




目录
本文主要是基于QT中OpenCV的使用以及深度学习中图像分类来实现的,建议读者先看之前QT 6.6.0中OpenCV的环境的配置(QT 6.6.0中OpenCV两种环境的配置方法以及基本使用例子)和图像分类算法实现(PyTorch实现一个简单的图像分类(代码详细))。
思路:
- 图像分类模型训练得到权重文件.pth;
PyTorch 训练之后的网络模型.pth转.onnx文件并对图像进行预测
- QT中使用OpenCV加载ONNX权重文件实现图像分类;

- 通过QT界面来更加方便和直接对图像进行预测。

注:.pth和ONNX模型文件在GitHub源码中
| 加载函数 | 含义 |
|---|---|
| cv::dnn::readNet | 用于从文件中加载网络模型。它可以自动识别模型的框架(如Caffe, TensorFlow, Torch, Darknet等),前提是文件扩展名和/或内容符合特定框架的标准。它允许通过文件名直接加载模型,无需指定框架类型。 |
| cv::dnn::readNetFromCaffe | 专门用于从Caffe框架的.prototxt(网络结构描述文件)和.caffemodel(权重文件)中加载模型。 |
| cv::dnn::readNetFromDarknet | 用于从Darknet框架的.cfg(配置文件)和.weights(权重文件)中加载模型。 |
| cv::dnn::readNetFromModelOptimizer | 用于加载通过Intel的Model Optimizer工具优化后的模型。这些模型通常以.xml(网络结构)和.bin(权重)文件的形式存在。 |
| cv::dnn::readNetFromONNX | 用于加载ONNX(Open Neural Network Exchange)格式的模型。ONNX是一种开放格式,用于表示深度学习模型,支持多种框架。 |
| cv::dnn::readNetFromTensorflow | 专门用于加载TensorFlow框架的模型。它可以处理.pb(Protobuf格式)和.pbtxt(Protobuf文本格式)文件。 |
| cv::dnn::readNetFromTorch | 用于加载Torch(框架的模型。它支持.t7(Torch 7的模型文件)格式。 |
| cv::dnn::readTensorFromONNX 和 cv::dnn::readTorchBlob | 从.pb文件创建blob。参数为带输入张量的.pb文件的路径。 |
注意:由于本文图像分类算法采用PyTorch框架实现的,因此只用到cv::dnn::readNetFromONNX加载网络模型。
重点函数详解
归一化方式一:

归一化方式二:
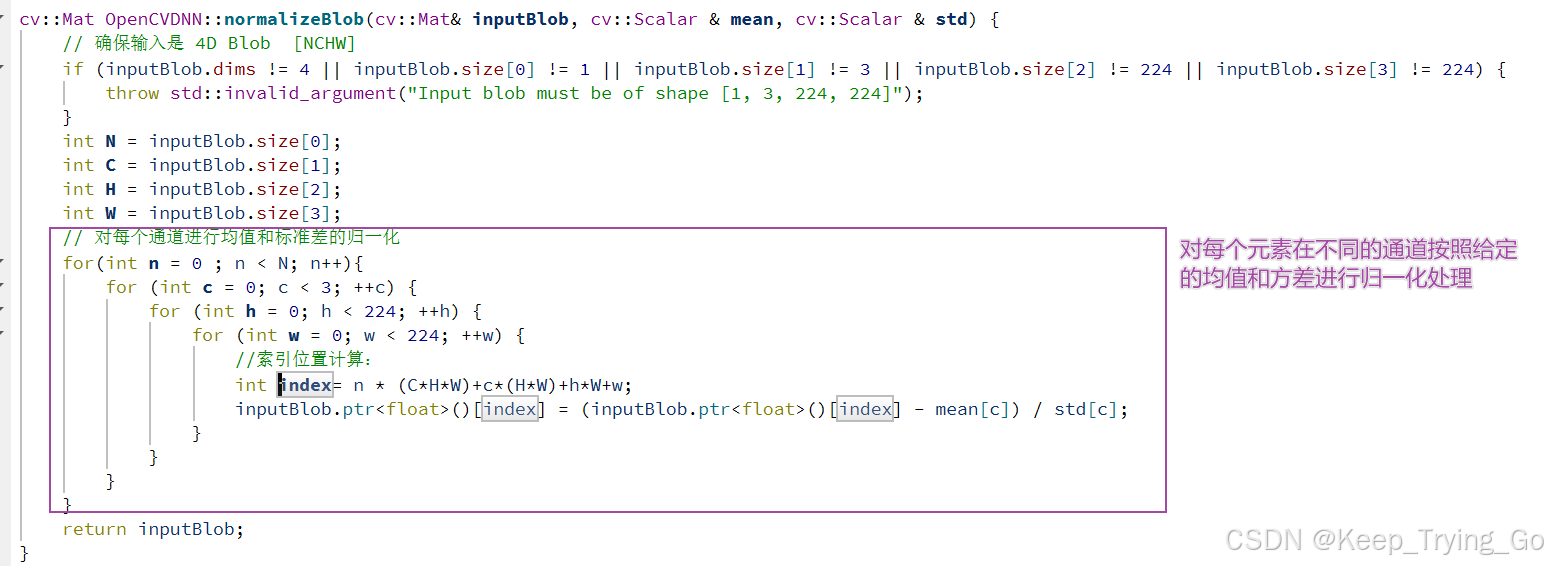
blobFromImage(InputArray image, OutputArray blob,
double scalefactor=1.0,const Size& size = Size(),
const Scalar& mean = Scalar(),bool swapRB=false,
bool crop=false, int ddepth=CV_32F);
参数含义
image: 输入图像(cv::Mat),可以是1、3或4通道的图像。
scalefactor:图像各通道数值的缩放比例。通常用于数据归一化。如果要将像素值从[0, 255]缩放到[0, 1],
则scalefactor应设置为1.0/255.0。
size: 输出图像的空间大小,格式为(width, height)。这个参数指定了返回的blob中数据的尺寸,即
神经网络输入层的尺寸。
mean: 用于各通道减去的值,以降低光照等因素的影响。这个参数是一个包含三个元素的向量(对于BGR
图像),分别对应B、G、R三个通道需要减去的均值。
swapRB: 是否交换R和B通道。由于OpenCV默认使用BGR格式,PyTorch搭建的神经网络框架使用RGB格式,
因此这个参数用于在必要时进行通道交换。
crop: 是否进行图像裁剪。当此参数为true时,函数会先按比例缩放图像,然后从中心裁剪成size指定
的尺寸。
ddepth: 输出的图像深度。这个参数指定了blob的数据类型,通常选择CV_32F(32位浮点数),因为DNN
中很多参数都是浮点数。
注:
缩放:scaled_image = image × scalefactor
均值减法:normalized_image = scaled_image − mean
注:关于model.forward("predictions")这个最后输出层的名称,要和转化为ONNX时指定的输出层名称相对应[PyTorch 训练之后的网络模型.pth转.onnx文件并对图像进行预测]。

void minMaxLoc(InputArray src, CV_OUT double* minVal,
CV_OUT double* maxVal = 0, CV_OUT Point* minLoc = 0,
CV_OUT Point* maxLoc = 0, InputArray mask = noArray());
src: 输入的单通道数值数组。
minVal: 指向找到的最小值的指针。如果不需要,则为 NULL。
maxVal: 指向找到的最大值的指针。如果不需要,则为 NULL。
minLoc: 指向找到的最小值位置的指针(以图像坐标表示)。如果不需要,则为 NULL。
maxLoc: 指向找到的最大值位置的指针(以图像坐标表示)。如果不需要,则为 NULL。
mask: 可选的操作掩码,用于指定哪些元素需要考虑在内。它必须是单通道数组,
与输入数组具有相同的尺 寸。非零元素表示相应的元素在 src 中被考虑。
注:对于本文最终输出的结果维度为[1,5],是一个二维矩阵的形式,那么得到最大值位置的指针之后,
怎么才能得到对应的索引呢?由于maxLoc为Point类型,包含[x,y],x对应横轴,y对应纵轴;二维
矩阵的行对应坐标的y轴,列对应坐标的x轴;而输出的[1,5]对应5个类别,因此只需要得到maxLoc的
x坐标位置即可得到对应最大预测概率索引类别.QT 基于OpenCV加载ONNX模型文件实现图像分类


















 2710
2710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









