




课程学习自我总结
这是第一次整个团队完整地开发一个应用。因为我这次主要负责是前端部分的工作。我们小组采用了前后端分离的开发模式,前端和后端通过RESTFUL API进行交互。
我们的前端采用的是Vue.js的框架,而后端采用的是JAVA Spring的框架,然后因为前后端语言开发环境不一样,然后我因为考虑到后端采用的是JAVA,没有node和npm环境,所以我没有选择利用vue-cli的方式进行开发,后来因为和后端开发者交流后,后端觉得前端部分的代码如果作为后端的resource的来说,不太合适。于是我们选择了由前端这边实现前端的静态资源服务器,然后所有的静态资源请求都通过这个服务器处理,而后端只需要处理其他的请求,真正实现前后端分离。
这次虽然是前后端分离,但是前端和后端在API的讨论上做得工作还是蛮多的。充分的沟通是前端与后端能够分离工作的前提,所以团队合作需要有效的沟通和合作。最后这次很感谢后端的@south270在这次项目中的出色表现。
这次是初学Vue,所以在写前端的时候可能会遇到很多的问题,很多问题都能够阅读文档或者再谷歌上搜索问题能够得出答案。所以要善用文档和API。虽然这次没有用到Flux架构,但是在写前端的时候还是能够体会到store的用处。真正写的时候才能够体会到架构设计的意义。
PSP 2.1 统计表
| PSP 2.1 | Personal Software Process Stages | Time (%) |
|---|---|---|
| Planning | 计划 | 7 |
| Estimate | 估计这个任务需要多少时间 | 7 |
| Development | 开发 | 80 |
| Analysis | 需求分析 (包括学习新技术) | 10 |
| Design Spec | 生成设计文档 | 10 |
| Design Review | 设计复审 (和同事审核设计文档) | 8 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 8 |
| Design | 具体设计 | 10 |
| Coding | 具体编码 | 20 |
| Code Review | 代码复审 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 14 |
| Reporting | 报告 | 13 |
| Test Report | 测试报告 | 6 |
| Size Measurement | 计算工作量 | 3 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 4 |
Github
Dashboard
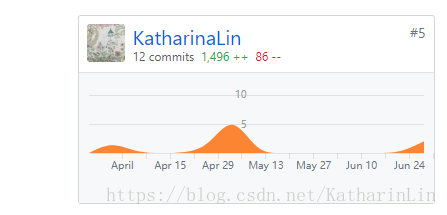
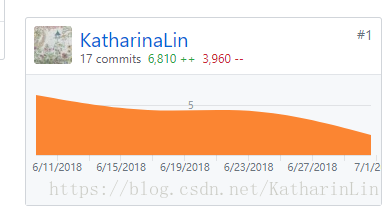
Code
自认为最得意/或有价值/或有苦劳的工作清单
1.搭建好前端的登录框架和管理框架
2.把前端按照页面组织起来
3.能够通过RESTFUL API的设计和沟通和后端协作得很好
个人的技术类、项目管理类博客清单
1.微信小程序开发技术学习
https://blog.youkuaiyun.com/katharinlin/article/details/79921398
2.Vue.js学习过程(一)
https://blog.youkuaiyun.com/katharinlin/article/details/80870048
3.Vue.js学习过程(二)
https://blog.youkuaiyun.com/KatharinLin/article/details/80870486

















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









