






目录
论文Distribution Matching for Crowd Counting中人群统计损失(C Loss),最优化传输损失(OT Loss)以及总的变化损失(TV Loss)
论文Distribution Matching for Crowd Counting详解
论文The Effectiveness of a Simplified Model Structure for Crowd Counting(FFNet)详解
本文主要是对人群计数中常用的数据集的相关介绍以及使用方式,之所以特意的抽时间来写这篇博文,主要是最近发现比较多的小伙伴(刚进入这个领域)在人群计数数据集上容易迷茫。如果一个一个的为大家进行解答的话,还不如直接写一篇文章来更加细致的给大家讲解一下,下面呢主要是讲解一些常用的数据集,如果明白这些常用数据集的格式之后,其他数据集应该也是差不多的方式进行使用。虽然我们都可以在网上找到相关数据集的下载地址(因为这些数据集本身就是开源的),但是最主要还是弄懂这些数据集的结构以及使用方式才是最重要的。如果在讲解的过程中有什么不对的地方,还请大家能够指出(ヾ(◍°∇°◍)ノ゙)。
1.常用人群数据集大致汇总
| 数据集 | 平均分辨率 | 图像人群数 | 总的人群数 | 图像最小人群数 | 图像最大人群数 | 图像平均人群数 | 下载链接 |
|---|---|---|---|---|---|---|---|
| NWPU-Crowd[1] | 2191x3209 | 5109 | 2133375 | 0 | 20033 | 418 | NWPU-Crowd |
| JHU-Crowd++[2] | 1450x900 | 4250 | 1114785 | 0 | 7286 | 262 | JHU-Crowd |
| UCF_QNRF[3] | 2013x2902 | 1535 | 1251642 | 49 | 12865 | 815 | UCF_QNRF |
| ST Part A[4] | 589x868 | 482 | 241677 | 33 | 3139 | 501 | ST Part A |
| ST Part B[5] | 768x1024 | 716 | 88488 | 1 | 578 | 124 | ST Part B |
| 所有有关人群统计数据集的下载地址 | |||||||
| 人群统计中生成密度图的代码 | |||||||
2.NWPU-Crowd数据集介绍
-- NWPU-Crowd
|-- images
| |-- 0001.jpg
| |-- 0002.jpg
| |-- ...
| |-- 5109.jpg
|-- jsons
| |-- 0001.json
| |-- 0002.json
| |-- ...
| |-- 3609.json
|-- mats
| |-- 0001.mat
| |-- 0002.mat
| |-- ...
| |-- 3609.mat
|-- train.txt
|-- val.txt
|-- test.txt
|-- readme.md2.1 数据集分布
| 数据集 | train | val | test |
|---|---|---|---|
| NWPU-Crowd | 3109 | 500 | 1500 |
注:只有train(训练集)和val(验证集)提供了对应的标签,test(测试集)没有对应的标签。
2.2 数据集格式
数据集提供 *.jpeg 图像和两种标签(json 和 mat),点的顺序是 x, y。.mat 文件的内容与 UCF-QNRF 一致。框标签为 xmin, ymin, xmax, ymax。
- 在 train.txt 和 val.txt 中,每行有三项:图像 ID,亮度标签和场景等级。
- 在 test.txt 中,每行只有一项:图像 ID(其实你去看下载数据集中的test.txt时,每一行实际有三项:图像 ID,亮度标签和场景等级)。
以train.txt(训练集)文件中几幅图像信息作为例子:
0001 1 1
0002 1 0
0003 2 0
0004 1 2
0005 1 1
0006 1 3【对应图像文件名(ID) 亮度标签 场景等级】
2.3 数据来源
数据来源于自拍和互联网。前者约有 2,000 张图像和约 200 个视频序列,这些数据是在一些繁华的中国城市中拍摄的,包括北京、上海、重庆、西安和郑州,涵盖了典型的人群场景,如度假胜地、步行街、校园、商场、广场和车站。然而,极度拥挤的人群场景在现实生活中并不可常见,这也很难通过自拍获取。还从一些图像搜索引擎(如 Google、百度、必应、搜狗等)收集了约 8,000 个样本,使用与人群相关的典型查询关键词。表 2 列出了主要的数据源网站及相应的关键词。表格的第三行记录了一些中文网站和关键词。最终,通过上述两种方法,获得了 10,257 张原始图像(论文里面提到最后将收集的数据集需要过滤和清洗,至于清洗的方式是什么具体请看论文)。

2.4 注释工具
论文为了方便地为人群图像中的头部标注点,开发了一种基于 HTML5 + JavaScript + Python 的在线高效注释工具。该工具支持两种标签形式,即点和边界框。在注释过程中,每张图像可以灵活地放大或缩小,以不同的尺度标注头部,图像最多被划分为 16 × 16 的小块,这使得标注者可以在五种尺度下对头部进行标注:2i(i=0,1,2,3,4)倍于原始图像的大小。该工具有效提高了注释速度和质量。更详细的描述在我们提供的补充材料的视频演示中展示。
2.5 点对点注释
整个数据集注释过程分为两个阶段:标注和细化。首先,有 30 名注释员参与初始标注过程,消耗了 2,100 小时,总计对所有收集的图像进行标注。之后,6 名人员负责细化初步的注释,这一阶段每人耗时 150 小时。总的来说,整个注释过程耗费了 3,000 人工小时。
2.6 框级注释和生成
注释框标签共有三个步骤:
- 1)对于每张图像,手动选择约 10% 的典型点以绘制其对应的框,这些框可以代表整个场景中的尺度变化;
- 2)对每个没有框标签的点,采用线性回归算法根据其 8 个最近的箱体标记邻居来获取其框大小;
- 3)手动细化预测的框标签。步骤 1)和 2)总共耗费 1,000 人工小时。
在这里,步骤 2)描述如下:对于一个没有框标签的头部点 P0,其 8 个最近的框标签邻居 (P8) 被用来拟合线性回归算法 [5],在该算法中,纵坐标是变量,框大小是因变量。根据线性函数和 P0 的纵坐标,可以得到对应的框大小。假设每个框的形状为正方形,点的坐标是其中心,然后可以得到框的大小。显然,线性回归的结果并不可靠,因此我们在步骤 3 中应手动细化预测的框标签。接下来,线性回归和手动细化的过程将不断循环,直到所有框都被验证合格。在注释阶段,步骤 2)和 3)会重复进行四次。
2.7 查看点标注坐标保存格式
npy_path = r'D:\conda3\Transfer_Learning\CrowdDataset\datasets\NWPU\mats\mats\3110.mat'
mat = loadmat(npy_path)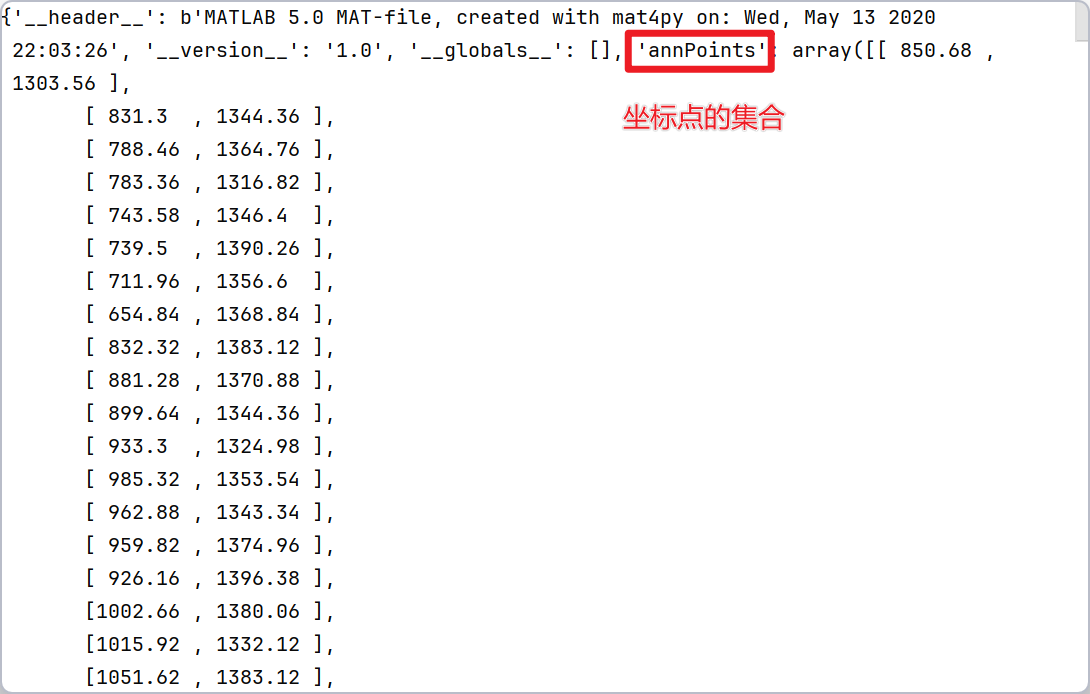
获得字典mat中包含的坐标点集合
points = mat['annPoints'].astype(np.float32)3 JHU-Crowd++数据集介绍
Pushing the Frontiers of Unconstrained Crowd Counting: New Dataset and Benchmark Method

如果你去搜索JHU-Crowd数据集话也可能会查看这里给出的额论文链接,其实是相同的作者给出的数据集论文,从上面官网找到的JHU-Crowd++是技术报告,JHU-Crowd是2019发表在ICCV会议上的。
-
2019年 ICCV 论文:
-
提出 JHU-CROWD 初始版本,包含约 1.25 百万标注,覆盖多种场景(如天气变化、光照差异)。
-
主要关注无约束环境(如雾、雨、雪)下的计数挑战,但数据规模相对较小。
-
-
2020年 TPAMI 技术报告:
-
升级为 JHU-CROWD++,扩展至 4,372 张图像和 1.51 百万标注,成为当时最大的人群计数数据集之一。
-
新增更多极端天气和复杂场景(如夜间、遮挡),并引入更丰富的标注类型(如模糊级别、近似边界框)。
-
3.1 数据集下载
3.2 JHU-Crowd++数据集特点
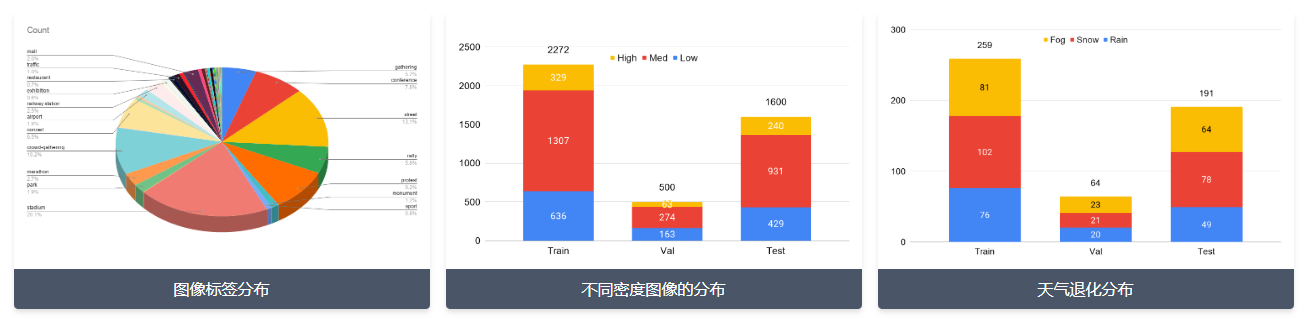
- 包含在多种条件和不同地理位置收集的 4,372 张图像(平均分辨率为 1430x910)
- 特别注意通过纳入恶劣天气和各种照明条件下的图像来提高数据集的多样性:不同的密度、照明变化、雾、雨、雪等恶劣天气条件
- 共包含 151 万个点注释,平均每幅图像 346 个点,最多 25K 个点
- 提供头部级标签(点、近似边界框、模糊级别等)和图像级标签(场景类型和天气状况)


3.3 数据集格式
|---test
| |--gt
| |--xxx.txt
| |--images
| |--xxx.jpg
| |--image_labels.txt
|
|---train
| |--gt
| |--xxx.txt
| |--images
| |--xxx.jpg
| |--image_labels.txt
|---val
| |--gt
| |--xxx.txt
| |--images
| |--xxx.jpg
| |--image_labels.txt
-
train、val 和 test 数据集的样本数量分别为 2272、500 和 1600
-
gt标签注释: "头部级别"
-
"gt" 目录中的每个真实标签文件包含以空格分隔的值,每行表示 x, y, w, h, o, b。
-
x,y 表示头部位置。
-
w,h 表示头部的近似宽度和高度。
-
o 表示遮挡级别,可以取 3 种可能的值:1, 2, 3。
- o=1 表示 "可见"
- o=2 表示 "部分遮挡"
- o=3 表示 "完全遮挡"
-
b 表示模糊程度,可以取 2 种可能的值:0, 1。
- b=0 表示无模糊
- b=1 表示模糊
-
-
真实标签注释: "图像级别"
-
数据集中每个分割包含一个文件 "image_labels.txt"。该文件包含图像级别的标签。
-
文件中的值用逗号分隔,每行表示:
- "filename, total-count, scene-type, weather-condition, distractor"
-
total-count 表示图像中人的总数。
-
scene-type 是描述场景的图像级标签。
-
weather-condition 表示图像中的天气退化,可以取 4 个值:0, 1, 2, 3。
- weather-condition=0 表示 "无天气退化"
- weather-condition=1 表示 "雾/霾"
- weather-condition=2 表示 "雨"
- weather-condition=3 表示 "雪"
-
distractor 表示图像是否为干扰项。可以取 2 个值:0, 1。
- distractor=0 表示 "不是干扰项"
- distractor=1 表示 "干扰项"
-
3.4 查看点标注坐标保存格式
at_path = img_path.replace('images', 'gt').replace('.jpg', '.txt')
points = []
with open(at_path, 'r') as f:
while True:
point = f.readline()
if not point:
break
point = point.split(' ')[:-1]
points.append([float(point[0]), float(point[1])])
points = np.array(points)
获得字典mat中包含的坐标点集合
4. UCF_QNRF数据集介绍
4.1 数据集的来源
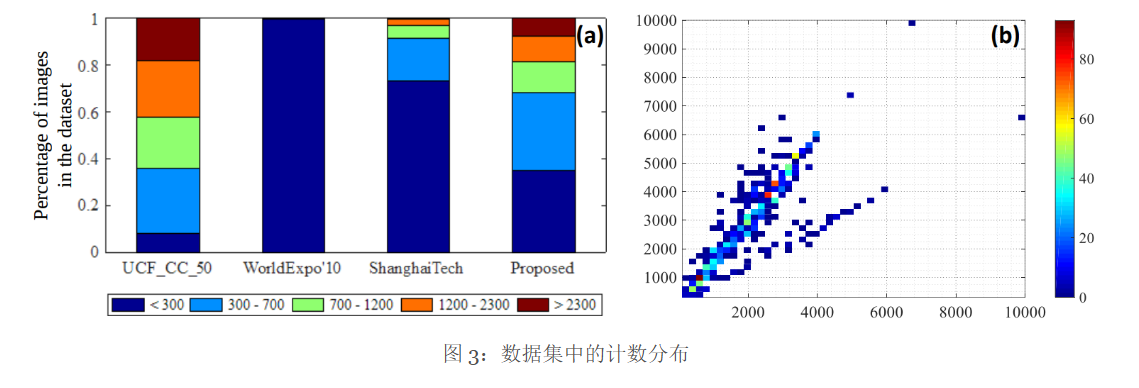
UCF-QNRF 数据集拥有数量最多的高密度人群图像和注释(在当时是这样的,但是更丰富的数据集以及出现了),场景种类更丰富,包含最多样化的视点、密度和光照变化。与 WorldExpo10 和ShangHai Tech,其分辨率更高。平均密度(即所有图像中每像素的人数)也最低,这意味着图像质量更高。较低的每像素密度部分是由于包含背景区域,其中存在许多高密度区域和零密度区域。SHA Tech数据集的 A 部分也包含高密度人群图像,但是这些图像经过了严重裁剪,仅包含人群。另一方面,新的 UCF-QNRF 数据集包含建筑物、植被、天空和道路,因为它们存在于野外捕捉到的真实场景中。这使得该数据集更加真实,同时也更具挑战性。此外,由于数据集来自网络,而不是监控摄像头视频或模拟人群场景,因此它在预测性、图像分辨率、人群密度和人群存在的场景方面都非常多样化,数据集中的图像来自世界各地。
类似地,图 3(a)显示了不同数据集之间计数的多样性。该数据集的分布与 UCF_CC_50 相似,但新数据集的图像数量和注释数量分别是 UCF_CC_50 的 30 倍和 20 倍。此外,如图3(b)所示,其分辨率也高于 WorldExpo10 和ShangHai Tech。我们希望新数据集能够显著提升视觉人群分析领域的研究活跃度,并为构建可部署的、实用的密集人群计数和定位系统铺平道路。
4.2 数据集的分布
|---UCF-QNRF_ECCV18
| |--Test
| |--xxx.mat
| |--xxx.jpg
| |--Train
| |--xxx.jpg
| |--xxx.mat
| |--list.txt(图像路径映射,其实用不到)
| |--readme.txt(不用看)
4.3 查看点标注坐标保存格式
npy_path = r'D:\conda3\Transfer_Learning\CrowdDataset\datasets\QNRF\UCF-QNRF_ECCV18\Train\img_0001_ann.mat'
mat = loadmat(npy_path)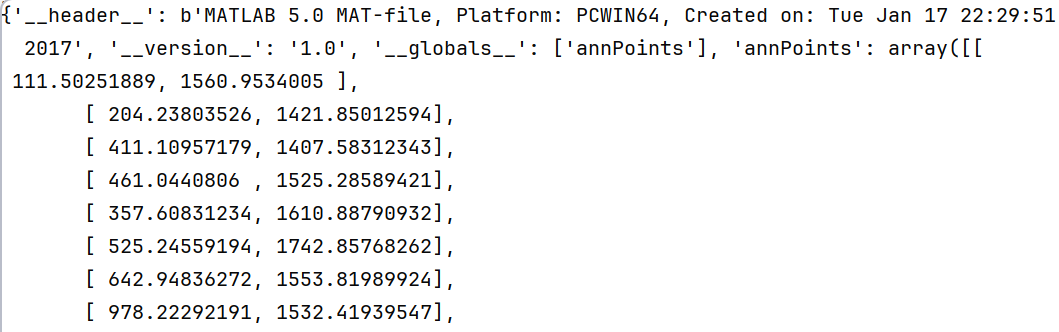
获得字典mat中包含的坐标点集合
points = mat['annPoints'].astype(np.float32)5. ShangHai Tech A & B数据集介绍
5.1 ShanghaiTech Part A
-
数据规模:
-
训练集:300 张图像(共 482 人)
-
测试集:182 张图像(共 2,420 人)
-
-
场景特性:
-
高密度人群(单图最高达 3,139 人)
-
复杂背景干扰(如遮挡、光照变化)
-
5.2 ShanghaiTech Part B
-
数据规模:
-
训练集:400 张图像(共 35,796 人)
-
测试集:316 张图像(共 33,116 人)
-
-
场景特性:
-
低密度人群(单图平均约 100 人)。
-
场景更规则(如街道、建筑走廊)。
-
5.3 Part A 与 Part B 的关键差异
| 特性 | Part A | Part B |
|---|---|---|
| 人群密度 | 极高密度(密集聚集) | 低密度(稀疏分布) |
| 场景复杂度 | 背景杂乱、遮挡严重 | 背景相对简单 |
| 单图人数范围 | 33~3,139 人 | 9~578 人 |
| 适用研究方向 | 高密度计数、遮挡处理 | 跨场景泛化、稀疏计数 |
5.4 文件目录结构
|---ShanghaiTech
| |--part_A
| |--test_data
| |--ground_truth
| |--xxx.mat
| |--images
| |--xxx.jpg
| |--train_data
| |--ground_truth
| |--xxx.mat
| |--images
| |--xxx.jpg
| |--part_B
| |--test_data
| |--ground_truth
| |--xxx.mat
| |--images
| |--xxx.jpg
| |--train_data
| |--ground_truth
| |--xxx.mat
| |--images
| |--xxx.jpg
5.5 查看点标注坐标保存格式
npy_path = r'D:\conda3\Transfer_Learning\CrowdDataset\datasets\shanghai\ShanghaiTech\part_A\test_data\ground_truth\GT_IMG_6.mat'
mat = loadmat(npy_path)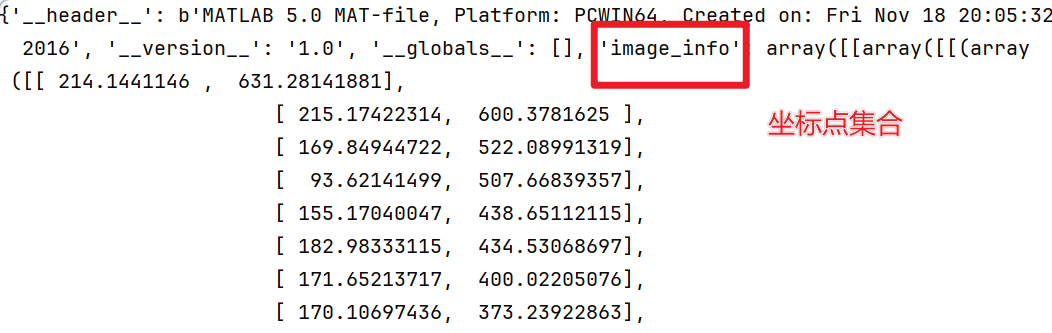
获得字典mat中包含的坐标点集合
points = mat['image_info'][0][0][0][0][0].astype(np.float32)6.密度图的生成
6.1 最初密度图生成方法
Single-Image Crowd Counting via Multi-Column Convolutional Neural Network
论文对该方法的原述:如果在像素 xi处有一个头部,可以用一个狄拉克函数 δ(x−xi)来表示它。因此,带有 N 个头部标签的图像可以表示为一个函数
为了将其转换为连续的密度函数,用高斯核 Gσ对这个函数进行卷积,从而得到密度
F(x)=H(x)∗Gσ(x)。
然而,这种密度函数假设这些 xi是独立的样本,这在这里并不成立:实际上,每个 xi是在3D场景中地面上的人群密度的一个样本,由于透视失真,不同样本 xi关联的像素对应于场景中不同大小的区域。因此,为了准确估计人群密度 F,需要考虑由于地面平面与图像平面之间的几何关系引起的失真。对于当前的任务(和数据集),通常并不知道场景的几何形状。如果假设每个头部周围的人群是相对均匀分布的,那么头部与其最近的 k 个邻居之间的平均距离可以提供对几何失真的合理估计。
论文提到的改进方法:
在实践中,由于遮挡,准确获取头部的大小几乎是不可能的,同时也很难找到头部大小与密度图之间的基本关系。有趣的是,通常头部大小与拥挤场景中相邻两个人的中心之间的距离有关。作为一种折中,对于这些拥挤场景的密度图,根据每个人与其邻居的平均距离,自适应地确定扩散参数。
对于给定图像中每个点 xi,将其与 k 个最近邻的距离表示为 。因此,平均距离为
因此,与 xi 相关的像素大致对应于场景地面上一个半径与 成正比的区域。因此,为了估计与像素 xi 相关的人群密度,需要将 δ(x−xi) 与一个方差为 σi 与
成正比的高斯核进行卷积。更准确地说.
其中 对于某个参数 β。换句话说,我们将标签 H 与适应于每个数据点周围局部几何结构的密度核进行卷积,称为几何自适应核。
6.2 方式一:自适应的方式生成密度图
这部分的讲解建议看视频:
def generate_k_nearest_kernel_densitymap(image,points):
image_h = image.shape[0]
image_w = image.shape[1]
# coordinate of heads in the image
points_coordinate = points
points_quantity = len(points_coordinate)
densitymap = np.zeros((image_h, image_w))
if points_quantity == 0:
return densitymap
else:
pts = np.array(list(zip(np.nonzero(points_coordinate)[1],
np.nonzero(points_coordinate)[0]))) # np.nonzero函数是numpy中用于得到数组array中非零元素的位置(数组索引)
#TODO 使用NearestNeighbors算法找到每个点的4个最近邻点,计算每个点到其最近4个邻居的距离
# https://blog.youkuaiyun.com/weixin_37804469/article/details/106911125
neighbors = NearestNeighbors(n_neighbors=4, algorithm='kd_tree',
leaf_size=1200)
"""
对于每个点:
1.如果点数大于3,使用最近3个邻居距离的平均值乘以0.1作为高斯核的σ值,如果点数小于等于3,使用固定σ值15
2.使用scipy库提供的函数gaussian_filter生成一个点的密度图
3.最后将所有点的高斯滤波结果相加得到最终密度图
"""
neighbors.fit(pts.copy())
# TODO 计算当前的每一个标注位置到最近4个点的距离
distances, _ = neighbors.kneighbors()
for i, pt in enumerate(points_coordinate):
pt2d = np.zeros((image_h,image_w), dtype=np.float32)
if int(pt[1])<image_h and int(pt[0])<image_w:
pt2d[int(pt[1]),int(pt[0])] = 1.
else:
continue
if points_quantity > 3:
sigma = (distances[i][1]+distances[i][2]+distances[i][3])*0.1
else:
sigma = 15
densitymap += scipy.ndimage.filters.gaussian_filter(pt2d, sigma, mode='constant')
return densitymap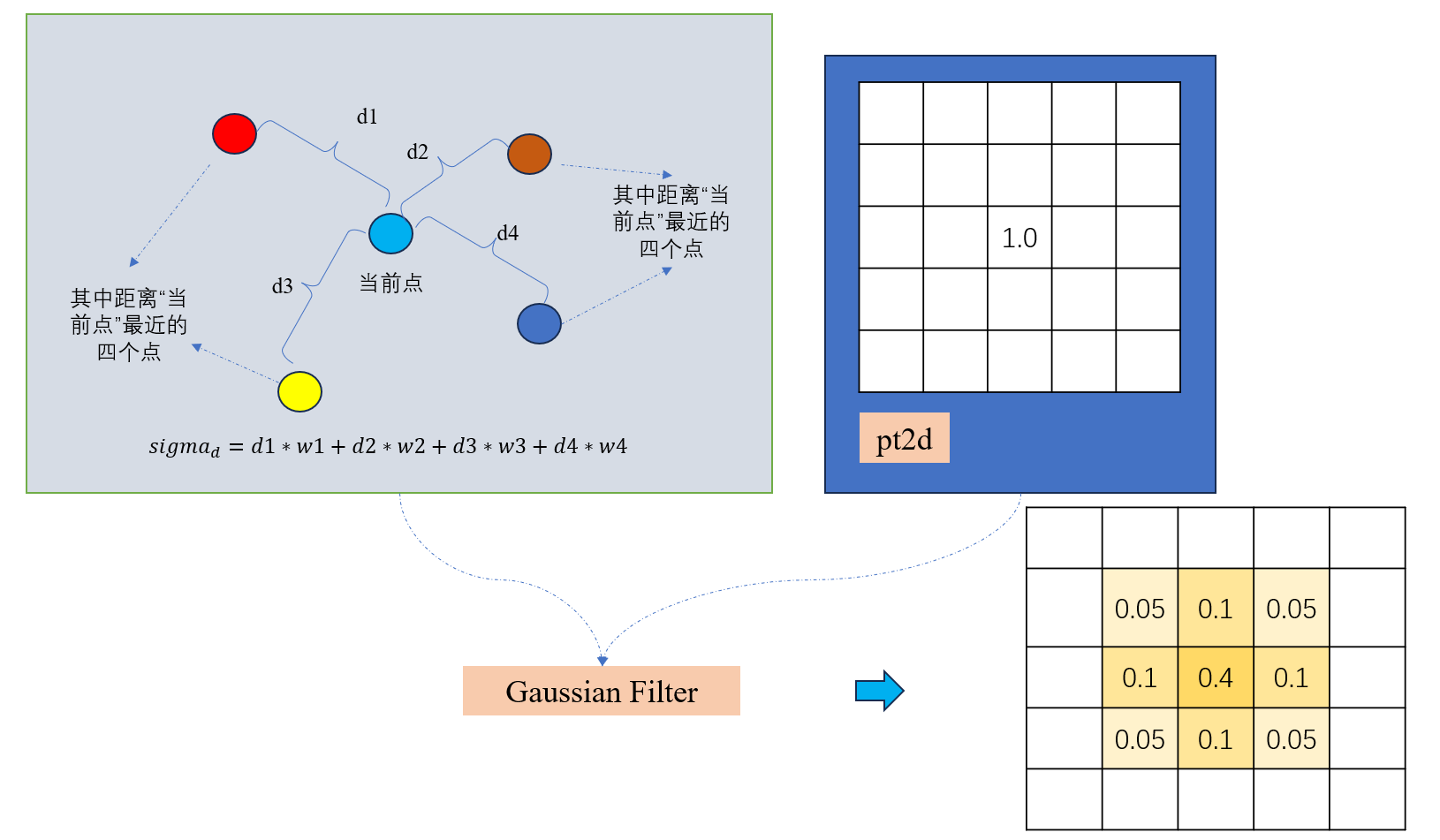
6.2.1. 高斯核(Gaussian Kernel)
高斯滤波的核心是高斯核,它是一个二维的正态分布函数(钟形曲线):
其中:
-
(x,y)是像素位置的偏移量(通常取一个有限窗口,如 [−3σ,3σ])。
-
σ 是标准差,控制模糊程度(σ 越大,图像越模糊),因为σ越大,导致高斯核也越大,最终模糊的区域面积也越大,所以图像也就越模糊。
6.2.2.高斯滤波的实现步骤
-
生成高斯核:
-
根据给定的 σ 计算高斯权重矩阵(核)。
-
核的大小通常取 6σ+1(覆盖 99% 的能量)。
-
-
卷积操作:
-
将高斯核作为滑动窗口,与图像的每个局部区域进行加权求和。
-
对于图像中的每个像素 I(x,y),计算其邻域内像素的加权平均值:
其中 k 是核的半径(如 k=3σ)。
-
-
边界处理:
-
mode='constant':边界外填充固定值(默认是 0)。 -
其他模式如
reflect、nearest等也可用(通过mode参数指定)。
-
6.2.3. 优化实现
SciPy 的高斯滤波通过以下方式优化计算效率:
-
可分离性(Separability):
-
二维高斯核可以拆分为两个一维高斯核的乘积:
G(x,y)=G(x)⋅G(y) -
因此,滤波分两步进行:
-
先沿行(水平方向)做一维卷积。
-
再沿列(垂直方向)做一维卷积。
-
-
复杂度从 O(n2) 降到 O(2n)(n 是核大小)。
-
-
快速傅里叶变换(FFT):
-
对于大核(如 σ>10),SciPy 会自动切换到频域计算(卷积定理)。
-
6.2.4. 关键参数
-
sigma:高斯核的标准差(决定模糊强度)。 -
order:导数阶数(0 表示纯滤波,1/2 可用于边缘检测)。 -
mode:边界填充模式(如constant、reflect)。 -
truncate:核的截断范围(默认 4.0,即核大小为 4σ4σ)。
6.2.5. 数学意义
高斯滤波的本质是低通滤波,能抑制高频噪声(如小尺度细节),保留低频信息(如大尺度结构)。在密度图生成中,它模拟了人头的“扩散效应”,使得离散点标注变为连续分布。
6.3 方式二:固定的sigma生成密度图
from scipy.ndimage.filters import gaussian_filter函数def gaussian_filter_density_fixed(img, points):
img_shape=[img.shape[0],img.shape[1]]
density = np.zeros(img_shape, dtype=np.float32)
gt_count = len(points)
if gt_count == 0:
return density
for i, pt in enumerate(points):
pt2d = np.zeros(img_shape, dtype=np.float32)
if int(pt[1])<img_shape[0] and int(pt[0])<img_shape[1]:
pt2d[int(pt[1]),int(pt[0])] = 1.
else:
continue
# sigma = 4 #np.average(np.array(gt.shape))/2./2. #case: 1 point
# density += gaussian_filter(pt2d, sigma, truncate=7/sigma, mode='constant')
sigma = 2
density += gaussian_filter(pt2d, sigma, mode='constant')
return density6.4 读取生成的密度图(.npy)
npy_path = r'D:\conda3\Transfer_Learning\CrowdDataset\datasets\shanghai\ShanghaiTech\part_A\test_data\npys\IMG_6.npy'
den_map = np.load(npy_path)
den = den_map.astype(np.float32, copy=False)
den = Image.fromarray(den)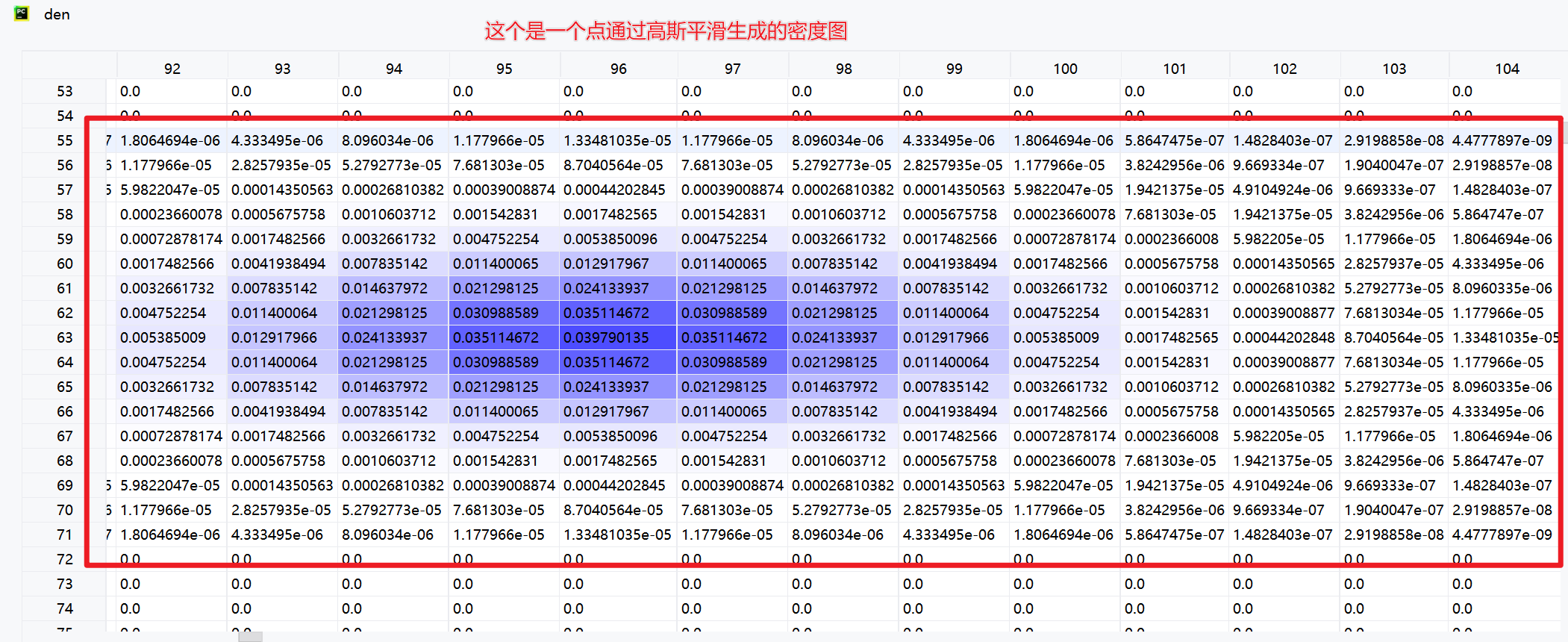
6.5 不同sigma生成的密度图对比
"""
@Author : Keep_Trying_Go
@Major : Computer Science and Technology
@Hobby : Computer Vision
@Time : 2025/4/3-14:45
@优快云 : https://blog.youkuaiyun.com/Keep_Trying_Go?spm=1010.2135.3001.5421
"""
import os
import cv2
import argparse
import numpy as np
from PIL import Image
from time import time
import matplotlib.pyplot as plt
from matplotlib import cm as CM
def vis_Gt():
npy_root = r'/home/ff/myProject/KGT/myProjects/myDataset/jhu_crowd_v2.0/DCCUS_SR/test_data/npys'
save_dir = r'/home/ff/myProject/KGT/myProjects/myProjects/DCCUS/LLB_Count/vis_gts/sd'
for npyName in os.listdir(npy_root):
gt_path = os.path.join(npy_root, npyName)
gt_dmap = np.load(gt_path)
gt_count = np.sum(gt_dmap)
plt.figure()
plt.axis('off')
plt.text(
x=0.95,
y=0.06,
s=f"{str(round(gt_count, 1))}",
color='white',
transform=plt.gca().transAxes,
fontsize=32,
ha='right', # 关键:右对齐
va='bottom', # 关键:底部对齐
weight='bold')
plt.imshow(gt_dmap, cmap=CM.jet)
plt.savefig(os.path.join(save_dir, npyName.replace('npy','png')))
plt.close()
print(f'gt {npyName} is finished!')
if __name__ == '__main__':
vis_Gt()
pass
6.5.1 sigma = 2.0
6.5.2 sigma = 4.0
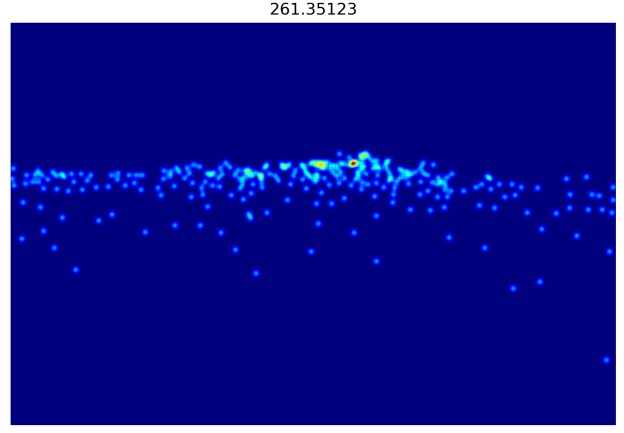
6.5.3 sigma = 8.0

总结:可以发现随着sigma的变大,生成的密度图也变得更加模糊了,因此,在实际使用中应该自己的需求选择sigma的大小,从而更好的让模型学习。
- Wang, Q., Gao, J., Lin, W., Li, X.: Nwpu-crowd: A large-scale benchmark for crowd counting and localization. TPAMI (2020).
-
Sindagi, V.A., Yasarla, R., Patel, V.M.: Pushing the frontiers of unconstrained crowd counting: New dataset and benchmark method. In: ICCV (2019).
-
Idrees, H., Tayyab, M., Athrey, K., Zhang, D., Al-Maadeed, S., Rajpoot, N., Shah, M.: Composition loss for counting, density map estimation and localization in dense crowds. In: ECCV (2018).
-
Zhang, Y., Zhou, D., Chen, S., Gao, S., Ma, Y., 2016. Single-image crowd counting via multi-column convolutional neural network, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 589–597.
-
N. R. Draper and H. Smith, Applied regression analysis. John Wiley & Sons, 1998, vol. 326.
悄悄举手:若觉得文章有用,不妨留下一个小赞?(´▽`ʃƪ)



















 31万+
31万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









