



 本文深入解析Java集合框架,包括List、Set、Map等接口及其实现类的特点与区别,探讨ArrayList、LinkedList、Vector的性能差异,以及HashMap、Hashtable、TreeMap在不同场景下的应用。
本文深入解析Java集合框架,包括List、Set、Map等接口及其实现类的特点与区别,探讨ArrayList、LinkedList、Vector的性能差异,以及HashMap、Hashtable、TreeMap在不同场景下的应用。
集合是指具有某种特定性质的具体的或抽象的对象汇总而成的集体。其中,构成集合的这些对象则称为该集合的元素
百度百科 - 尼古拉斯·赵四
集合的定义如是,但是在Java里面,我们初识集合,可能还是数组,
String[] str = new String[4];
比如上面,我们就定义了一个长度为4的字符串数组,在这个数组里,我们只能放String类型的变量
str[0] = "赵子龙"
其实这段代码,我们可以理解为
String str2 = "赵子龙";
str[0] = str2;
这样是不是一目了然呢?
这时候,我们其实可以给【数组】下一个定义,
JAVA数组,就是把同一类型的变量按顺序汇总起来。
我们来分析一下【数组】的特点:有序,长度固定,元素类型单一,放入和取出只能按顺序。
而在实际应用中,我们可能在初始是不知道长度的,类型也不可能是单一的字符串类型,还可能会有其它诸如:Long,char,double等类型,也有可能是一个对象,这时候,集合类出现了。
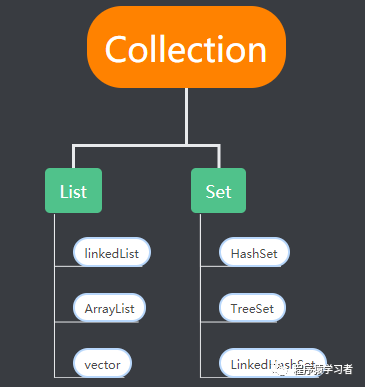
Collection是一个基本的集合接口,下面又分为两个分支接口:List,Set
List和Set是我们工作学习中常用的接口,我们看下他们中常用的的方法定义有什么差异。来,我们进他们的源码:
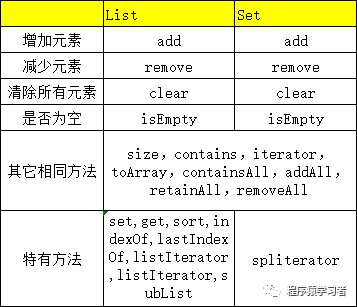
从源码看,貌似Set和List是一样的,都提供了相同的添加,减少,清除元素的方法,而我们在看List的特有方法:【sort】,源码中的注释
Sorts this list according to the order induced by the specified
这句话的意思就是:将此列表按指定的顺序排序
所以,我们可以看到List集合是一个有序的集合,Set是无序的
我们接着看Set的方法:spliterator
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}
我们在来看一下【DISTINCT】的注释
* Characteristic value signifying that, for each pair of * encountered elements {@code x, y}, {@code !x.equals(y)}. This * applies for example, to a Spliterator based on a {@link Set}.
这句话直译就是:特性值这标志着,对于每对遇到的元件x, y , !x.equals(y) 。 这适用于例如基于Set的Spliterator 。
说通俗点,这个方法就是去除重复值。
由此,我们得出了List和Set的差别:
List是有序的,可重复的
Set是无序的,不可重复的
最后,让我们用一段代码来看一下他们的区别
List list = new ArrayList<>();
list.add("1");
list.add("2");
list.add(2);
list.add(2);
list.add(3);
list.add(4.00);
System.out.println(list.toString());
//结果
[1, 2, 2, 2, 3, 4.0]
Set set = new HashSet();
set.add("1");
set.add("2");
set.add(2);
set.add(2);
set.add(3);
set.add(4.00);
System.out.println(set.toString());
//结果
[4.0, 1, 2, 2, 3]
貌似结果就显而易见了。


ArrayList、Vector和LinkedList
作为List接口的实现类,他们有什么区别呢?
ArrayList和Vector都继承了同一个类:AbstractList
LinkedList继承了:AbstractSequentialList
看文知意,ArrayList就是一个 Array-List 数组列表,我们可以理解为他是一个数组样式的列表,可以提供下标取值,而且数组的特点就是连续的,空间是有范围值的,而且是要对整个数组的size进行控制,以防止在长度不够的时候进行扩容,ArrayList设计的默认扩充长度是:size*1.5+1(如果你想改变它的扩容策略,可以重写它的方法:ensureCapacity)。你看,凡事都是有两面性,一个事物规则整洁的展现在你面前,在整理的时候肯定是要耗费时间的。
LinkedList拆解开来,就是 Linked -List 链式列表。
链表,是常见的数据结构的一种,在这,只说一下他的基本概念。
如果一个节点包含指向另一个节点的数据值,那么多个节点可以连接成一串,只通过一个变量访问整个节点序列,这样的节点序列称为链表
单向链表: 如果每个节点仅包含其指向后继节点的引用,这样的链表称为——单向链表
双向链表: 每个链表节点,包含两个引用,一个指向前驱节点,一个指向后驱节点,也就是——双向链表。
当我们把一个元素放到一个集合里,而不需要任何操作和行为的时候,可以想象速度会是很快的,但是,当你取值的时候,你会发现从一个无须不规则随机查询的集合里找到一个你心仪的元素是多么困难。
Vector和ArrayList继承的是同一个抽象类,同样,也是一个数组的形式存储数据的集合。但是我们看下官方给出的注释:
* Java Collections Framework</a>. Unlike the new collection * implementations, {@code Vector} is synchronized. If a thread-safe * implementation is not needed, it is recommended to use {@link * ArrayList} in place of {@code Vector}.
这段话的意思大致就是,vector是线程安全的,如果你不需要,你可以选择使用ArrayList。我们赶紧去它的方法里看一下,会发现他很多方法用了synchronized这个关键字,如果单个以vector来讲,他确实是安全的,但是如果你多个vector呢?你是不是要以vector对象为锁?那和ArrayList有啥区别?所以就日常学习生活工作来说,不是十分推荐使用这个类。
最后,我们做一个小总结:
ArrayList:新增慢,查询快
LinkedList:新增快,查询慢
vector: 线程安全
Map集合:
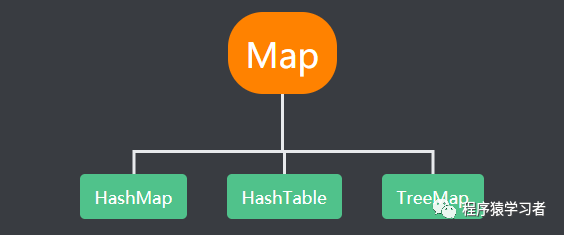
map集合,其实在于我看来,就是一个特殊的集合,与其说它是一个集合,更不如说它是一个灵活的对象。若是谈论到它和List、Set集合的区别,往深里深究,或者说往使用层面上讲的话,这两者就是两个相辅相成的对象,谁都离不开谁,而又没有可比性。
实践出真知,我们通过一段属性定义来看一下。
首先,我们先定义一个Map集合对象,看看他是什么?
//以实现类HashMap为例子
Map map = new HashMap();
map.put("id", 1);
map.put("id", "2");
map.put("name", "小风");
map.put("sex", "男");
System.out.println(map.toString());
//输出j结果
{sex=男, name=小风, id=2}
初步下一个定义:map是一个需要赋值键、值的集合,而且键不可以重复,否则会被重复,而且是无序的(至少目前结果来看是这样)
你看到这有没有很熟悉?有没有动一下你的小脑袋?你是否感觉到Map更像什么?没错,它就是像一个没有标明字段,也可以给某个字段任意赋值的class类。以一个学生为模板,我们创建同样的三个属性:姓名,年龄,拥有的手机品牌。
Map实现方式:
//以实现类HashMap为例子
List<Map> listMap = new ArrayList<Map>();
Map map = new HashMap();
//小风同学 23岁 拥有的手机品牌 :摩托罗拉,HTC,小米
map.put("name", "小风");
map.put("age", 23);
map.put("mobileType", "摩托罗拉、HTC、小米");
listMap.add(map);
//小鱼同学 26岁 拥有的手机品牌:苹果、华为
Map map2 = new HashMap();
map2.put("name", "小鱼");
map2.put("age", 26);
List<String> listMobileType = new ArrayList<String>();
listMobileType.add("苹果");
listMobileType.add("华为");
map2.put("mobileType", listMobileType);
listMap.add(map2);
System.out.println(listMap.toString());
输出结果:
[{name=小风, mobileType=摩托罗拉、HTC、小米, age=23}, {name=小鱼, mobileType=[苹果, 华为], age=26}]
然后,让我们看下正常的创建类实现:
public class Student {
//姓名
private String name;
//年龄
private String age;
//拥有的手机类型
private List<String> mobileType;
}
List<Student> listMap = new ArrayList<Student>();
//小风同学 23岁 拥有的手机品牌 :摩托罗拉,HTC,小米
Student student = new Student();
student.setName("小风");
student.setAge("23");
List<String> listMobileType = new ArrayList<String>();
listMobileType.add("摩托罗拉");
listMobileType.add("HTC");
listMobileType.add("小米");
student.setMobileType(listMobileType);
listMap.add(student);
//小鱼同学 26岁 拥有的手机品牌:苹果、华为
Student student2 = new Student();
student2.setName("小鱼");
student2.setAge("26");
Map map2 = new HashMap();
List<String> listMobileType2 = new ArrayList<String>();
listMobileType2.add("苹果");
listMobileType2.add("华为");
student2.setMobileType(listMobileType2);
listMap.add(student2);
System.out.println(listMap.toString());
输出结果
[[name=小风, age=23, mobileType=[摩托罗拉, HTC, 小米]], [name=小鱼, age=26, mobileType=[苹果, 华为]]]
你仔细对比一下,是不是Map可以当一个超级无敌灵活的Java类。


所以你知道这个东西大概是干啥的了吧?
不过在真正的工作中慎用,因为这个定义字段不明确,会为你开发的代码带来非常不好的可读性,维护你代码的人肯定也会问候一下你,会不会涉及你的家人也就看他的心情了


Hashtable,HashMap,TreeMap的区别
Hashtable 和HashMap都是基于hash表实现的,他们行为上基本一致。
TreeMap 是基于红黑色实现的.通过compator来指定顺序,或自然顺序
什么是哈希表?什么是红黑树?一句两句我感觉说不清,所以我不说了,建议你们去百度


所以呢?接下来我们比较一下Hashtable 和HashMap
Hashtable的多数方法是带有synchronized关键字的,是线程安全的,这一点可以参考一下vector和ArrayList
HashTable不允许null值,key和value都不可以,HashMap允许null值,key和value都可以。(HashMap允许 key值只能有一个null值,因为hashmap如果key值相同,新的key, value将替代旧的。)
迭代方法:Hashtable - Enumeration ;HashMap - Iterator
HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数
哈希值的使用不同,HashTable直接使用对象的hashCode。
从表面来看,貌似概括一句话,就是一个是线程安全的,一个是线程不安全。我真机智(其实这句话太扯淡,太草率了,大家略过就好了,嘿嘿)
TreeMap
TreeMap的存储结构是平衡二叉树,也成为红黑树。上面说,让大家自行百度,嘿嘿,我借用别人的一副图,给大家直截了当的展示一下。
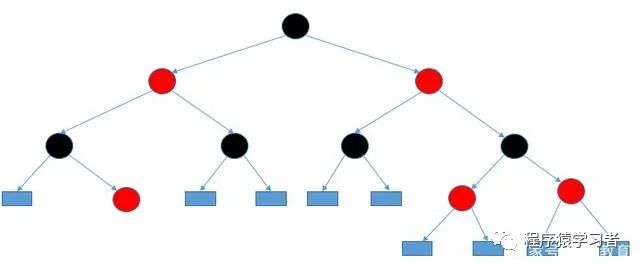
首先,它是一个二叉树,也具有二叉树的特点:任何节点的值大于它的左子节点,小于它的右子节点。如果只有一边,比如只有左子节点,或者右子节点,势必就会导致效率大大降低,所以,就有了平衡二叉树。
我们以一段简单的代码来看下这是个啥?
Map<String, String> map = new TreeMap<>();
map.put("ddd", "444");
map.put("ccc", "333");
map.put("bbb", "222");
map.put("aaa", "111");
System.out.println(map.toString());
输出代码
{aaa=111, bbb=222, ccc=333, ddd=444}
貌似这个玩意自己排序了一下。
为什么呢?那是因为TreeMap类中的Comparator这个方法
private final Comparator<? super K> comparator;
来,我们看一下这个代码的注释:
* The comparator used to maintain order in this tree map, or * null if it uses the natural ordering of its keys.
翻译过来就是:用于在此树映射中维护顺序的比较器,如果它使用键的自然顺序,则为空。



真刺激,它又自动排序了。你想起了啥?所以懂了?
小结一下:TreeMap继承了Map的性质,同时其树结构又可以进行元素排序,用处很大。所以如果你不用元素排序的时候,最好不要用这个,推荐用HahsMap哦


最后留一个小知识:
ArrayList的默认初始容量是多少呢?(默认容量不等于默认长度,慎重!!!)
/**
** Default initial capacity. 默认初始容量为10
*/
private static final int DEFAULT_CAPACITY = 10;
最最后,求大家关注一波,哈哈哈哈





















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











