



 论文GRAF提出了一种新的生成模型,用于3D感知图像合成,解决了2D GANs在3D图像合成上的局限。通过引入条件的Neural Radiance Fields(NeRF)表示, GRAF可以从2D图像中学习丰富的生成模型,支持视角变换和形状/外观修改。关键创新是多尺度patch-based判别器,允许高效学习高分辨率的生成性NeRF。实验显示,与基于体素的方法相比,GRAF在多视图一致性、高分辨率输出和形状/外观解耦方面表现出优越性能。
论文GRAF提出了一种新的生成模型,用于3D感知图像合成,解决了2D GANs在3D图像合成上的局限。通过引入条件的Neural Radiance Fields(NeRF)表示, GRAF可以从2D图像中学习丰富的生成模型,支持视角变换和形状/外观修改。关键创新是多尺度patch-based判别器,允许高效学习高分辨率的生成性NeRF。实验显示,与基于体素的方法相比,GRAF在多视图一致性、高分辨率输出和形状/外观解耦方面表现出优越性能。
论文:http://arxiv.org/abs/2007.02442
code:https://github.com/autonomousvision/graf
摘要
2D生成对抗网络可以实现高分辨率图像合成,但不能很好地应用在3D图像合成。为解决这个问题,出现了基于中间体素的表示与可区分渲染相结合的几种方法,但这些方法存在几个问题:1)合成的图像分辨率低;2)在分离相机和场景属性方面存在不足。
本文提出了一个辐射场的生成模型,该模型已被证明在单一场景的新型视图合成中是成功的。与基于体素的表征相比,辐射场并不局限于三维空间的粗略离散,而是允许分解相机和场景属性,同时在重建模糊性的情况下优雅地退化。通过引入一个基于多尺度patch-based的判别器,仅通过未处理的二维图像训练本文中的模型,也能实现高分辨率图像的合成。
1 Introduction
尽管convolutional GANs 可以实现从无序的图像集合中合成高分辨率图像,但最先进的模型仍难以正确地分解包括三维形状和视点在内的基本生成因素。相比之下,人类具有推理世界的三维结构和从新的视角想象物体的能力。
由于三维推理是机器人、虚拟现实或数据增强应用的基础,便出现了考虑三维感知图像合成的任务,目的是通过明确控制摄像机的姿势来生成逼真的图像。与2D GANs相比,用于三维感知图像合成的方法学习一个三维场景表示,该表示使用可区分的渲染技术明确地映射到图像上,因此提供对场景内容和视角的控制。
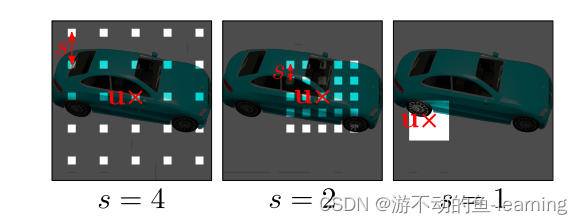
但三维监督或摆放的图像在实践中往往很难获得,于是考虑只用二维监督来解决这一任务,现有的方法使用离散的三维表示,如代表完整的3D物体的 voxel-grid 或者intermediate 3D features来实现这一目标,如下图1所示:

"图 1 Motivation"
虽然在色彩空间中对三维物体进行建模可以利用微分渲染,但基于体素的表示法的cubic memory growth的限制使得只能合成低分辨率图像,并导致了可见的伪影。intermediate 3D features更加紧凑,并且有更好的图像分辨率。但这需要学习3D到2D的映射,用于将抽象特征解码为RGB值,这会导致高分辨率下视图之间不一致。
1.1 本文的贡献
- GRAF设计了一种NeRF表示的条件变体,展示了如何从一组未设定pose的2D图像中学习出丰富的生成模型。除了viewpoint操作,还允许修改生成物体的形状和外观。
- 引入一个patch-based的判别器,它在多个尺度上对图像采样,这是有效学习高分辨率生成性NeRF的关键。
2 Related Work
2.1 图像合成
GANs显著提升了照片级真实感图像合成的显著水平。但2D图像是作为3D世界的投影获得的,虽然有一些方法表明disentangled factors在一定程度上抓住 了一些3D属性,但使用2D卷积网络对图像流形建模仍十分困难,特别是多视图一致以及寻求能可靠地将视点变化与物体appearance和identity分离的表示。因此,本文采取生成3D表示并明确地对图像形成过程进行建模的方法。
2.2 3D感知的图像合成
2.3 隐式表示
3D 几何的隐式表示在learning-based的3D重建中得到了普及,与基于体素或网格的方法相比,其主要优点是不离散空间,不受拓扑结构的限制。NeRF将场景表示为神经辐射场,这允许从posed 2D图像中对更复杂的真实世界场景进行多视角一致的新视角合成。本文受NeRF启发,设计了一种NeRF表示的条件变体GRAF,并展示了如何从一组未设定pose的2D图像中学习丰富的生成模型作为输入。
3 Method
3.1 Neural Radiance Fields(NeRF)
详细内容参考博客:https://blog.youkuaiyun.com/KeepLearning1/article/details/129923446
3.2 Generative Radiance Fields

"图 2 GRAF的整体框架"
GRAF的整体框架如图2所示,和GAN类似,GRAF分成Generator G θ G_{\theta} Gθ和Discriminator D ϕ D_{ \phi } Dϕ两个部分。generator部分将相机矩阵 K K K ,相机位姿 ξ \xi ξ,2D采样模板 v \mathcal{v} v 和形状/外观编码 z s ∈ R m / z a ∈ R n z_s ∈ R^m/z_a ∈ R^n zs∈Rm/za∈Rn作为输入, 并预测一个图像patch P ′ P^′ P′ ,其中每个Ray由 K , ξ , v K,\xi,v K,ξ,v 三个输入决定,conditional radiance field是generator唯一可学习的部分。discriminator对预测合成的patch P ′ P^′ P′ 和真实图片采样得到真实patch P P P进行判断。训练阶段,GRAF使用稀疏的 K × K K \times K K×K个像素点的fixed patch进行高效优化,测试阶段,预测出目标图片的每个像素的颜色值。(训练时如果也对每个像素值的颜色值进行预测,这个成本太高了)
3.2.1 Generator
从姿态分布
p
ξ
p_{\xi}
pξ中采样相机姿态(pose)
ξ
=
[
R
∣
t
]
\xi=[R|t]
ξ=[R∣t],在本文实验中,采用半球的均匀分布作为相机位置,相机面向坐标系的原点。根据数据集的不同,均匀地改变相机到原点的距离。同时选择K使得主点在图像的中心。
ν
=
(
u
,
s
)
ν = (u,s)
ν=(u,s)决定了
K
×
K
K × K
K×K个patch
P
(
u
,
s
)
P(u,s)
P(u,s)的中心位置
u
=
(
u
,
v
)
∈
R
2
u = (u,v)∈R ^ 2
u=(u,v)∈R2和尺度
s
∈
R
+
s ∈ R ^+
s∈R+。
这使得能够使用独立于图像分辨率的卷积鉴别器。从图像域
ω
ω
ω上的均匀分布中随机地绘制patch中心
u
∼
U
(
ω
)
u \sim U(ω)
u∼U(ω),并且从均匀分布
s
∼
U
(
[
1
,
S
]
)
s\sim U([1,S])
s∼U([1,S])中随机地绘制patch的尺度
s
s
s,其中
S
=
m
i
n
(
W
,
H
)
/
K
S = min(W,H)/K
S=min(W,H)/K,W和H表示目标图像的宽度和高度。此外,确保整个patch在图像域ω内。形状和外观变量
z
s
z_s
zs和
z
a
z_a
za分别来自形状和外观分布
z
s
∼
p
s
z_s \sim p_s
zs∼ps和
z
a
∼
p
a
z_a \sim p_a
za∼pa。在本文的实验中
p
s
和
p
a
p_s和p_a
ps和pa都是标准高斯分布。

Ray Sampleing
P
(
u
,
s
)
P(u,s)
P(u,s)由一系列2D图像坐标决定:

相应的3D rays由
P
(
u
,
s
)
P(u,s)
P(u,s)、相机矩阵
K
K
K ,相机位姿
ξ
\xi
ξ唯一确定,根据
ν
=
(
u
,
s
)
ν = (u,s)
ν=(u,s),训练阶段采样
R
=
k
2
R=k^2
R=k2条rays,推理阶段采样
R
=
W
H
R=WH
R=WH条Rays。
3D point Sampleing
对于辐射场的数值积分,沿着每条射线
r
r
r采样N个点
{
x
r
i
}
\left\{x^i_r\right\}
{xri}。和NeRF一样,采用分层采样方法(详细内容参考:https://blog.youkuaiyun.com/KeepLearning1/article/details/129923446)
Conditional Radiance Fields
辐射场由一个深度全连接的神经网络(MLP)表示,其参数
θ
θ
θ将三维位置
x
∈
R
3
x∈R^3
x∈R3和观察方向
d
∈
S
2
d∈S^2
d∈S2的位置编码映射到RGB颜色值
c
c
c和体积密度
σ
σ
σ:


与原始NeRF的公式相比,
g
θ
g_{\theta}
gθ以两个额外的latent code为条件:1)决定物体形状的shape code
z
s
∈
R
M
s
z_s \in R^{M_s}
zs∈RMs;2)决定物体外观的appearance code
z
a
∈
R
M
a
z_a \in R^{M_a}
za∈RMa。因此,称
g
θ
g_{\theta}
gθ为条件辐射场(conditional radiance fields)
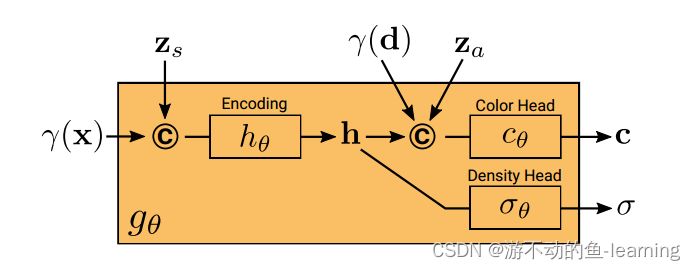
g
θ
g_{\theta}
gθ的结构如图4所示,先从位置编码
γ
(
x
)
\gamma(x)
γ(x)和shape code
z
s
z_s
zs计算得到shape encoding
h
h
h,密度头
σ
θ
\sigma _{\theta}
σθ 将此编码转换为体积密度
σ
σ
σ。为了预测 3D 位置 x 处的颜色 c,将 h 与 d 的位置编码
γ
(
d
)
\gamma(d)
γ(d)和外观代码
z
a
z_a
za连接起来,并将生成的向量传递给颜色头
c
θ
c_θ
cθ。独立于视点 d 和外观代码
z
a
z_a
za 计算
σ
σ
σ 以鼓励多视图一致性,同时将形状与外观分开。这鼓励网络使用潜在代码
z
s
z_s
zs和
z
a
z_a
za分别对形状和外观进行建模,并允许在推理过程中单独操作它们。
上述过程用公式表示如下:

所有映射(
h
θ
、
c
θ
和
σ
θ
h_θ、c_θ 和 σ_θ
hθ、cθ和σθ)均使用具有 ReLU 激活的全连接网络实现。
Volume Rendering
给定沿射线 r 的所有点的颜色和体积密度
(
c
r
i
,
σ
r
i
)
{(c ^i_ r , σ^i _r )}
(cri,σri),使用下面的公式中的渲染运算获得与射线 r 对应的像素的颜色
c
r
∈
R
3
c_r ∈ R ^3
cr∈R3 。 .结合所有
R
R
R条射线的结果,将预测的patch表示为
P
′
P^′
P′,如图2所示。

3.2.2 Discriminator
鉴别器
D
ϕ
D_{\phi}
Dϕ 被实现为一个卷积神经网络(详见table2),它将预测的patch
P
′
P^′
P′与从数据分布
p
D
p_D
pD中绘制的真实图像
I
I
I中提取的patch
P
P
P进行比较。为了从真实图像
I
I
I 中提取
K
×
K
K × K
K×K patches,首先从用于绘制上面生成器的patch的相同分布
p
ν
p_ν
pν中绘制
ν
=
(
u
,
s
)
ν = (u, s)
ν=(u,s)。然后,通过使用双线性插值在 2D 图像坐标
P
(
u
,
s
)
P(u, s)
P(u,s)处查询
I
I
I 来对真实的patch
P
P
P 进行采样。在下文中,使用
Γ
(
I
,
ν
)
Γ(I, ν)
Γ(I,ν)来表示这种双线性采样操作。鉴别器类似于 PatchGAN ,本文方法允许连续位移 u 和缩放 s 而 PatchGAN 使用 s = 1。更重要的是要注意本文方法不根据 s 对真实图像 I 进行下采样,反之,在稀疏位置查询 I 以保留高频细节,见图3.

通过实验,作者发现具有共享权重的单个鉴别器足以用于所有patch,即使这些patch是在具有不同尺度的随机位置采样的。由于scale决定了patch的感受野。因此,为了facilitate训练,从更大的接受域的patch开始,以捕获全局上下文。然后,逐步对具有较小接受域的patch进行采样,以改进局部细节。
3.2.3 Training and Inference
I
I
I 表示来自数据分布
p
D
p_D
pD的图像,让
p
ν
p_ν
pν表示随机patches上的分布(参见第 3.2.1 节)。使用具有 R1 正则化的非饱和 GAN 目标来训练模型:

其中,
f
(
t
)
=
−
l
o
g
(
1
+
e
x
p
(
−
t
)
)
f(t) = − log(1 + exp(−t))
f(t)=−log(1+exp(−t)),
λ
\lambda
λ控制正则化器的强度。在鉴别器中使用谱归一化 和实例归一化 ,并使用 RMSprop 训练我们的方法,批量大小为 8,生成器和鉴别器的学习率分别为 0.0005 和 0.0001。在推断时,随机采样
z
s
、
z
a
和
ξ
z_s、z_a 和 ξ
zs、za和ξ,并预测图像中所有像素的颜色值。
4 实验
Datasets
两个合成数据集:
- Photoshapes ,150K椅子
- CarlaDriving, 18种汽车模型的10K图像,这些图像具有随机采样的颜色和逼真的纹理及反射特性
三个真实世界的数据集:
- 使用包含 celebA 和 celebA-HQ 的 Faces 数据集分别进行分辨率高达 1282 和 5122 像素的图像合成
- Cats 数据集
- Caltech-UCSD Birds-200-2011 数据集
Baseline
将本文的方法与两个原作者实现的用于 3D 感知图像合成的最先进模型进行比较:
- PLATONICGAN 生成 3D 对象的体素网格,使用可微分投影到图像平面体积渲染
- HoloGAN 生成一个抽象的体素化特征表示,并使用 3D 和 2D 卷积的组合来学习从 3D 到 2D 的映射
- 进一步考虑了 HoloGAN 的修改版本(HoloGAN w/o 3D Conv),其中通过移除 3D 卷积层来减少学习映射的容量
- 作为参考,还将本文的结果与具有 ResNet 架构的最先进的 2D GAN 模型 进行了比较
Evaluation Metrics
- Frechet Inception Distance (FID) ,量化图像保真度
- Kernel Inception Distance (KID)
- Minimum Matching distance(MMD)来测量 100 个重建形状与其在 ground truth 中最接近的形状之间的倒角距离 (CD),以进行定量比较,并显示重建的定性结果。
下面研究几个与本文算法相关的关键问题。
4.1 生成辐射场与基于体素的方法相比如何?
使用分辨率为
6
4
2
64^2
642像素的图像将本文模型与baseline进行比较,如图5 ,所有方法都能够区分对象身份和相机视点。然而,PLATONICGAN 在表示薄结构方面存在困难,与GRAF相比,PLATONICGAN 和 HoloGAN 都会导致可见的伪影。表1中较大的FID分数也说明了这一点。


在 Faces 和 Cats 上,HoloGAN 获得了与GRAF相似的 FID 分数,因为这两个数据集在相机方位角方面仅表现出很小的变化,而其他数据集涵盖了更大的视点变化。这表明,由于 HoloGAN 的低维 3D 特征表示和可学习的投影,它更难从不同的角度准确捕捉物体的外观。与之相反,GRAF的连续表示不需要学习投影并从任意视图渲染高保真图像。
4.2 3D 感知生成模型是否可以扩展到高分辨率输出?
由于使用基于体素的表示,当遇到高分辨率图像时,PLATONICGAN 变得非常占用内存。因此,只把GRAF与HoloGAN以及没有3D Conv的HoloGAN进行对比实验。训练以
12
8
2
128^2
1282分辨率进行,推理以更高分辨率采样,在
12
8
2
−
51
2
2
128^2-512^2
1282−5122之间。

表 2 中的结果表明,GRAF方法显著改善了朴素的双线性上采样,这表明GRAF学习到的表示可以很好地泛化到更高分辨率。GRAF在全分辨率下训练时获得了最小的 FID 值。没有 3D Conv 的 HoloGAN 在视点变化较小的Faces数据集上取得了与GRAF相当的结果。
4.3 应该避免学习预测吗?

如图 6 所示,HoloGAN无法在高分辨率下从外观中分离出视点,改变不同的风格方面,如面部表情,甚至完全忽略姿势输入。作者将可学习投射确定为这种行为的根本原因。特别是,作者发现移除 3D 卷积层使 HoloGAN 能够更紧密地遵守input pose,见图 6(中)。为了更好地研究多视图一致性,为 HoloGAN w/o 3D Conv 和GRAF方法在随机视点生成了同一实例的多个图像,并使用 COLMAP 执行稠密3D 重建。由于重建取决于视图之间的一致性,因此重建精度可以代表生成图像的多视图一致性。从表 3 和图 7 可以明显看出,当使用GRAF中的图像作为输入时,多视图立体效果明显更好。相比之下,没有 3D Conv 的 HoloGAN 可以建立更少的对应关系,它使用学习的 2D 层进行上采样。对于具有 3D 卷积的 HoloGAN,性能会进一步下降,下图所示。因此,作者推测通常应该避免学习预测。

4.4 生成辐射场是否能够将形状与外观分开?
除了解开相机和场景属性之外,GRAF还学习了解开形状和外观,这些形状和外观可以在推理过程中通过 zs 和 za 进行控制。对于 Cars and Chairs,外观代码控制对象的颜色,而对于 Faces,它编码皮肤和头发的颜色。

4.5 multi-scale patch判别器有多重要?
将multi-scale patch判别器与(Patch) 与接收整个图像作为输入的判别器 (Full) 进行了比较。由于这是非常占用内存的,只考虑分辨率为
6
4
2
64^2
642的图像,并为
h
θ
和
c
θ
(
d
i
m
/
2
)
h_θ 和 c_θ (dim/2)
hθ和cθ(dim/2)使用一半的隐藏维度。表 4 显示我们的multi-scale patch判别器在 Cars 上实现了与完整图像鉴别器相似的性能,并且在 CelebA 上的性能甚至更好。对这种现象的一个可能解释是,随机补丁采样作为一种数据增强策略,有助于稳定 GAN 训练。相反,当仅使用局部补丁 (s = 1) 时,multi-scale patch判别器无法学习正确的形状,导致表 4 中的高 FID 值。因此作者得出结论,随机尺度的采样patch对于鲁棒性至关重要表现。

5 结论
本文引入了用于高分辨率 3D 感知图像合成的生成辐射场 (GRAF)。实验表明,与基于体素的方法相比,GRAF能够生成具有更好多视图一致性的高分辨率图像。但是,这仅限于具有单个对象的简单场景。结合归纳偏差,例如深度图或对称性,将使本文的模型在未来扩展到更具挑战性的现实场景。


















 1467
1467



 到【灌水乐园】发言
到【灌水乐园】发言







