语言描述,概述图片中重要的实体、动作与情境。
•输入:图像
•输出:完整句子或多句的描述(开放式文本)
•核心目标:生成连贯、自然并且语义准确的描述,覆盖主要内容与重要关系。
•典型示例:图片 → “一位小女孩在沙滩上玩沙子”
•注意点:注重流畅性与全面性,但通常不需给出具体像素或边界框;评估偏向语言学指标(BLEU、CIDEr等)与人工评价。
Referring Expression — 指代表达(理解/解析)
•定义:涉及两方面:
•生成(Referring Expression Generation, REG):根据一张图像和目标对象生成一个能唯一或明确指代该对象的短语/句子(如“左边穿红衣服的女孩”)。
•解析/理解(Referring Expression Comprehension, REC):给定图像与一条指代表述,模型需要识别并定位该指称对象(通常输出边界框或像素掩码)。
•输入:图像 + 指代表达(理解任务) 或 图像 + 目标对象(生成任务)
•输出:定位(边界框/掩码)或生成的指代表达文本
•核心目标:在视觉上下文中实现精确的对象歧义消解(在多对象环境中能唯一指明目标)。
•典型示例:图像 + “穿黄色衬衫的人” → 返回该人的边界框。或给定目标(某人)生成“坐在椅子上的老人”。
•注意点:强调区分性(uniqueness),需要考虑上下文中其它对象以避免歧义。

Grounded Image Caption — 带定位的图像描述(可看作“有根源的图像描述”)
•定义:生成图像描述的同时将描述中的实体与图像中的具体区域进行对齐(grounding)。也可以理解为:在生成caption时,提供每个名词短语或实体对应的边界框或掩码。
•输入:图像(通常不额外输入文本)
•输出:自然语言描述 + 对应的区域对齐信息(每个提到的对象对应一个或多个边界框/掩码)
•核心目标:让描述中的内容可被追溯到图像具体位置,从而提高描述的可解释性与精确性。
•典型示例:输出 “一只棕色的狗在草地上” 并同时给出狗的边界框。
•注意点:融合了Caption与定位信息,常用于可解释视觉描述、视觉对话中的引用消解等。
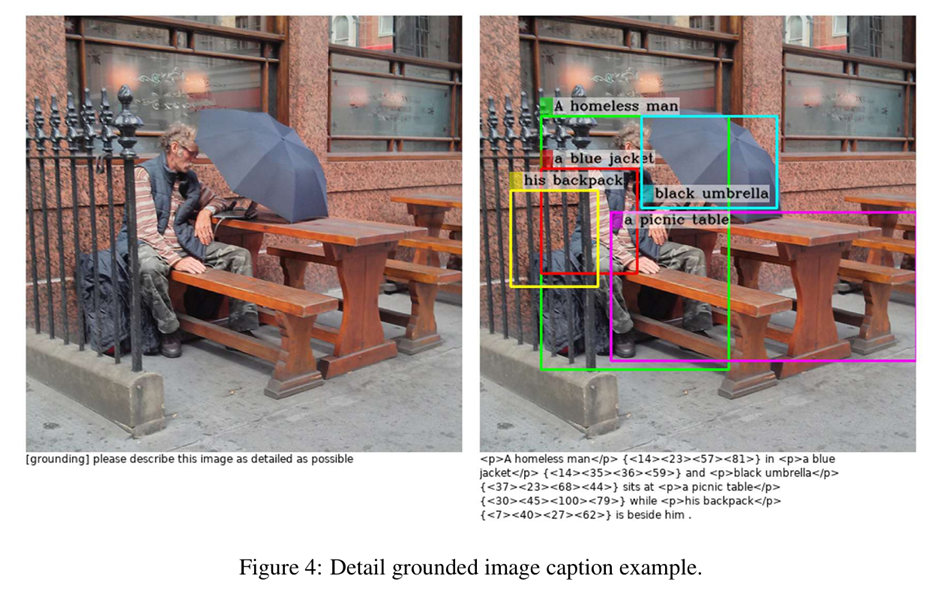
Region Identification — 区域识别 / 区域定位
•定义:一般指在图像中识别并返回与某个查询(可以是文本、类别、属性或示例区域)对应的区域(边界框或掩码)。这是一个较广泛的类别,包含目标检测、语义分割、实例分割、以及基于文本的区域检索等任务。
•输入:图像 + 查询(可选:类别标签、文本描述、示例掩码等)
•输出:一个或多个边界框/掩码(指出相关区域)
•核心目标:精确定位图像中的目标区域。
•典型示例:目标检测:图像 → “检测出所有车辆并返回边界框”;基于文本的检索:图像 + “红色车” → 返回红色车的框。
•注意点:常是视觉任务的基础模块;如果查询是自然语言,则它与指代表达理解有交集。
Object parsing and grounding—目标解析和定位输出
•输入:图像(通常可带上文本描述或查询),有时还包括目标的粗略标注或示例区域。
•输出
•结构化的解析表示(比如目标的部件列表、属性、关系)+ 每个元素对应的定位信息(边界框、像素级掩码或关键点)。
•例:对一辆车的解析输出可能是:{车身: box1, 车轮: [box2, box3, box4, box5], 车牌: box6, 颜色: “红色”}。

object identification—目标身份验证
•输入:图像区域(或整图),有时还需一个参考(例如候选实例的图像或身份描述)。
•输出:类别标签(类别级)或匹配/不匹配的验证结果、或一个实例ID(实例级)。
•例:输入为一张人脸图和数据库中的人脸A,输出“匹配/不匹配”或概率评分;或输出“这是第1234号车辆(数据库ID)”。
•目标 / 关注点
•精确识别对象的身份(类别或实例),在实例级场景中强调辨别微小外观差异、鲁棒性与判别性。在安全/跟踪/检索等场景下非常重要(如人脸验证、商品识别、车辆重识别)。

| 任务 | 输入 | 输出 | 目标 / 关注点 | 与其它任务的关系 |
| Visual Question Answering (VQA) | 图像 + 问题(NL) | 文本答案(短) | 回答关于图像的问题,涉及理解与推理 | 可结合定位(通过可解释VQA或带定位的VQA)来提升可解释性 |
| Image Caption | 图像 | 一段自然语言描述 | 流畅、全面地描述图像内容 | 不要求显式定位;Grounded Caption 在此基础上增加了对齐信息 |
| Referring Expression (REG/REC) | 图像 + 指代表达(或目标对象) | (生成)文本指代表达 或 (理解)边界框/掩码 | 在上下文中唯一/明确地指代某对象(生成)或解析指称(理解) | REC 与 Region Identification 在定位上高度重合;REG 与 Caption 生成有语言生成相似性 |
| Grounded Image Caption | 图像 | 文本描述 + 每个实体对应的区域(框/掩码) | 生成可对齐到具体区域的描述,提高可解释性 | 结合了 Caption(语言生成)与 Region Identification(定位) |
| Region Identification | 图像 + 查询(可选) | 边界框 / 掩码(一个或多个) | 精确定位图像中的目标区域 | 基础视觉任务;作为 VQA/REC/Grounded Caption 的模块或评估依据 |
| Object identification | 图像区域(或整图) + 可选参考/数据库 | 类别标签 或 匹配/不匹配 / 实例ID | 确认目标类别或具体实例身份 | 更细粒度且结构化,结合了语义分解与 Region Identification / Grounded Caption 的对齐能力 |
| Object parsing and grounding | 图片 + 文本目标描述 | 所有相关目标坐标+图像中目标标注结果 | 精确定位描述的目标和标注结果 | 与 Region Identification 互补:先定位(Region ID)再验证身份;与 VQA/Caption 有交叉(当问题或描述涉及“是谁/是什么实例”时) |
综合例子

b) detailed grounded image captioning(详细的描述图片中的内容 + 目标定位);
c) visual question answering(输入图片+文本,根据图像回答文本描述的内容,内容宽泛);
d) referring expression comprehension(输入图像 + 目标对象,输出目标对象的定位结果);
e) visual question answering under task identifier(图片 + 目标身份验证,回答目标身份结果,目标确定);
f) detailed image description(输入图片 + 文本,详细的输出图像描述,不用标注目标位置);
g) object parsing and grounding from an input text(图片 + 目标描述,输出目标定位之后的图像以及目标文本描述).




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









