




 自编码器是一种无监督学习方法,通过编码器和解码器学习数据的低维表示。它适用于数据降维、异常检测和图像处理任务,如图像降噪和神经风格迁移。自编码器的优化目标是使解码后的输出尽可能接近原始输入。在实现上,可以使用Pytorch等框架构建网络结构并编写代码。
自编码器是一种无监督学习方法,通过编码器和解码器学习数据的低维表示。它适用于数据降维、异常检测和图像处理任务,如图像降噪和神经风格迁移。自编码器的优化目标是使解码后的输出尽可能接近原始输入。在实现上,可以使用Pytorch等框架构建网络结构并编写代码。
目录
1.自编码器产生背景
像我们目前所进行的图像分类,目标识别,图像分割等都是基于有监督学习来的,所以对于海量的数据需要进行人工的标注。但是随着时代的发展和人工智能不断的火起来,对于数据量的需求已经不是想象中的样子了,数据量的需求已经远远超出人们的认知。面对海量的数据集,有没有一种办法就是能够从中学习到数据的分布P(x)的算法呢?
提示:而解决上面的算法计算无监督学习。
- 自编码器
- 自编码器原理
- 自编码器应用场景
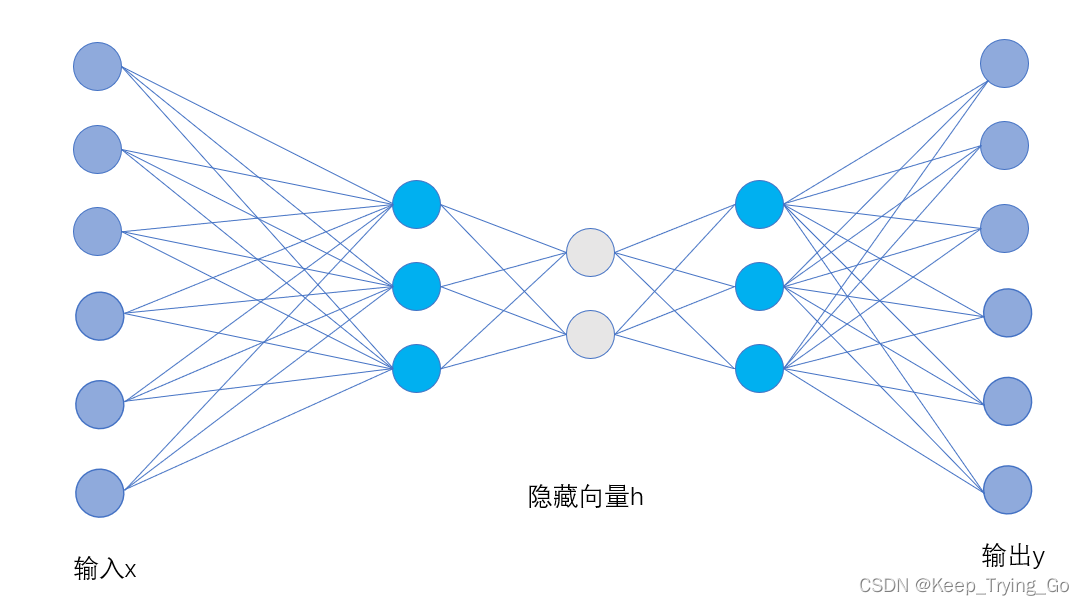
2.自编码器原理
(1)一般的神经网络结构
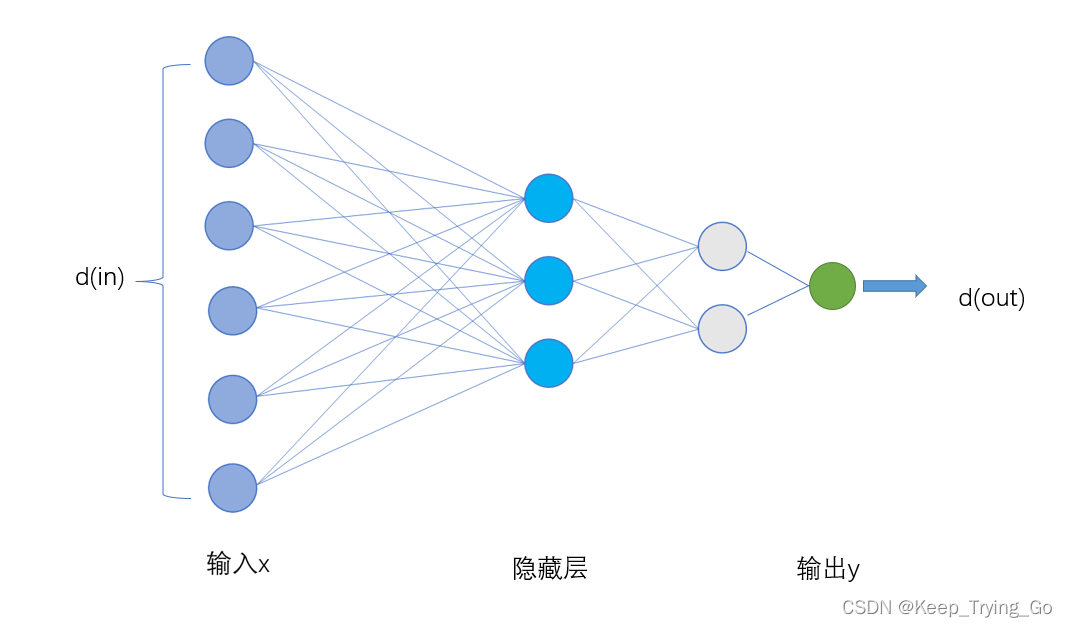

能否利用神经网络的强大非线性表达能力去学习到低维的数据表示呢?但是这样也会引入一个问题就是,训练神经网络都是在有标签的清况下,对于一个无监督的学习,是没有标签的,只有输入的数据本身x.
(2)自编码器
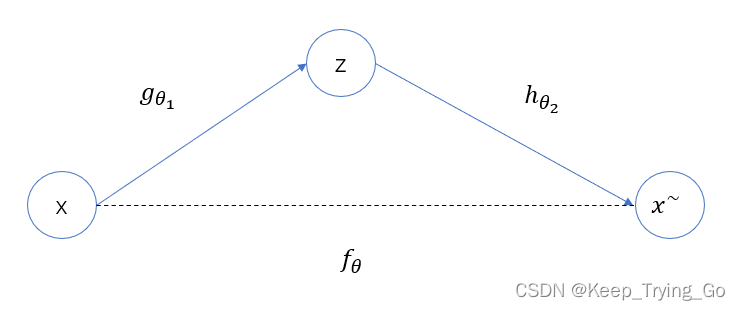

我们希望从编码器到解码器的最后输出近似等于原来的输入,所以自编码器的优化目标如下:

3.自编码器的实现
(1)网络结构
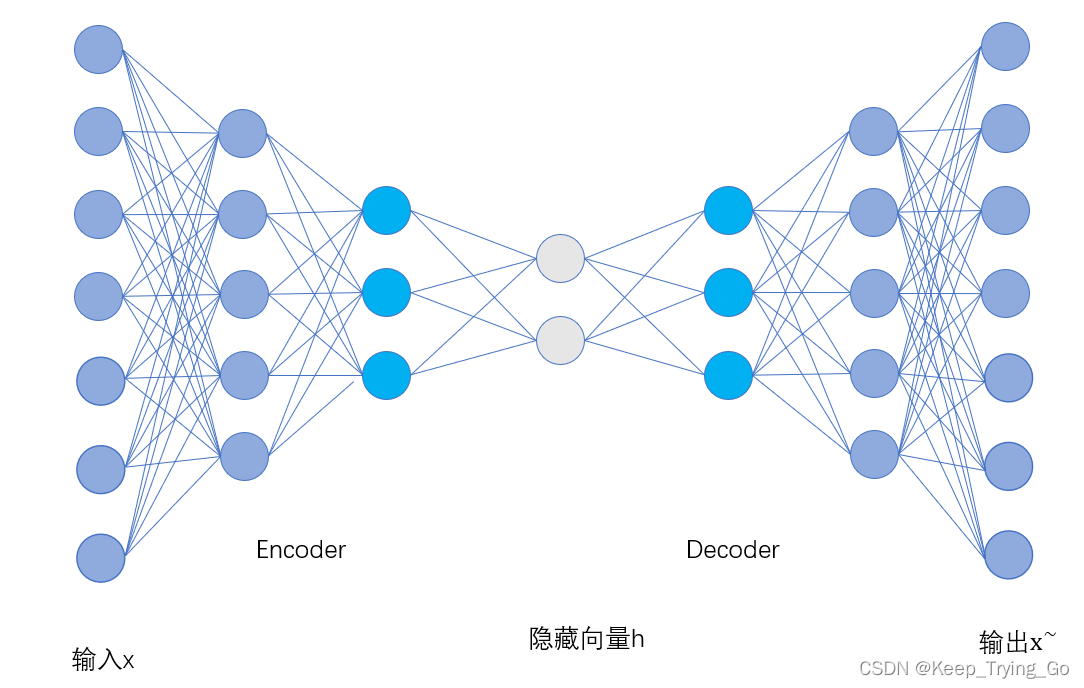

(2)代码实现
本文的代码下载:GitHub - KeepTryingTo/Pytorch-GAN: 使用Pytorch实现GAN 的过程
参考书籍和链接
《TensorFlow深度学习》


















 8496
8496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









