









-
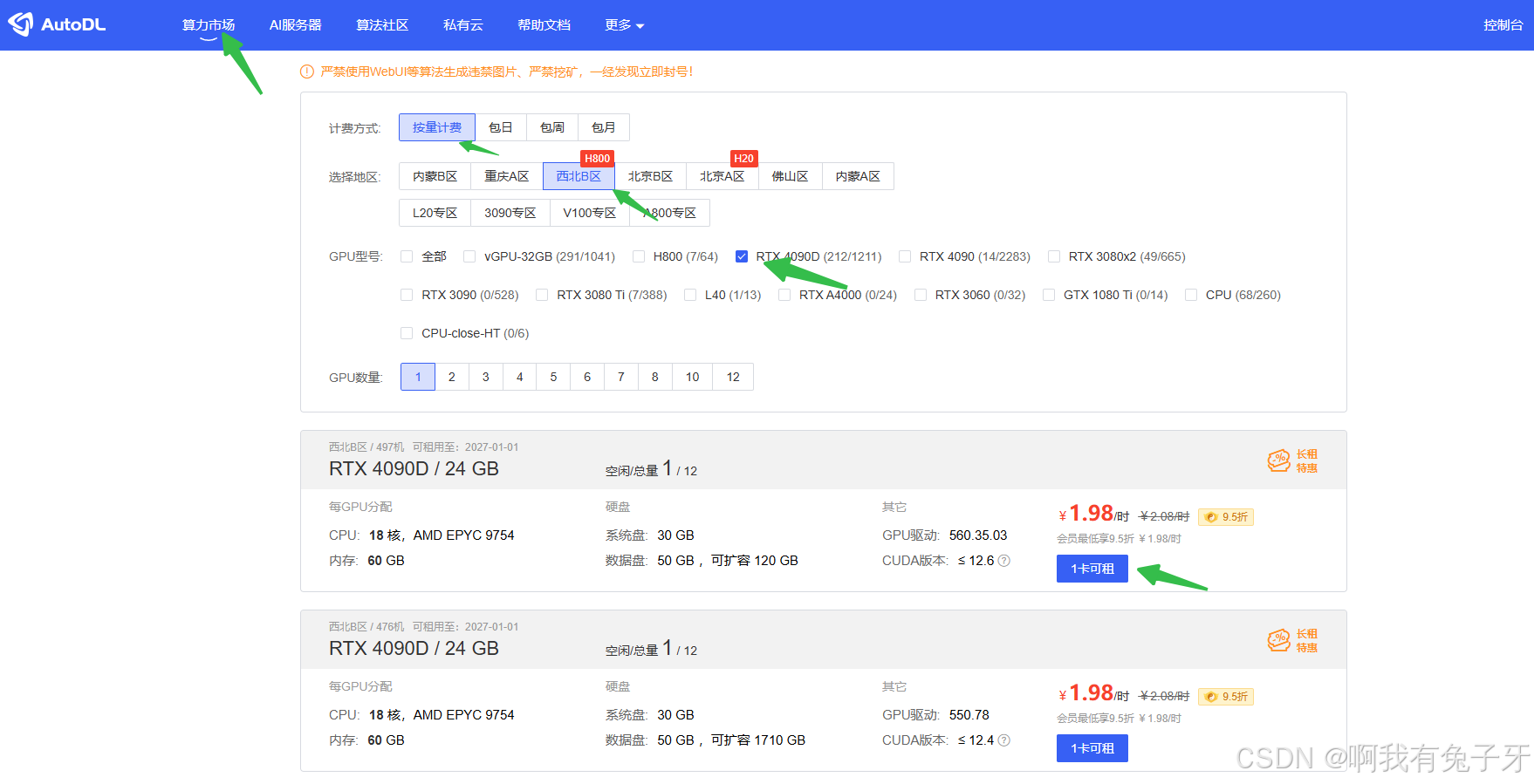
任务1 获取算力来源
GPU(图形处理单元)是一种专门设计用于加速图形渲染的处理器,最初用于计算密集型图形任务,如3D渲染和游戏图像处理。GPU由大量并行计算核心组成,使其在处理大量小任务时效率极高。如今,GPU广泛应用于深度学习、科学计算、数据分析等领域,因为它能够加速矩阵运算和向量计算,显著提高模型训练和大规模数据处理的速度。
二、AutoDL算力云
AutoDL算力云是一种专门用于深度学习任务的云计算平台,提供高效的算力资源和自动化的深度学习模型开发工具。它旨在帮助开发者、研究人员和企业用户通过云端实现从数据预处理、模型训练到部署的自动化流程。AutoDL算力云一般集成了多种自动机器学习(AutoML)功能,使得用户能够以更少的人工干预和技术门槛,快速获得高质量的深度学习模型。
-
注册页面:https://www.autodl.com/login,使用手机号在注册页面进行注册,实名认证,绑定微信
-
获取gpu
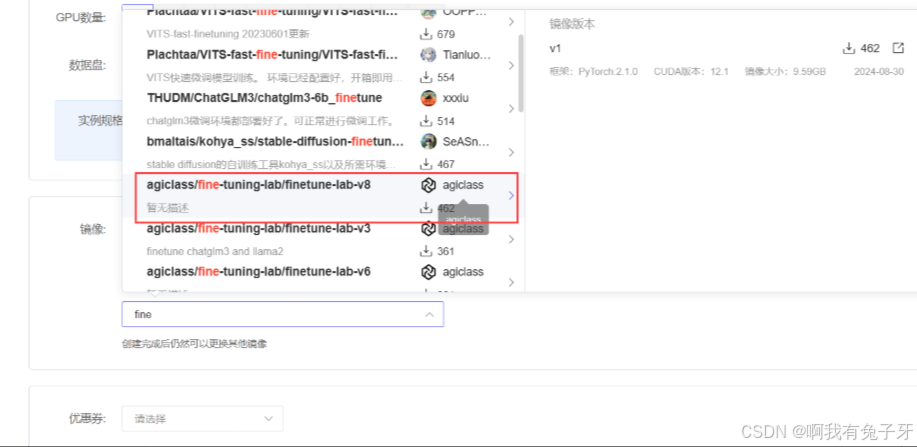
社区镜像搜索:agiclass/fine-tuning-lab/finetune-lab-v8 / v1,搜不到手动输入前几位就行
-
-
任务二 远程操作你的机器——工具拾取
-
下载MobaXterm:MobaXterm 是一个功能强大的终端调试工具,集成了多种网络工具和 SSH 客户端。
-
具体教程:https://blog.youkuaiyun.com/m0_56182552/article/details/140146476?ops_request_misc=%257B%2522request%255Fid%2522%253A%252216b5835eb846fb82abd7683e2fa509b9%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=16b5835eb846fb82abd7683e2fa509b9&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~time_text~default-7-140146476-null-null.142^v101^pc_search_result_base8&utm_term=mobaxterm%E4%B8%8B%E8%BD%BD%E6%95%99%E7%A8%8B&spm=1018.2226.3001.4187
-
-
MobaXterm 软件在其官网下载即可,https://mobaxterm.mobatek.net/download.html
-
解压压缩文件
-
打开由两个文件,双击 MobaXterm_installer_24.3.msi 进行安装,安装方法很简单,一步一步进行即可。
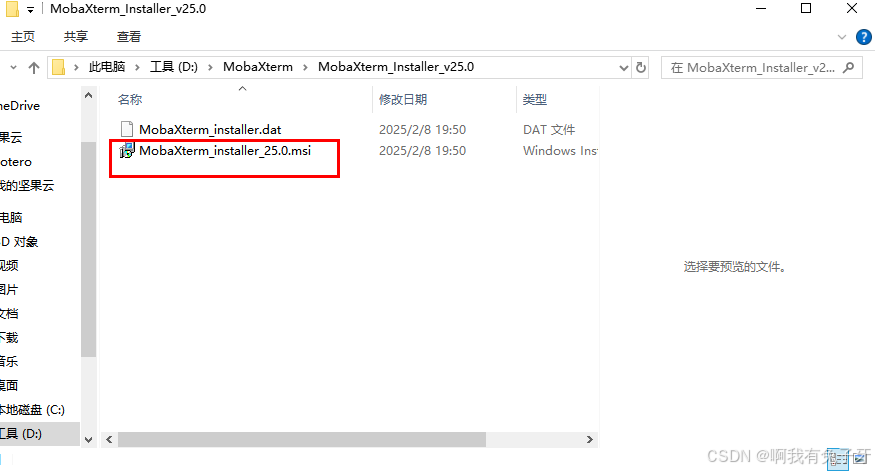
等待片刻,next点击同意下一步,点击修改路径,提前建好文件夹
任务三 远程操作你的机器——正式控制
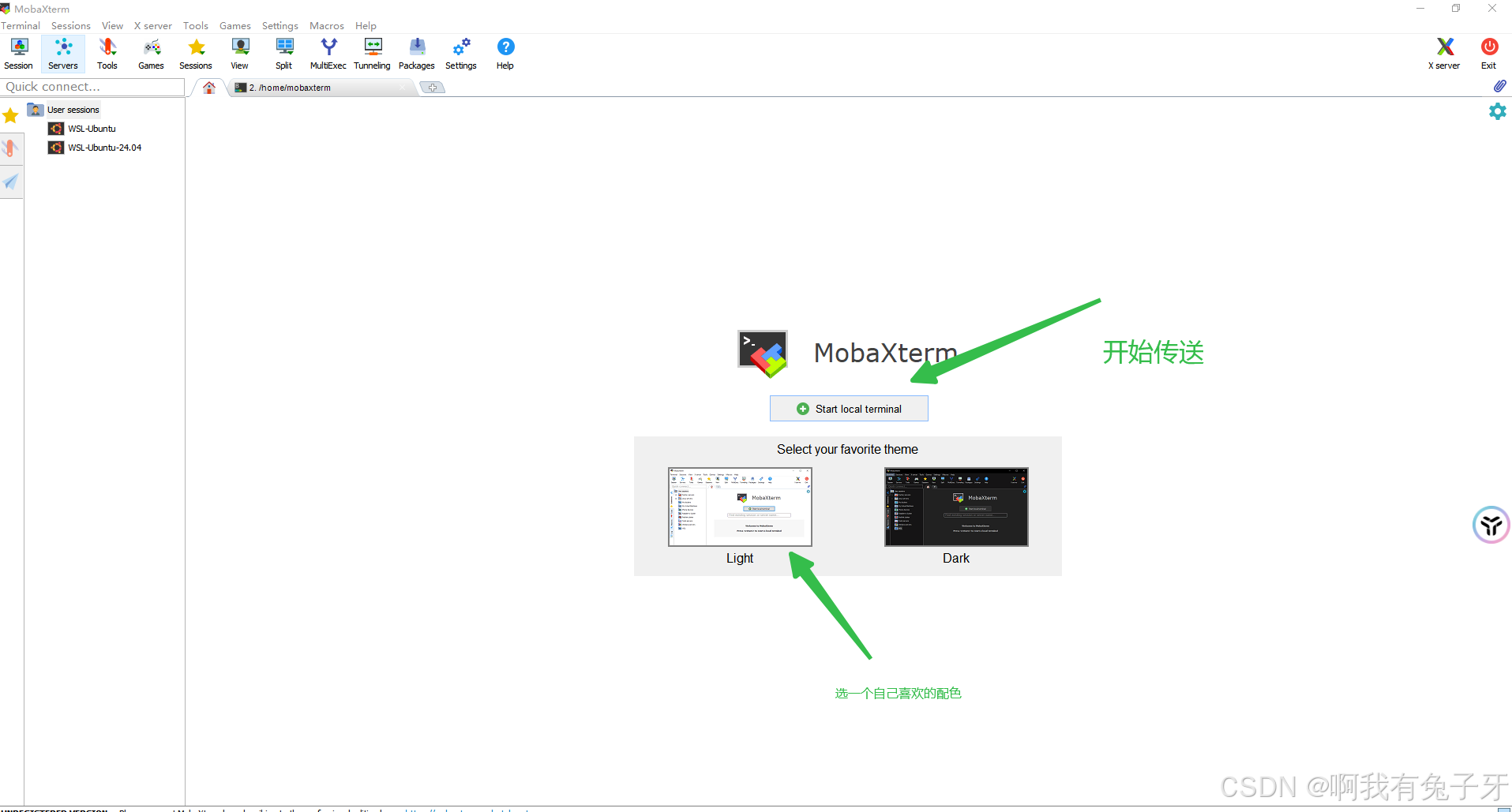
直接安装,完成,在桌面会看见桌面快捷启动图标,,双击桌面上的MobaXterm图标就可以使用了。
-
-
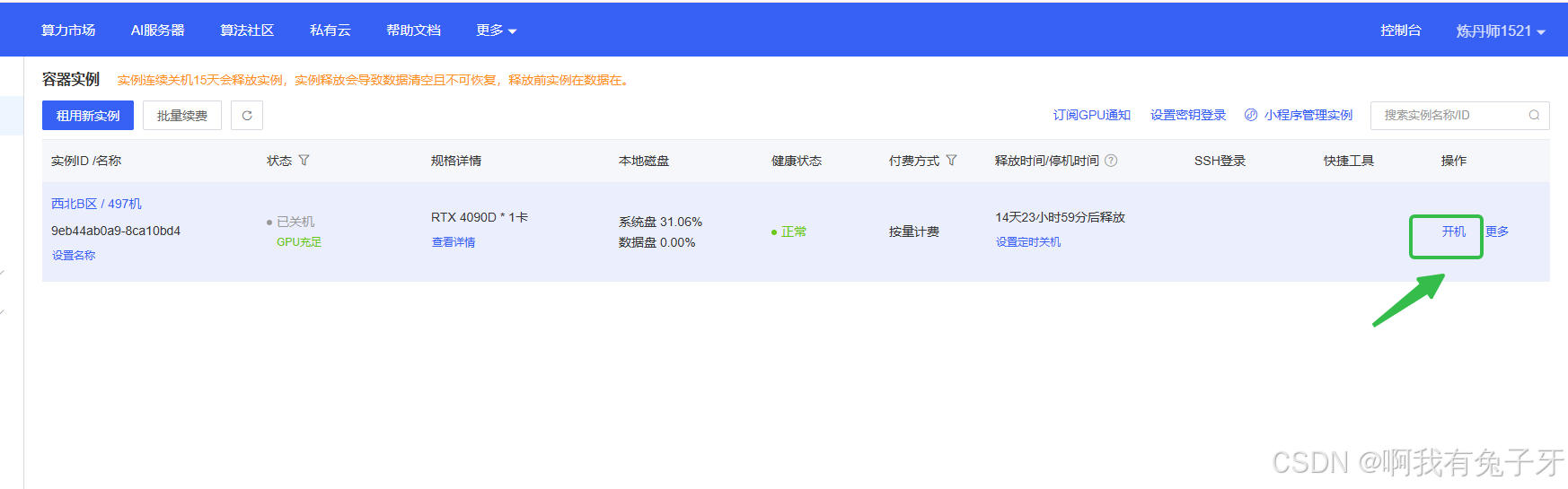
无卡模式开机,这样比较省钱,不介意的小伙伴直接开机就行
-
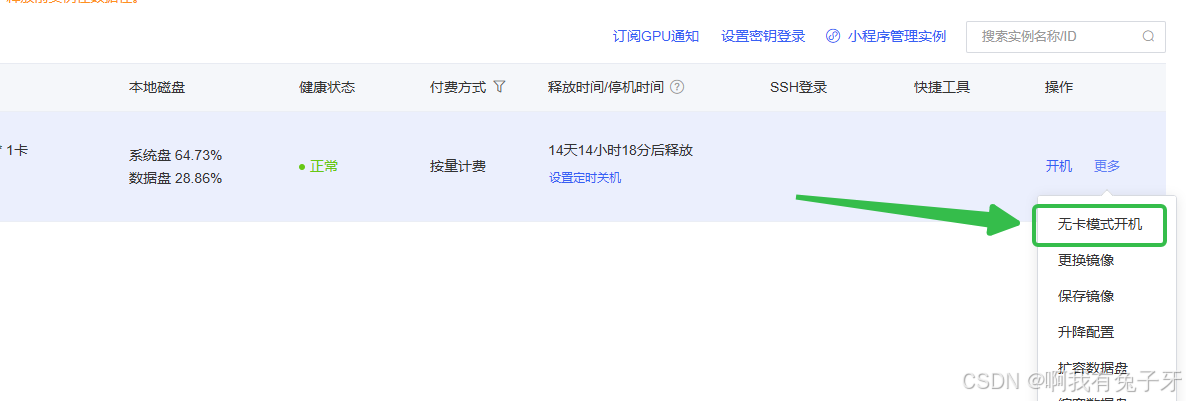
-
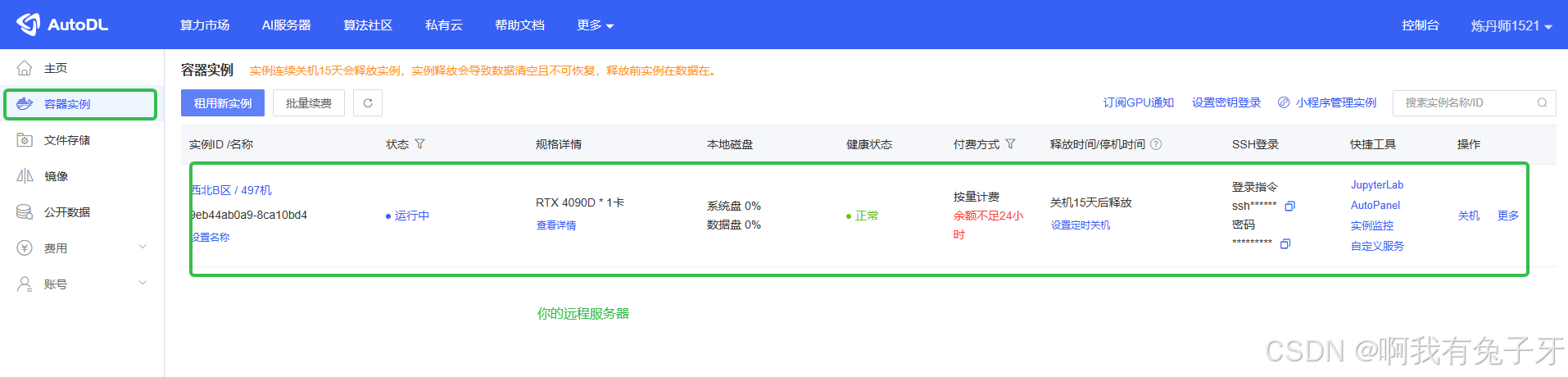
进入AutoDL服务器获取连接指令,
-
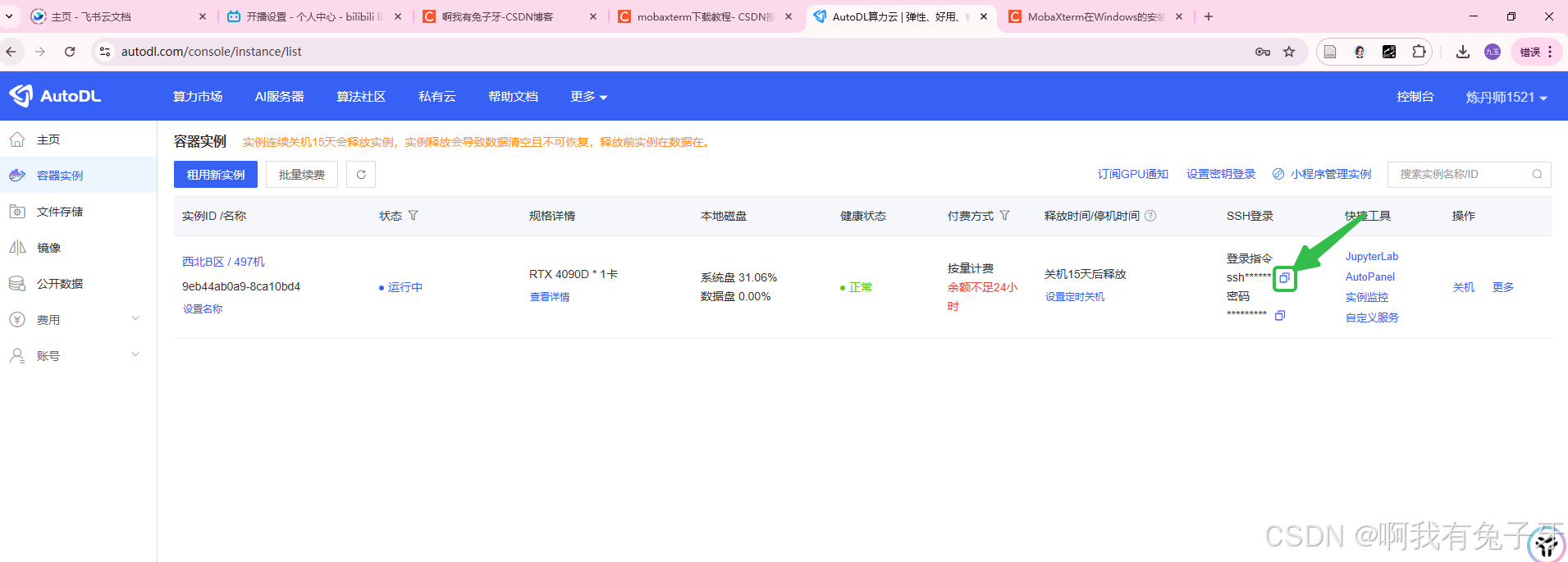
-
右键粘贴,回车
-
-
会要求你输入密码,到AutoDL复制
-
复制成功后,点一下右键就粘贴了,直接回车,密码是不会显示在屏幕上的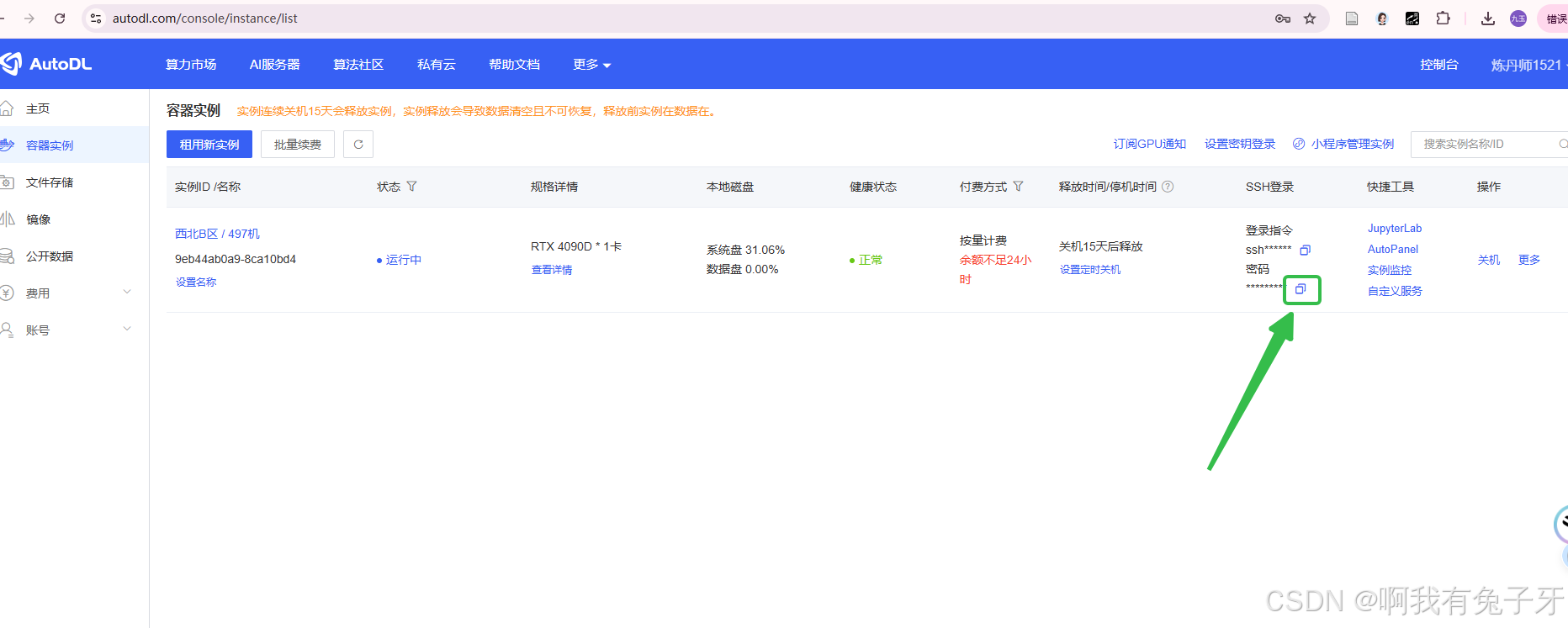
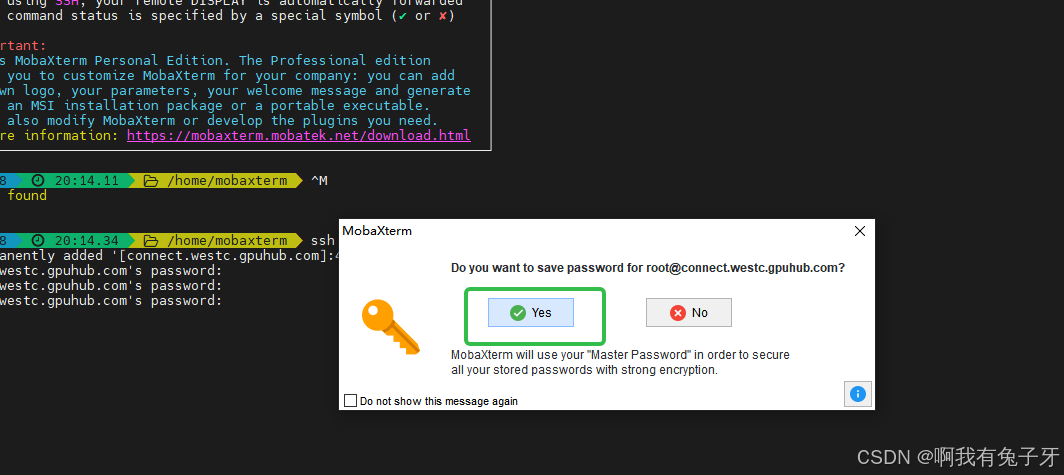
- 单独设置一个好记的mobaXterm的使用密码
学会连接之后,暂时不用。先关机,免得浪费钱。
任务4 下载微调的框架 llama_factory——获取微调的工具箱
参考:LLaMA-Factory使用指南:快速训练专属大模型,打造定制化AI解决方案!_llama-factory训练-优快云博客
LLama-Factory,它是一个开源框架,这里头可以找到一系列预制的组件和模板,让你不用从零开始,就能训练出自己的语言模型(微调)。不管是聊天机器人,还是文章生成器,甚至是问答系统,都能搞定。而且,LLama-Factory 还支持多种框架和数据集,这意味着你可以根据项目需求灵活选择,把精力集中在真正重要的事情上——创造价值。
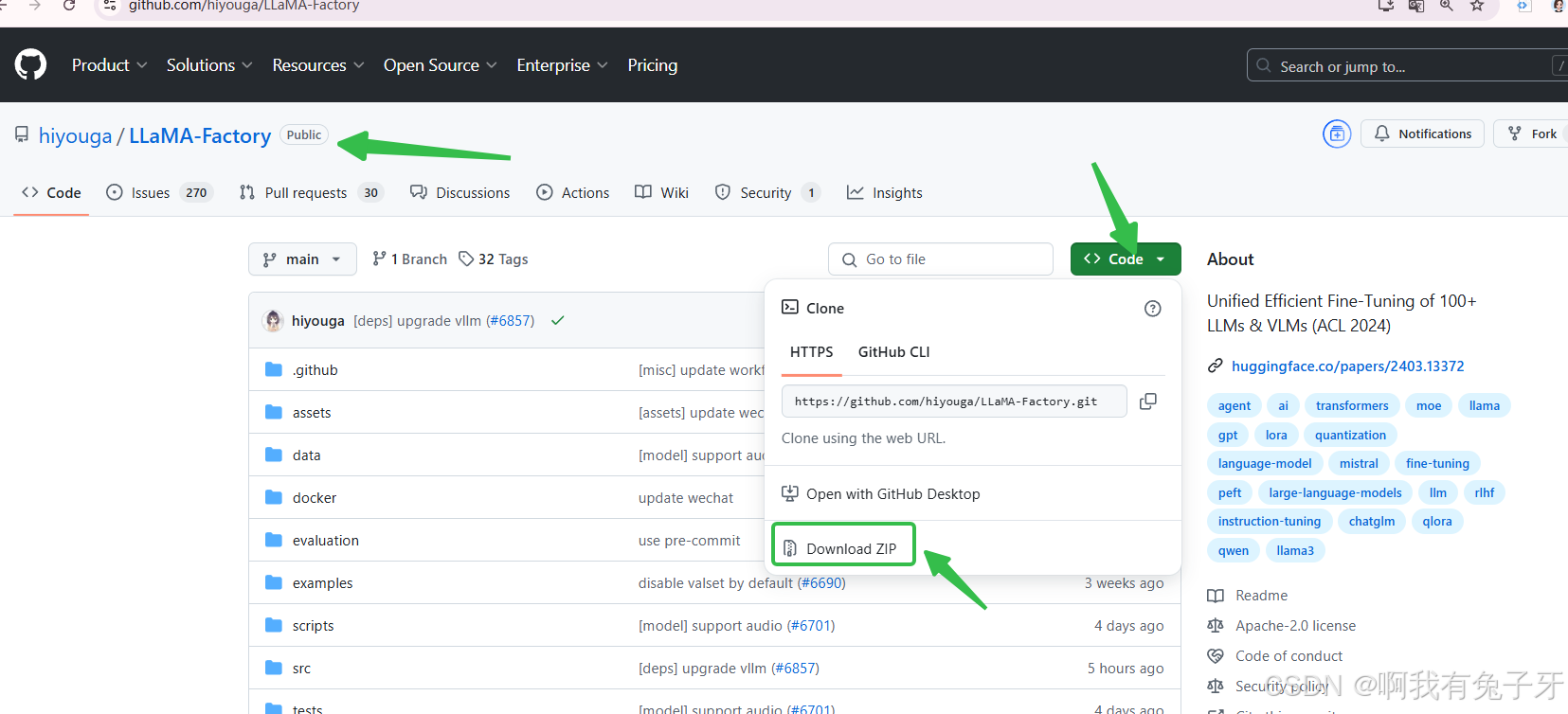
llama_factory项目下载地址(要用github需要科学上网一下):https://github.com/hiyouga/LLaMA-Factory
知乎解读:https://zhuanlan.zhihu.com/p/684989699
去把AutoDL的服务器打开,使用mobaXterm远程连接服务器,连接成功后,执行以下代码
# Clone the repository
git clone https://github.com/hiyouga/LLaMA-Factory.git
第一句执行情况如下:正常,git从github下载文件向来容易抽风,所以我们直接下载好zip到本地,再弄到服务器去

下载好之后,我们首先要搞清楚服务器的数据放在哪里。AutoDL的数据存在这个文件夹下面,这是一个临时盘,实例释放后数据也没了:
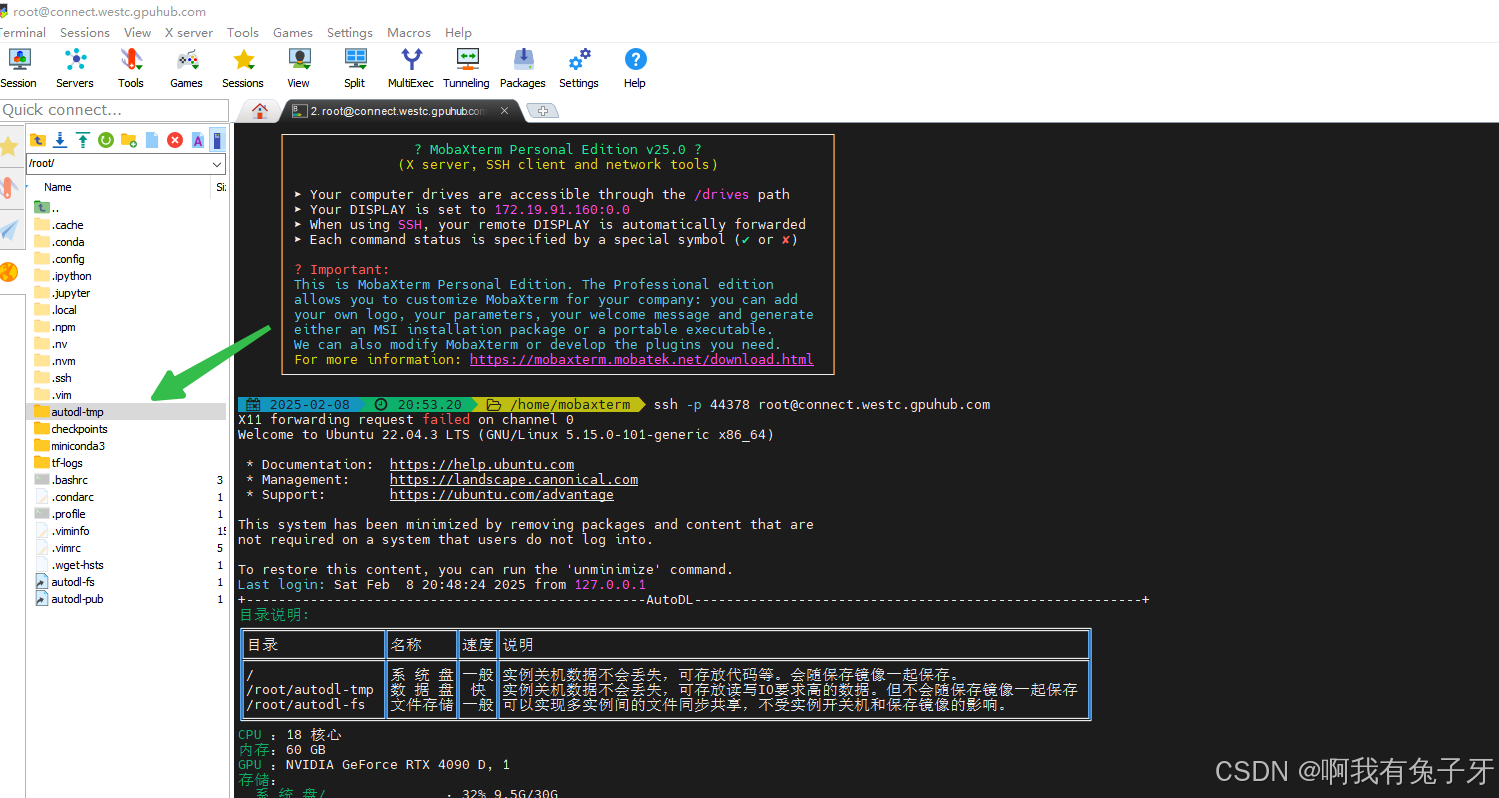
回到MobaXterm,到达数据盘
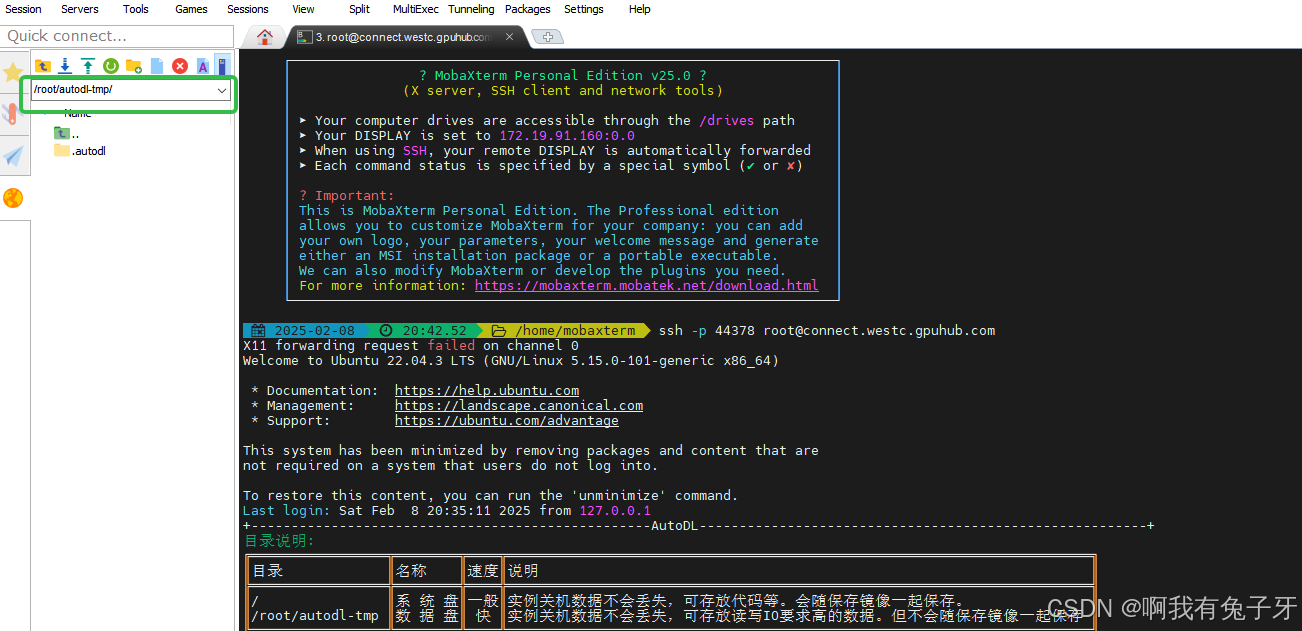
找到刚刚下载好的zip,拖进MobaXterm,能看到文件被传输进去
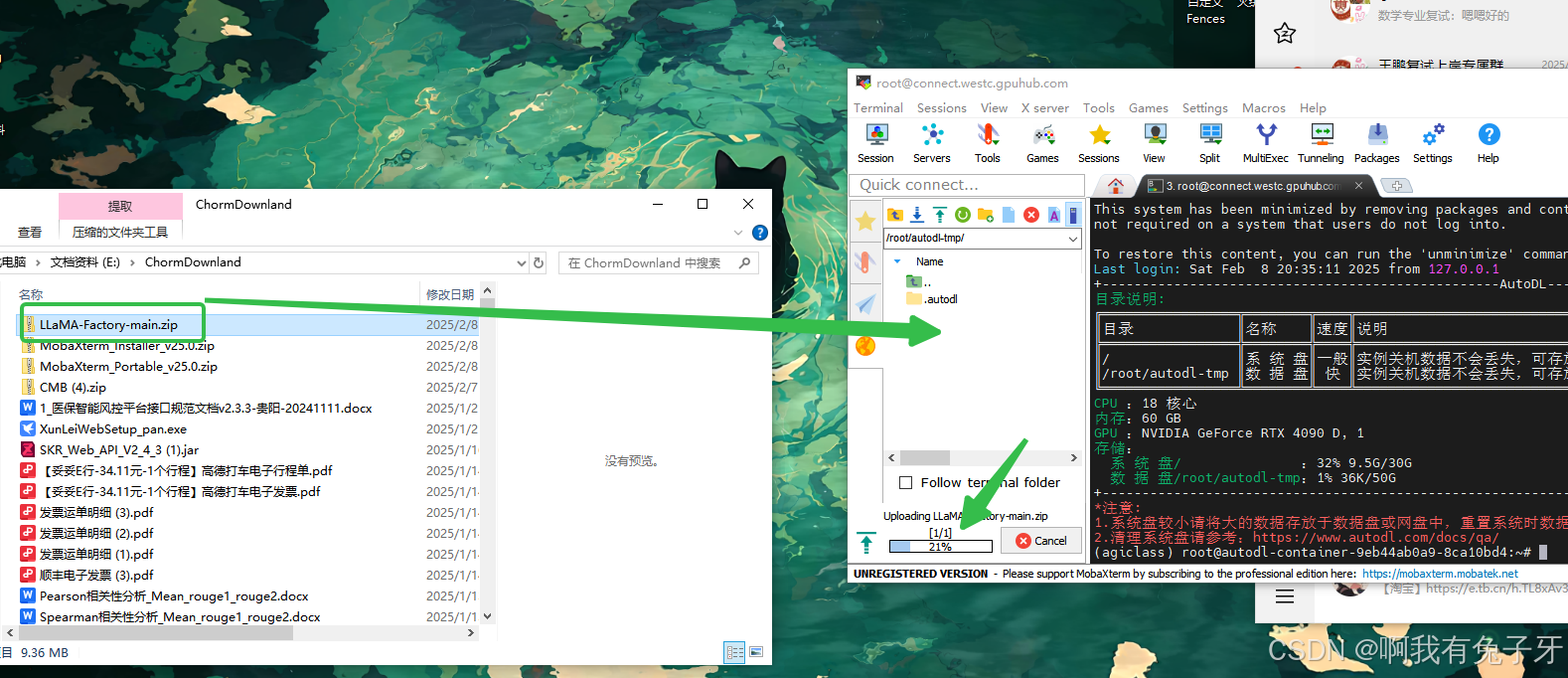
使用图中指令到达数据盘,#前面变成数据盘的名字就成功了

输入指令:unzip LLaMA-Factory-main.zip解压文件,解压后右键刷新下
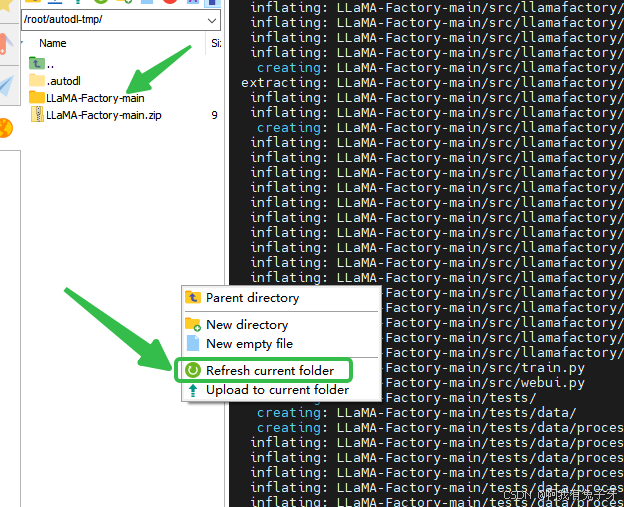
使用命令进入文件夹

执行以下命令:
创建环境: conda create -n llama_factory python=3.10
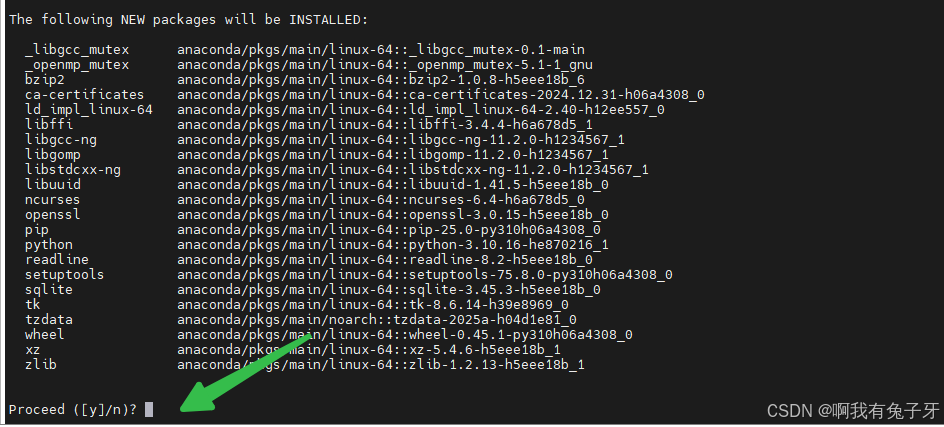
这里输入y,回车,等待安装好,
#激活刚才创造的环境: conda activate llama_factory
# 安装依赖工具 pip install -r requirements.txt
pip install -e ".[torch,metrics]"
运行示例如下:

任务5 选择一个需要的大模型
到魔搭社区(modelscope):https://www.modelscope.cn/home,下载想要部署的大模型,以qwen-7B-Chat为例,搜索qwen-7B-Chat。(记得注册或者登陆下)
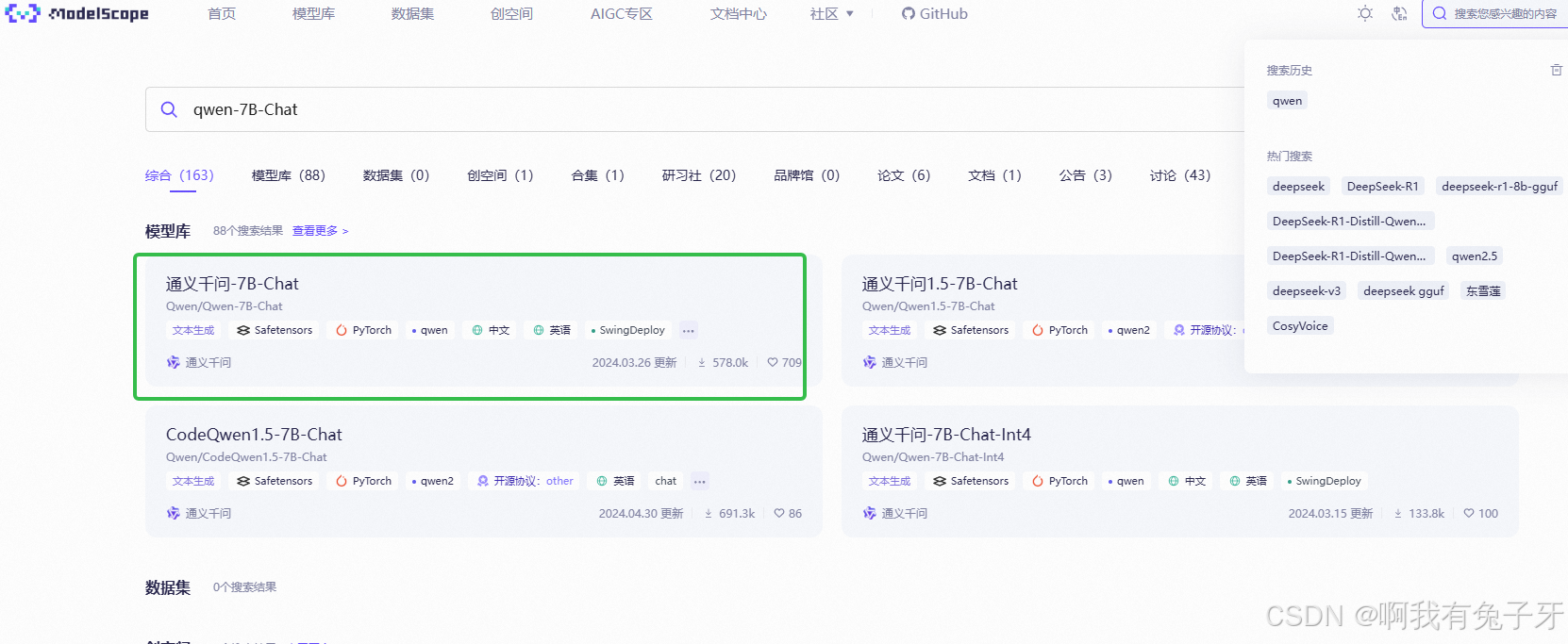
点击模型文件,点击下载模型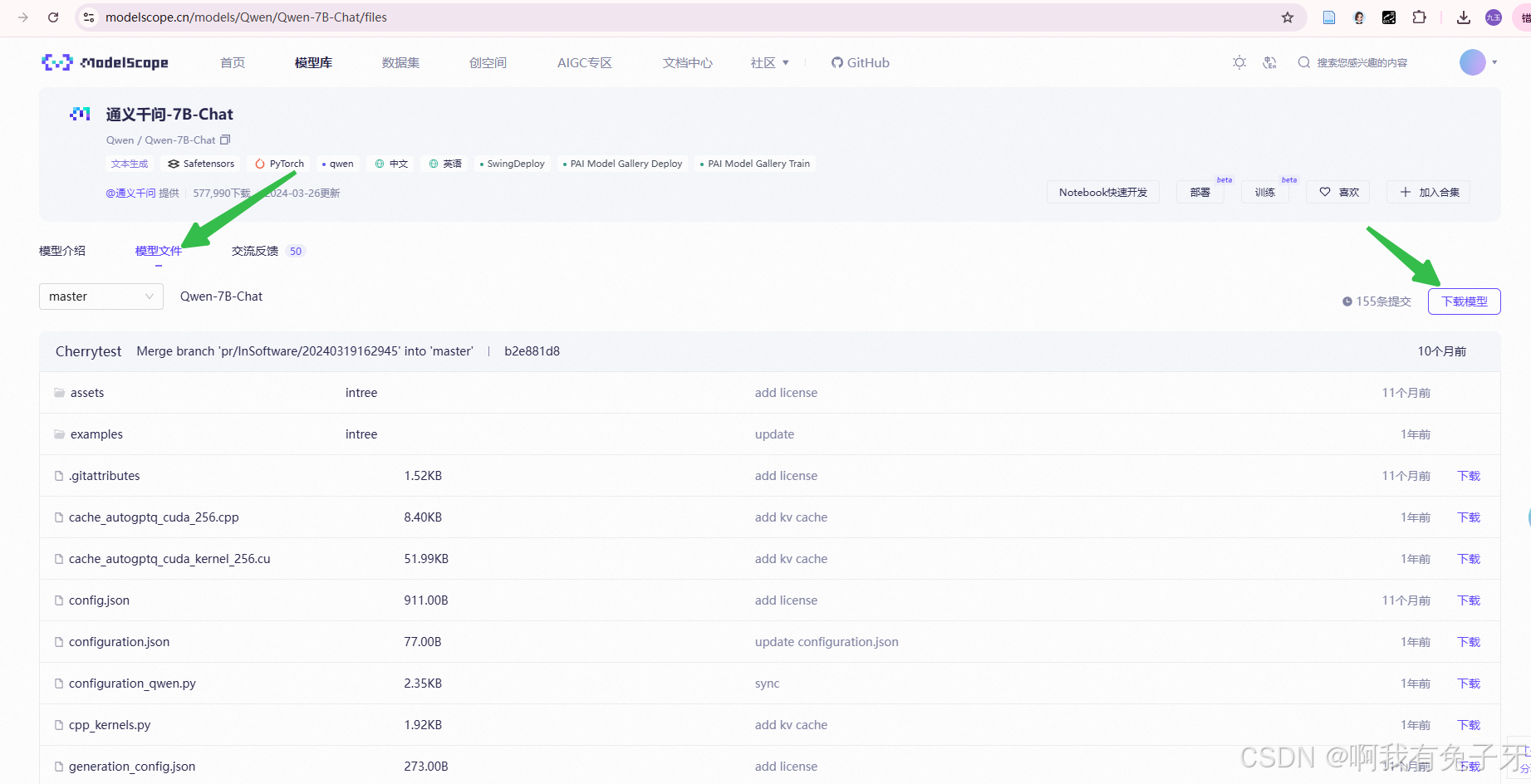
复制模型路径
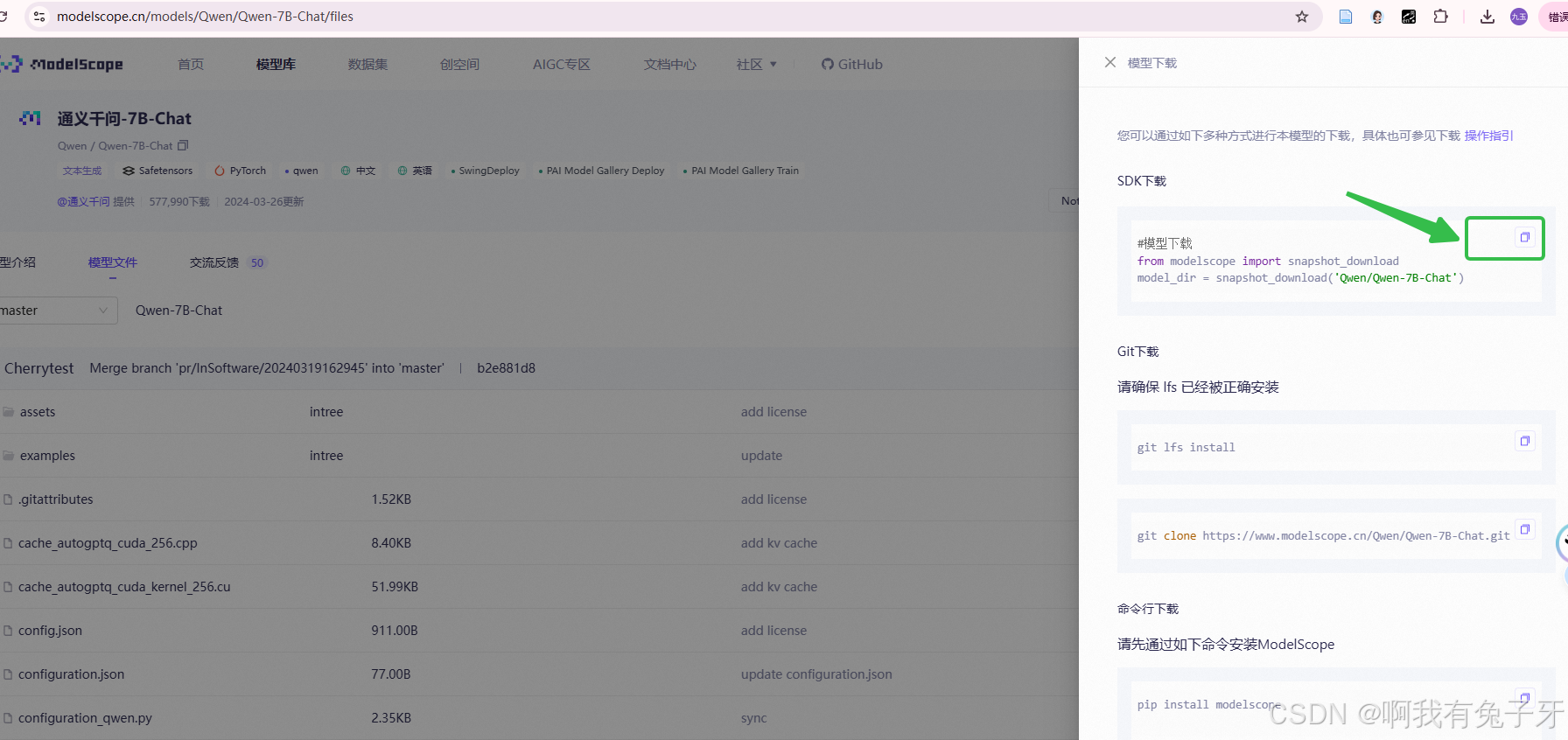
将这行代码放入download_model.py文件中,代码内容如下,cache_dir表示模型存放的位置:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen-7B-Chat',cache_dir='/root/autodl-tmp/')
接下来使用MobaXterm连接服务器,然后使用将这个py文件上传服务器即可,如下所示:
接下来执行
cd autodl-tmp
conda activate llama_factory
在终端运行download_model.py文件,命令如下所示:
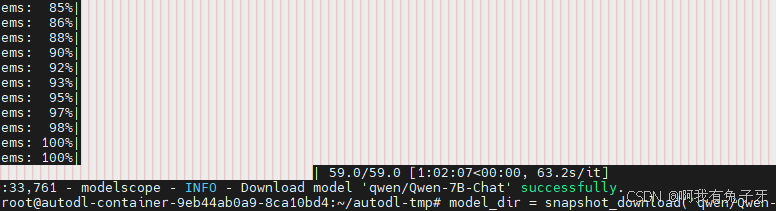
python download_model.py
(调用这个py文件可能会报错,缺少”modelscope“模块,使用语句pip install modelscope,重新调用就行了)
下载过程比较慢,下载的模型保存在之前代码的cache_dir='/root/autodl-tmp/'位置。着急下载进度的可以刷新一下AutoDL看看数据盘变化。
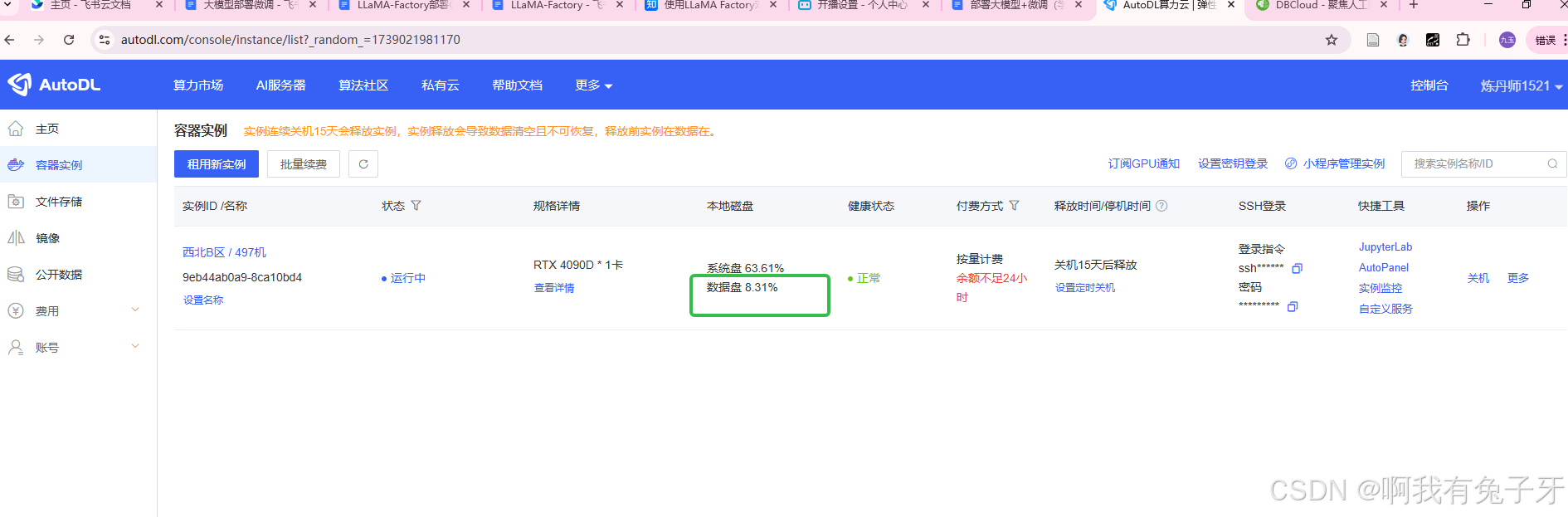
在下载的时候可以重新开一个MobaXterm的窗口,在同一个服务器上执行其他任务,点加号在连接一次就有一个新窗口啦
下载好如下:
任务6 运行工具箱LLaMA-Factory
MobaXterm进入LLaMA-Factory-main的
使用下述命令找到可用的GPU编号,这里是0号。
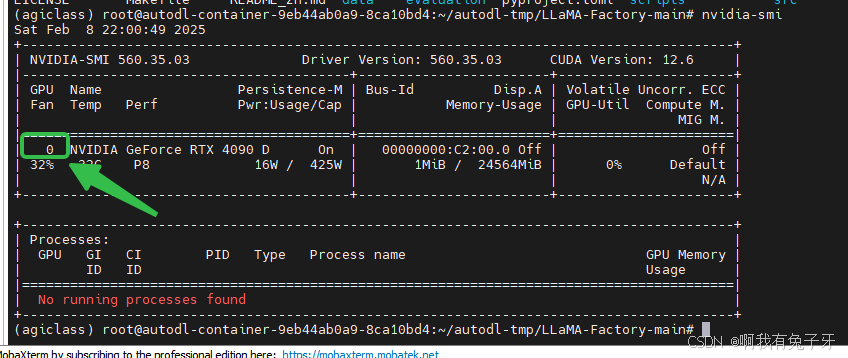
所以应使用命令
CUDA_VISIBLE_DEVICES=0 python src/webui.py,效果如下:
这种错误统一使用 :
pip install 没有的模型名字,如果有一个包的版本范围让你选择的,就无脑选可选择的最高版本,等不报类似错误后再次执行CUDA_VISIBLE_DEVICES=0 python src/webui.py
正常运行效果如下,把连接复制到浏览器打开,会发现打不开,
因为LLamaFactory的默认访问端口为7860,所以我们需要进行端口映射才可以访问。
注意:
在ModelScope中,我们是通过export GRADIO_SERVER_PORT=7860 GRADIO_ROOT_PATH=/${JUPYTER_NAME}/proxy/7860/命令设置环境变量来实现的。
以上方法不可行在AutoDL中不可行。
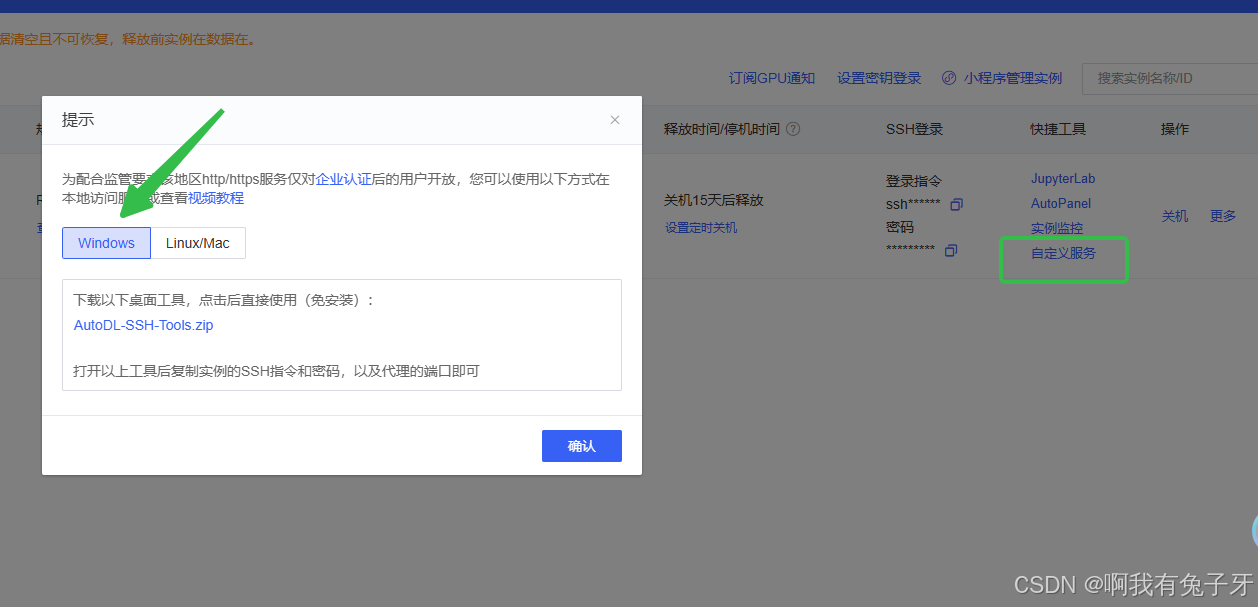
AutoDL官方提供方法是使用SSH隧道来实现。
具体方法:
点击自定义服务,待会我们是在windows的浏览器启动llmafactory,所以下载桌面工具,解压后直接使用
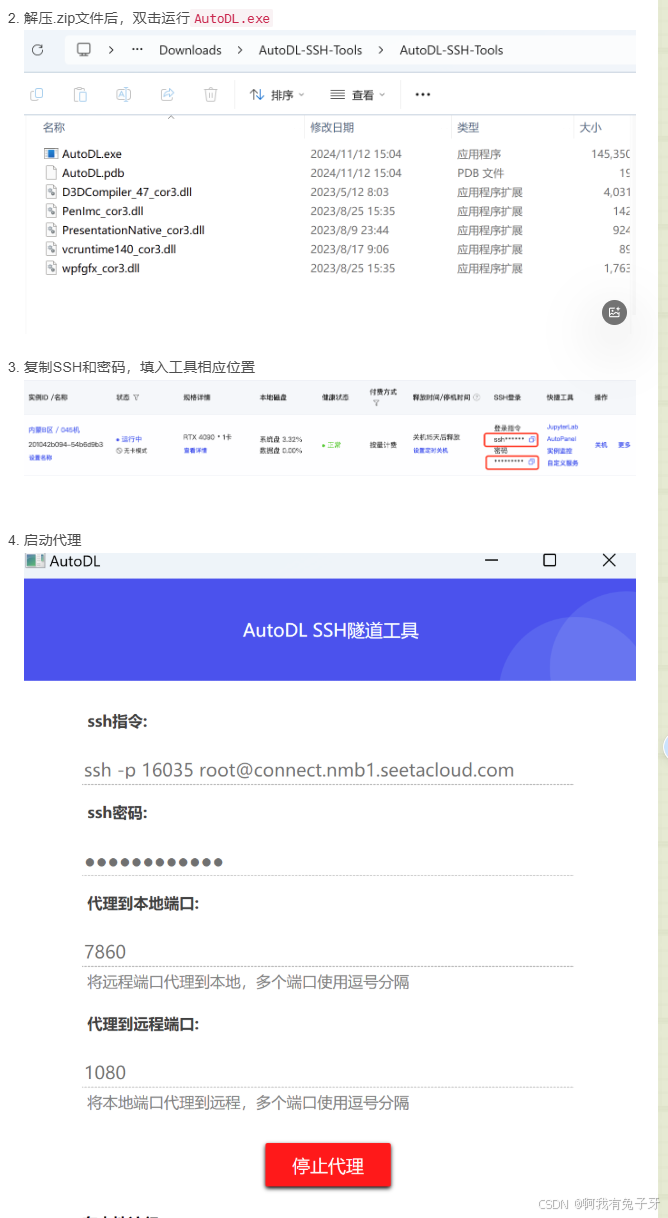
回到原来的目录 cd /root/autodl-tmp/LLaMA-Factory-main/
重新运行CUDA_VISIBLE_DEVICES=0 python src/webui.py,如下图所示会生成连接
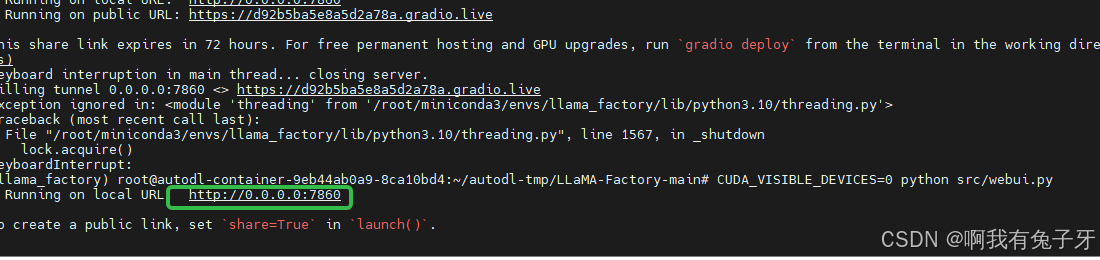
将连接复制到浏览器,发现lama-factory可以用了:
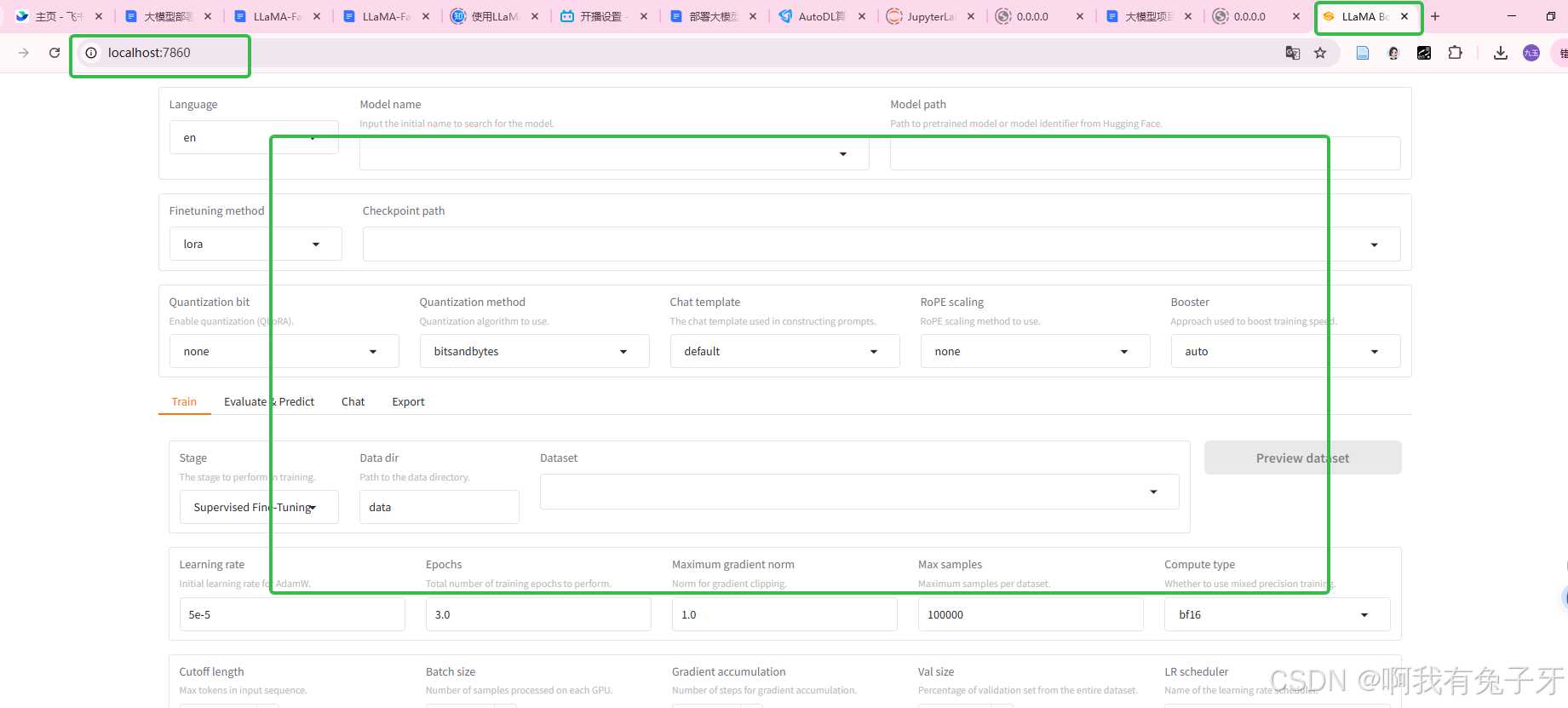
任务7 使用LLaMA-Factory测试微调前的模型能力
把无卡模式关了,现在要上硬菜了。
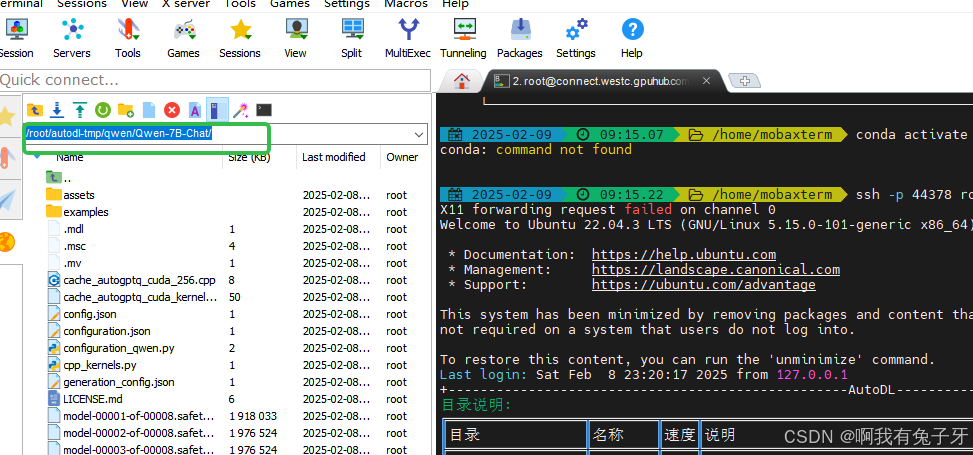
选择模型名称Qwen-7B-Chat,输入地址(之前下载的地方)/root/autodl-tmp/qwen/Qwen-7B-Chat,地址从MobaXterm复制,复制了记得删最后的/
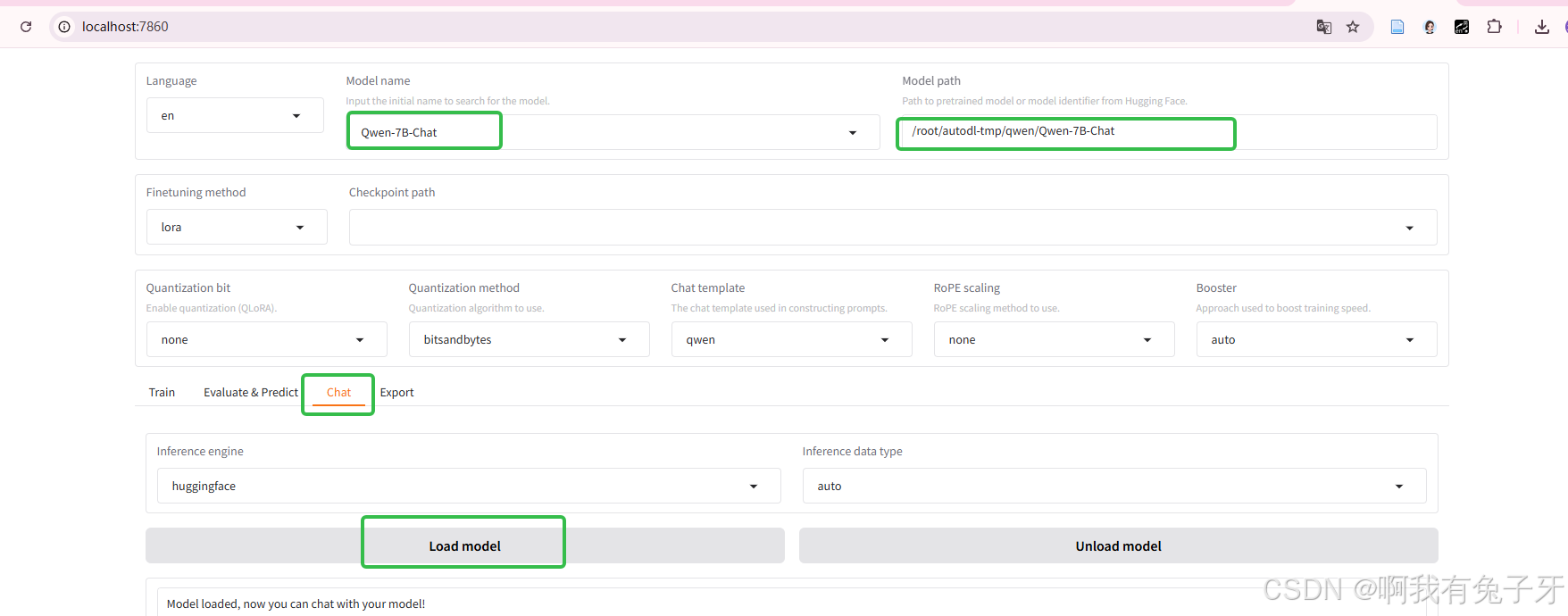
点击“chat”,点击加载模型,部署成功。如果没成功可能是你的无卡模式开机没切换过来
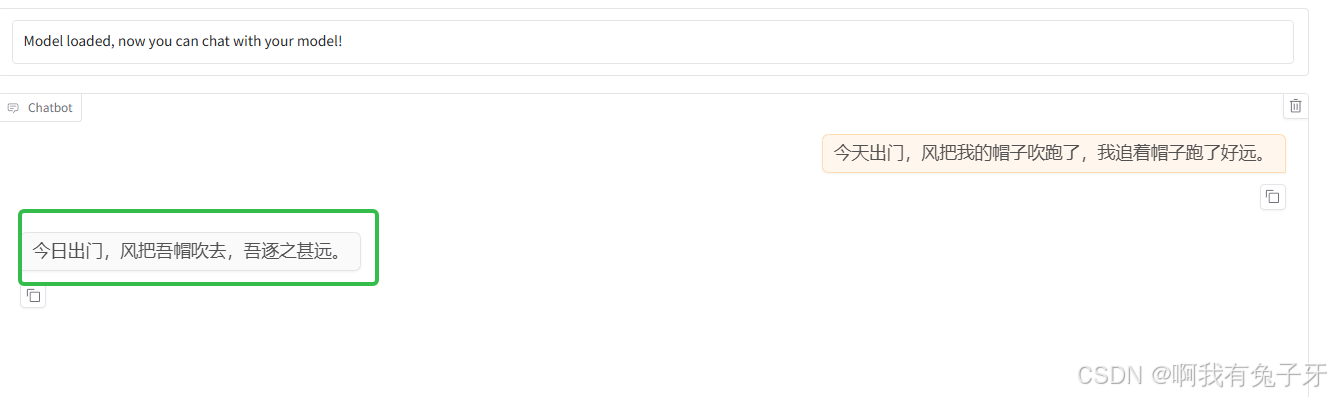
成功后可以测试一下大模型在微调前的表现,这里我想做个”请把现代汉语翻译成古文“的微调,所以测试一下原来模型翻译文言文的能力:
小剧场测试一下~:
今天出门,风把我的帽子吹跑了,我追着帽子跑了好远。
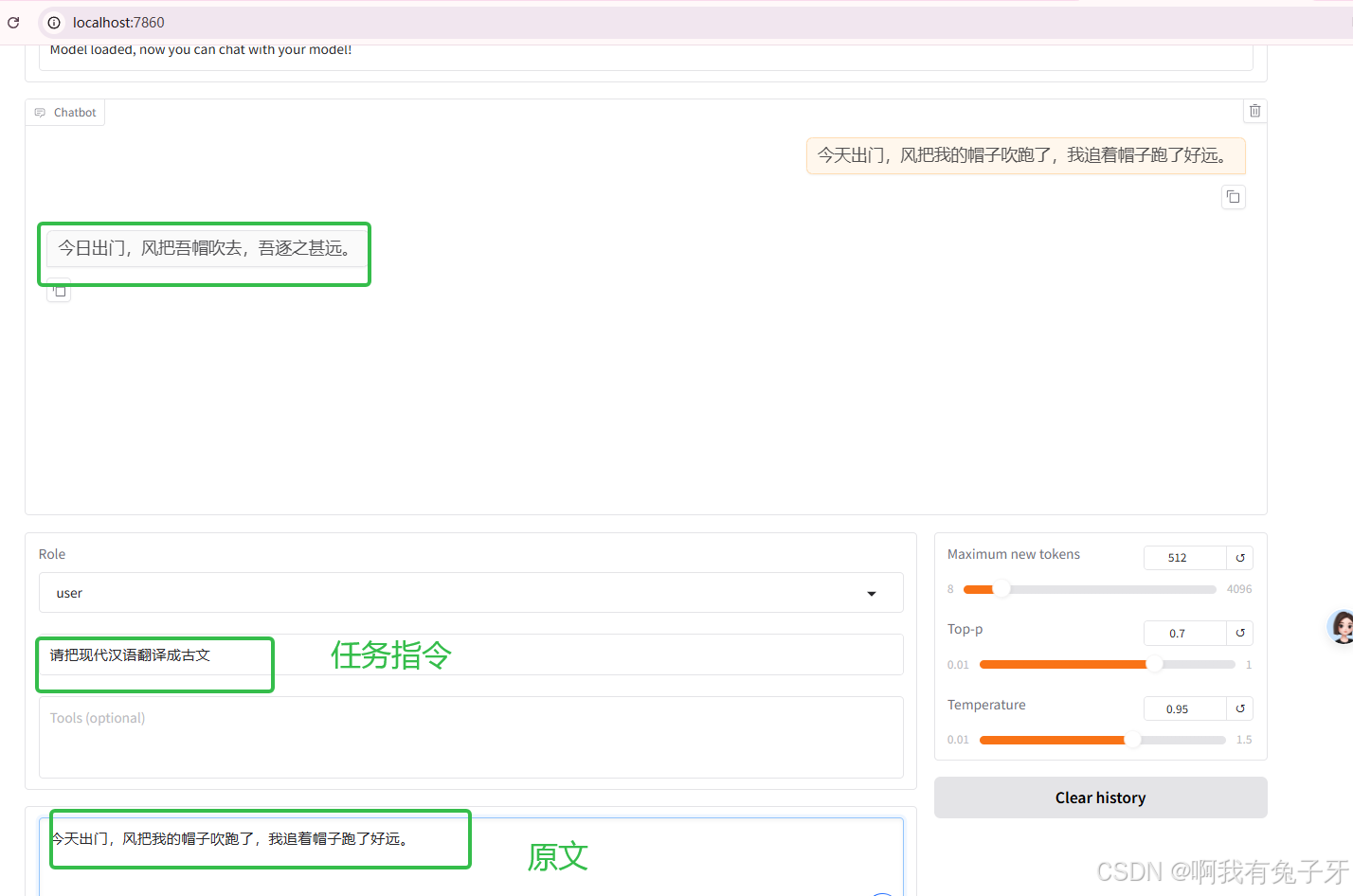
原来的大模型返回的结果如下,可以看到没有微调前的效果。
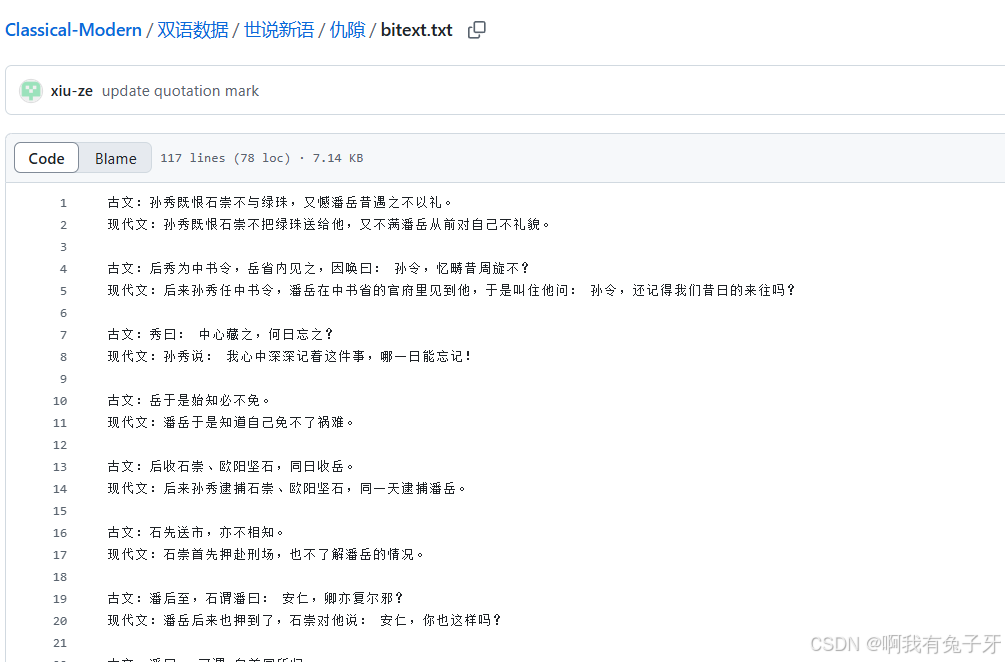
任务8 准备微调的文言文数据
初始的数据如下,文言文(古文)- 现代文平行语料: https://github.com/NiuTrans/Classical-Modern
有大量文言文原文和对照翻译,数据示例如下:
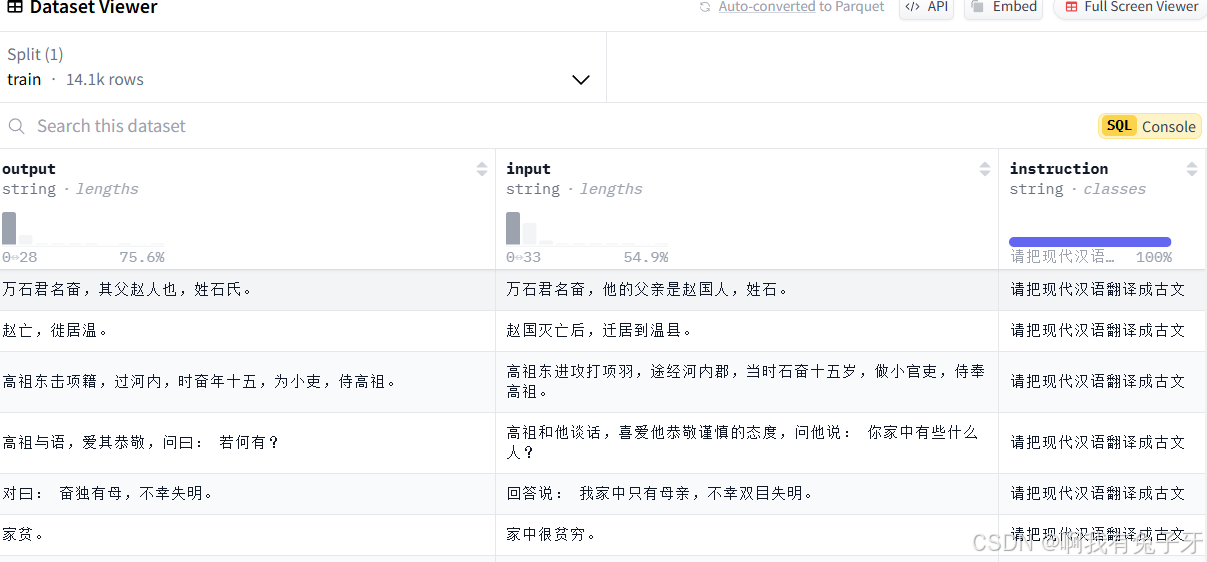
这里我们使用一下前辈们整理好的,使用上述数据中的《史记》七十列传文本数据做的微调训练数据集,实现现代文翻译至古文https://huggingface.co/datasets/AISPIN/shiji-70liezhuan,数据示例如下:
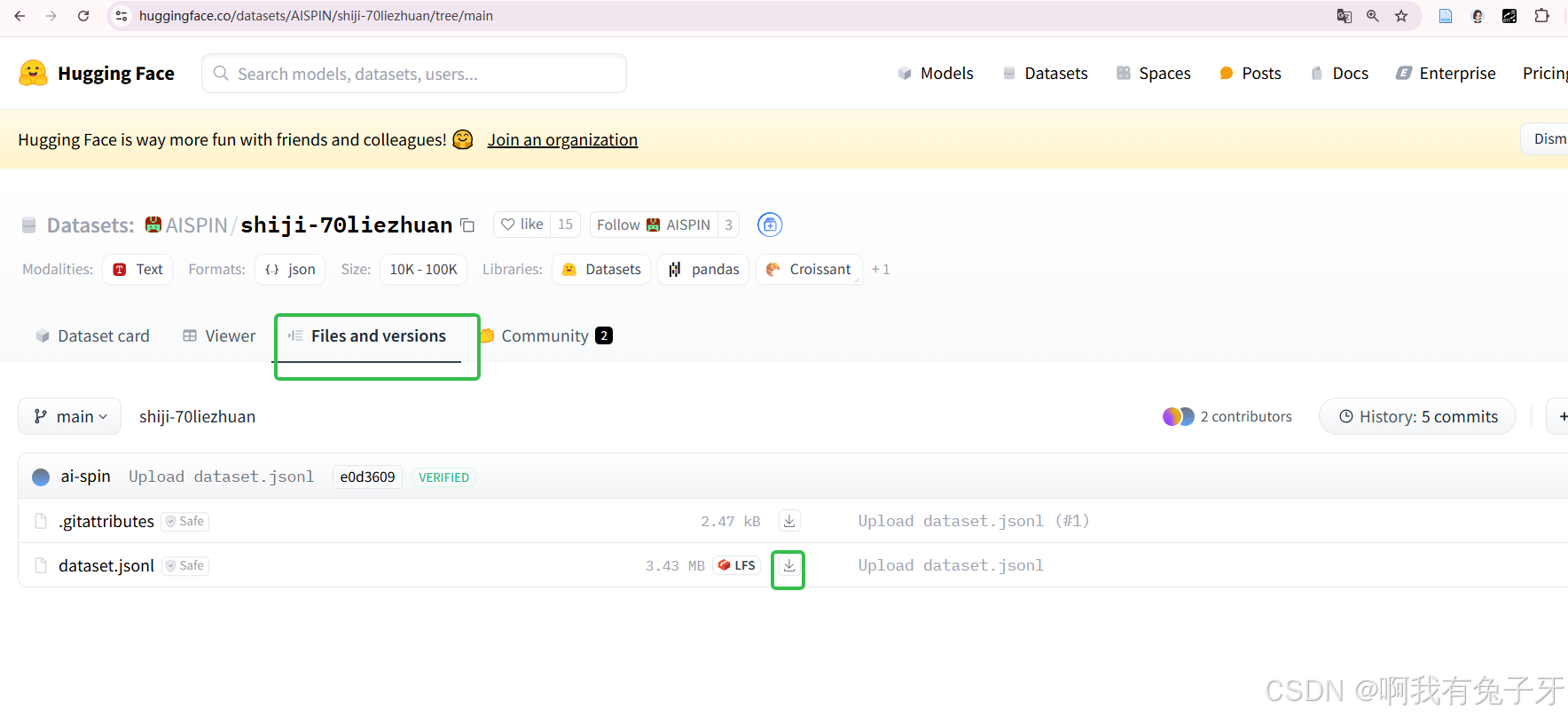
从这里下载:我们下载的数据集名字为dataset.jsonl
前辈使用的将原文数据转化目标数据的代码如下,鞠躬感谢:
'''
convert.py is a script that reads the content of the source and target files in the subfolders of the folder_path
and combines them into a dataset. The source file is the input field, and the target file is the output field.
Please refer to the youtube video for more details: https://youtu.be/Tq6qPw8EUVg
'''
import os
import json
import pandas as pd
folder_path = "双语数据\史记\七十列传"
# get all subfolders in the folder, then for each subfolder, get source file and target file,
# then read the content of the files then combine them into a dateset, the source file is the input field,
# the target file is the output field, and the target file is the output field
def get_files(folder_path):
subfolders = [f.path for f in os.scandir(folder_path) if f.is_dir()]
print(subfolders)
dataset = []
source_file = "source.txt"
target_file = "target.txt"
for x in subfolders:
with open(os.path.join(x,source_file) , "r", encoding="utf-8") as f:
source_content = f.read()
with open(os.path.join(x,target_file), "r", encoding="utf-8") as f:
target_content = f.read()
# source and target needs to be split by "\n"
source_content = source_content.split("\n")
target_content = target_content.split("\n")
# source and target should be saved into dateset line by line
for i in range(len(source_content)):
dataset.append([source_content[i], target_content[i]])
return dataset
dataset = get_files(folder_path)
# add one column "instruction" with the content "请把古文翻译成现代汉语" to the dataset
df = pd.DataFrame(dataset, columns=["source", "target"])
df["instruction"] = "请把现代汉语翻译成古文"
# rename the columns: source -> output, target -> input
df.rename(columns={"source": "output", "target": "input"}, inplace=True)
# print length of the dataset
print(len(df))
# save the dataset into a jsonl file
df.to_json("dataset.jsonl", orient="records", lines=True, force_ascii=False)注意,该项目目前支持两种格式的数据集:alpaca 和 sharegpt
我们在这里微调使用的是Alpaca 格式,因为前辈给的数据就是这个格式。下不了数据的可以到b站up主:啊我有兔子牙的工坊部分找到对应的项目资源包。
Alpaca 格式,标准格式如下:
[
{ # 标准格式
"instruction": "用户问题1",
"input": "",
"output": "模型回答1"
},
{ # 示例
"instruction": "你好",
"input": "",
"output": "您好,我是XX大模型,一个由XXX开发的 AI 助手,很高兴认识您。请问我能为您做些什么?"
}
]对于上述格式的数据,dataset_info.json 中的 columns 应为:
"数据集名称": {
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}其中 query 列对应的内容会与 prompt 列对应的内容拼接后作为用户指令,即用户指令为 prompt\nquery。response 列对应的内容为模型回答。
system 列对应的内容将被作为系统提示词。history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮的指令和回答。注意历史消息中的回答也会被用于训练。
对于预训练数据集,仅 prompt 列中的内容会用于模型训练。
对于偏好数据集,response 列应当是一个长度为 2 的字符串列表,排在前面的代表更优的回答,例如:
{
"instruction": "用户指令",
"input": "用户输入",
"output": [
"优质回答",
"劣质回答"
]
}总体来说Alpaca 格式的数据集格式
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)"
}
]对应的data_info.json的配置:
"filtered_train_data6": {
"file_name": "filtered_train_data6.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
Sharegpt 格式,标准格式如下:
[
{
"id": "qa_1", # 代表序号1,可改
"conversations": [
{
"from": "user",
"value": "用户指令1" # 用户问题1
},
{
"from": "assistant",
"value": "模型回答1" # 对应问题1的回答
}
],
"system": "系统提示词(选填)", # 可以不用管
},
{
"id": "qa_2",
"conversations": [
{
"from": "user",
"value": "用户指令2"
},
{
"from": "assistant",
"value": "模型回答2"
}
],
"system": "系统提示词(选填)",
}
]
任务9 使用LLaMA-Factory微调
将微调数据“dataset.jsonl”传入服务器LLaMA-Factory项目的data文件目录下
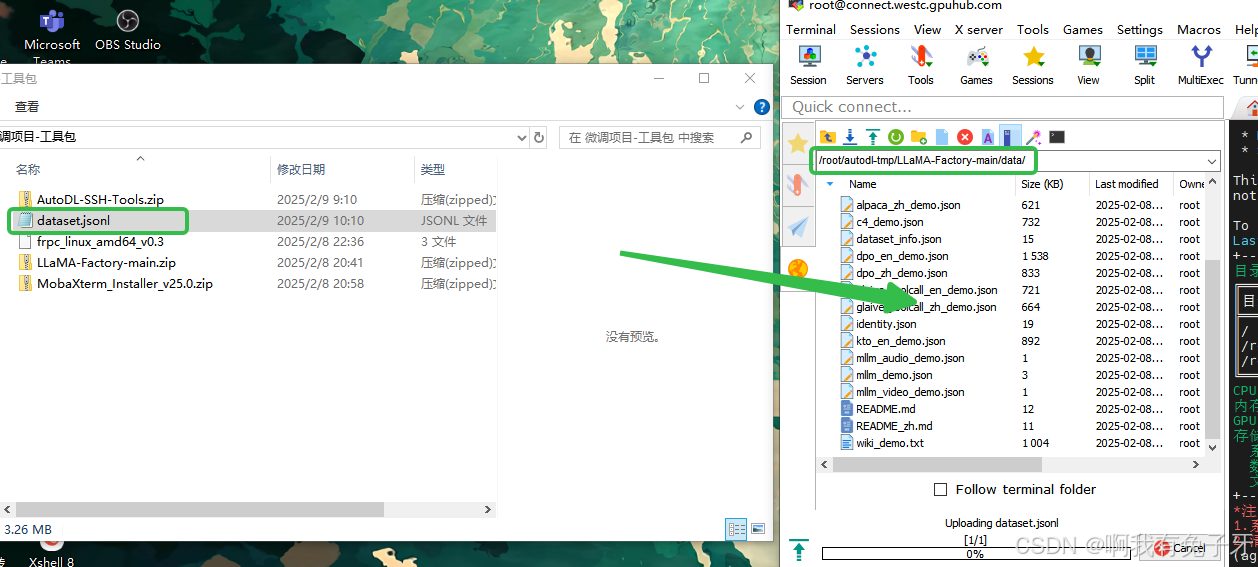
配置数据,在以下路径/root/autodl-tmp/LLaMA-Factory-main/data/找到箭头所指文件dataset_info.json
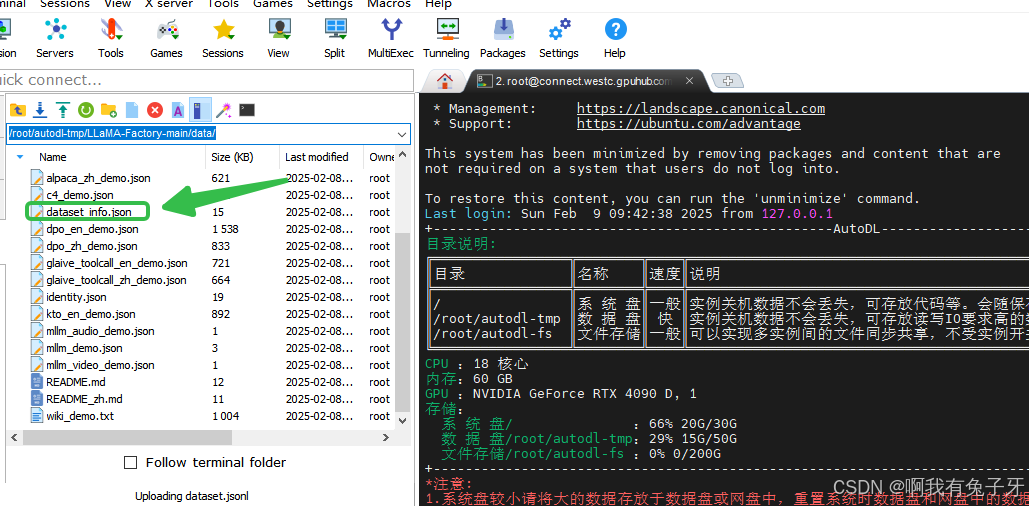
在文件末尾添加代码注意修改自己的文件路径,(注意添加逗号,且最后一个大括号要包含该项).然后点击保存
,
"train_myData": {
"file_name": "dataset.jsonl",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
其中“train_myData”是数据集的自定义名称,“file_name”是同文件夹路径下,数据集json的文件名
import hashlib
def calculate_sha1(file_path):
sha1 = hashlib.sha1()
try:
with open(file_path, 'rb') as file:
while True:
data = file.read(8192) # Read in chunks to handle large files
if not data:
break
sha1.update(data)
return sha1.hexdigest()
except FileNotFoundError:
return "File not found."
# 使用示例
file_path = r'C:\Users\12258\Desktop\xxx.json' # 替换为您的文件路径
sha1_hash = calculate_sha1(file_path)
print("SHA-1 Hash:", sha1_hash)数据集的配置就完成了。接下来正式开始微调。
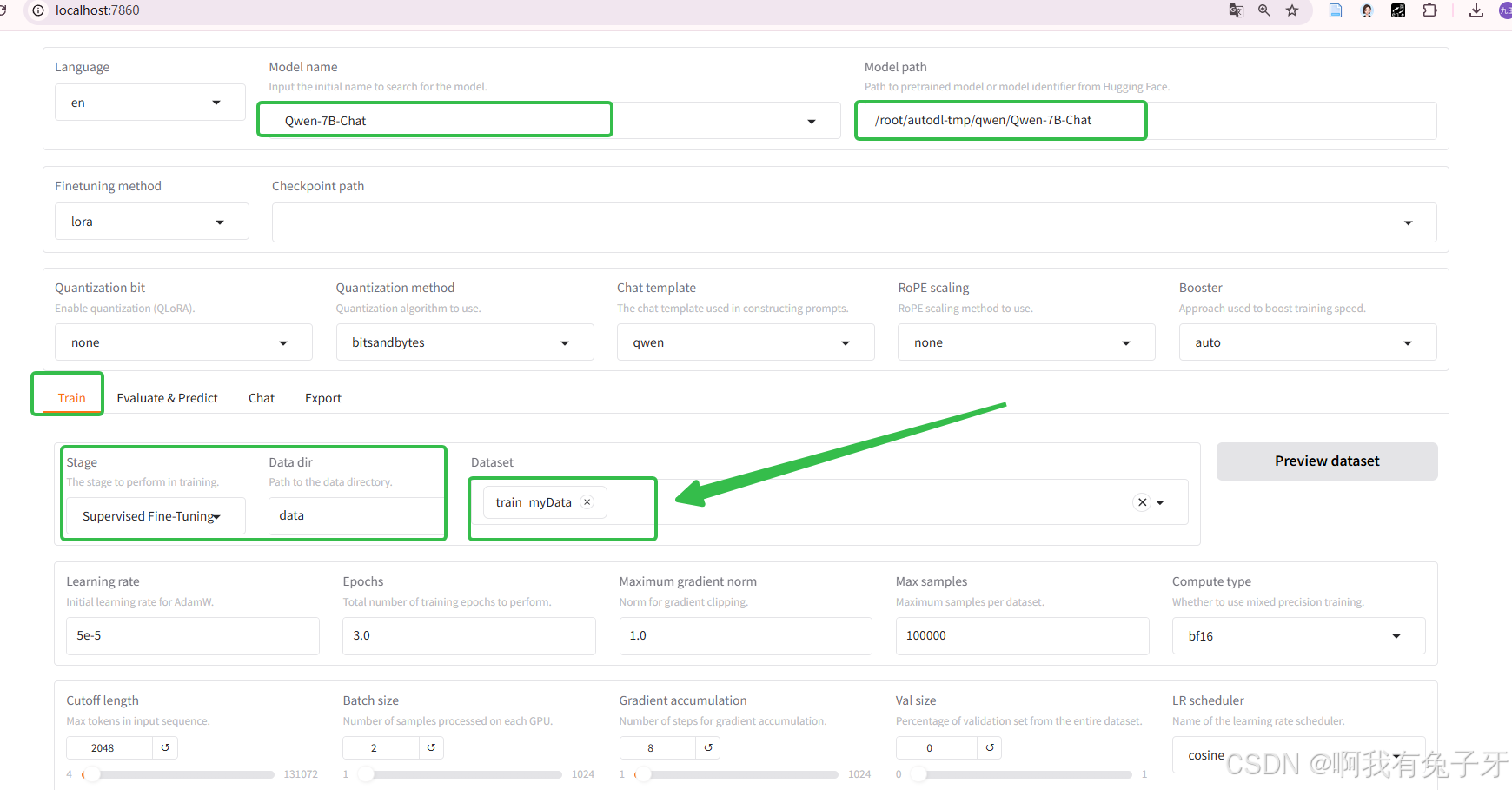
首先选择想要微调的模型,然后输入对应从魔搭社区下载来的模型路径,选择自己的数据集
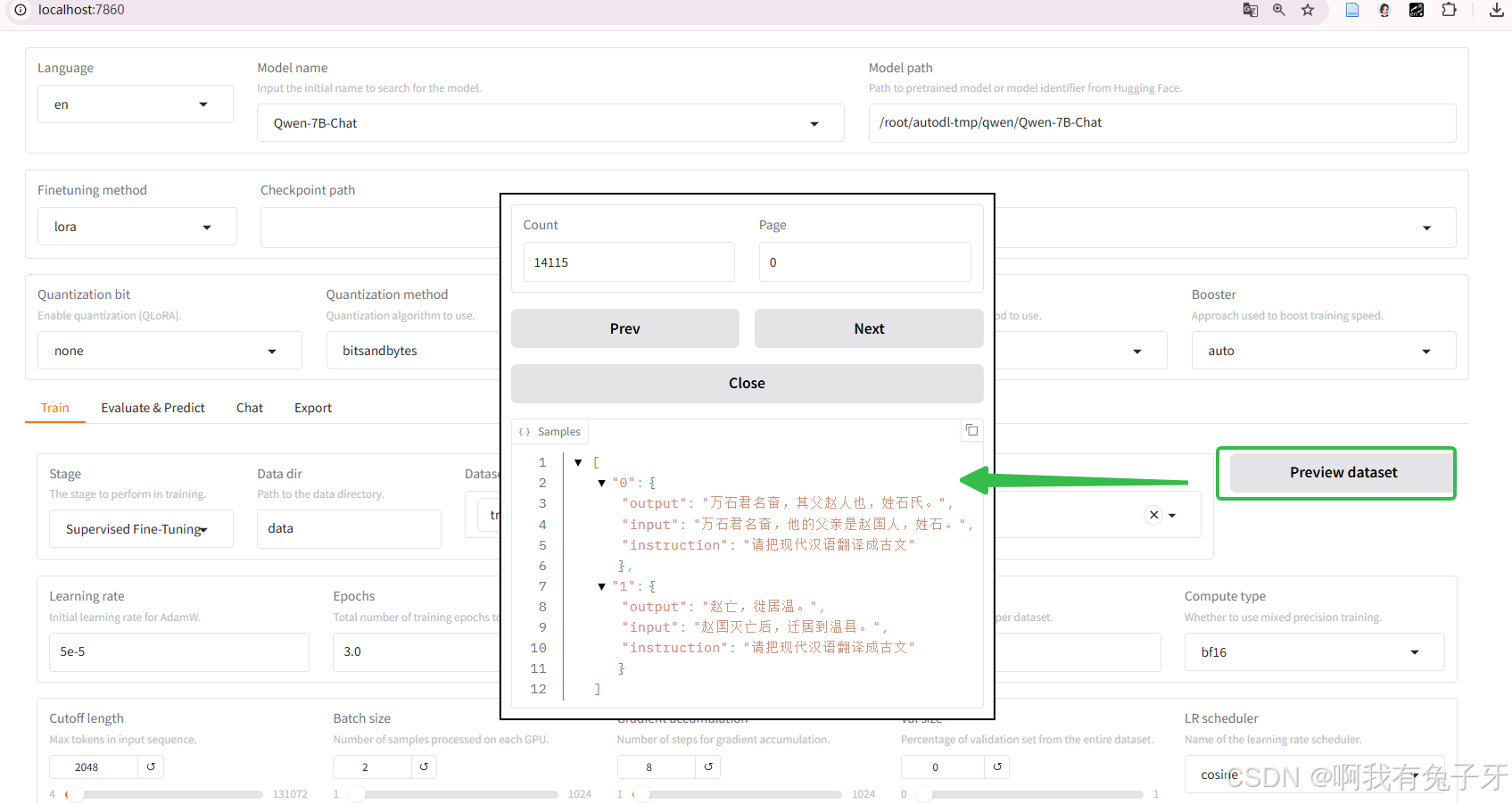
可以通过预览数据集查看自己的数据内容。能正常预览就说明数据没问题。那个框框回不去就刷新下
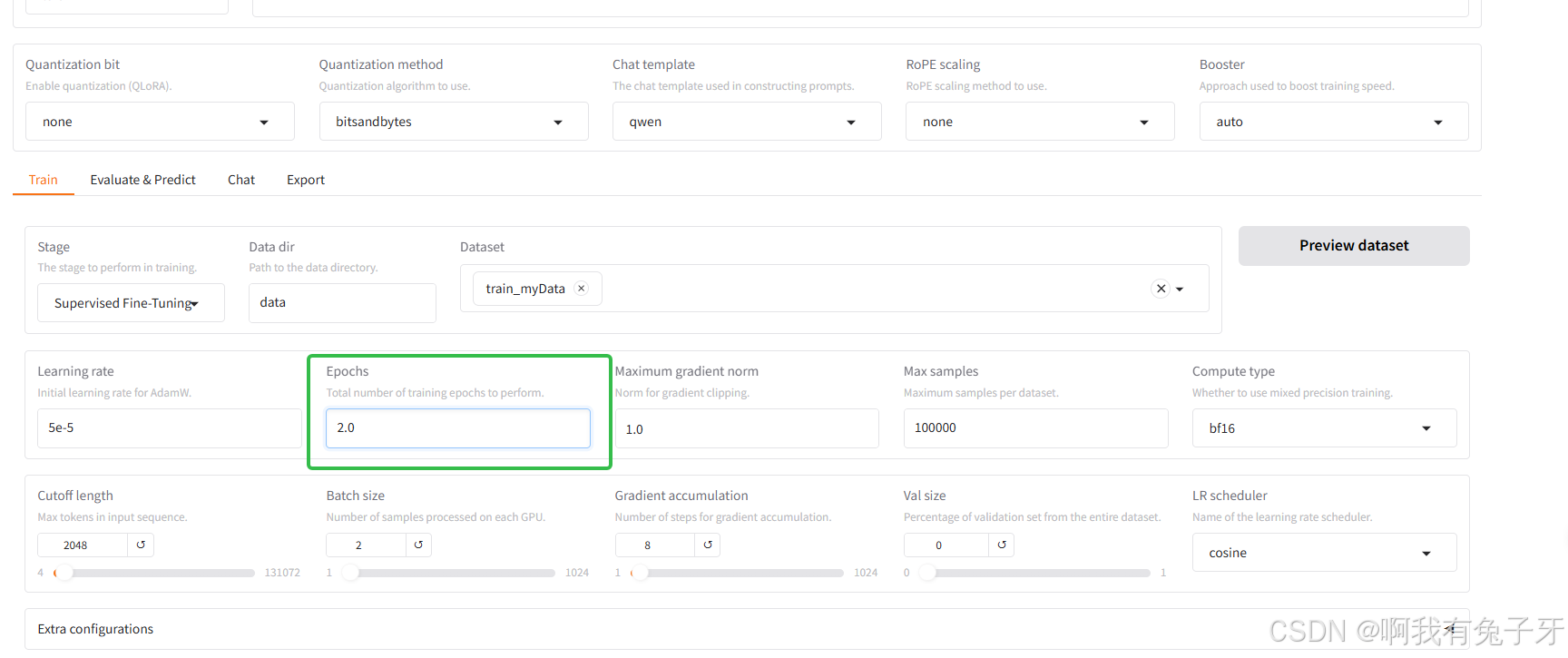
这里是一些参数,咱们数据比较多,训练2轮就行了
开始训练,底部会有日志刷新并可视化loss曲线,直至训练结束。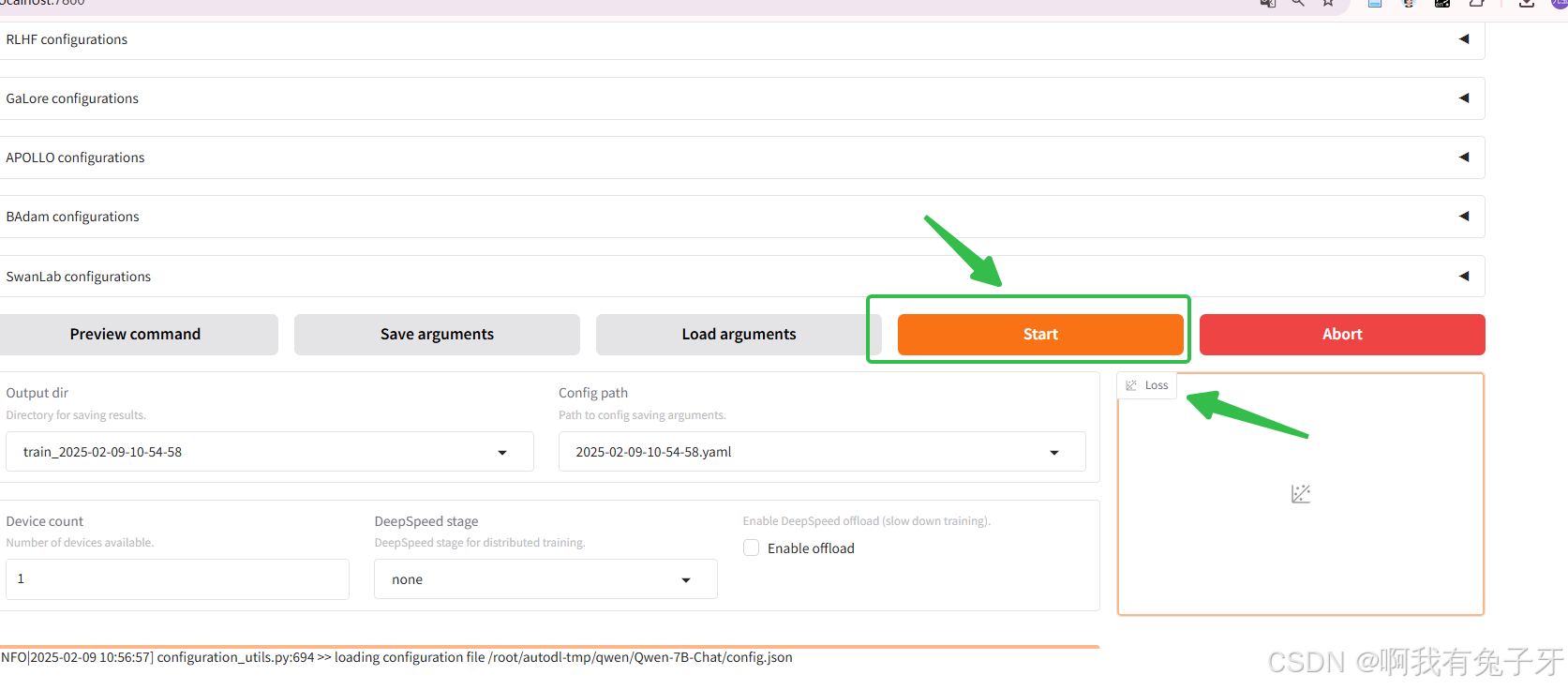
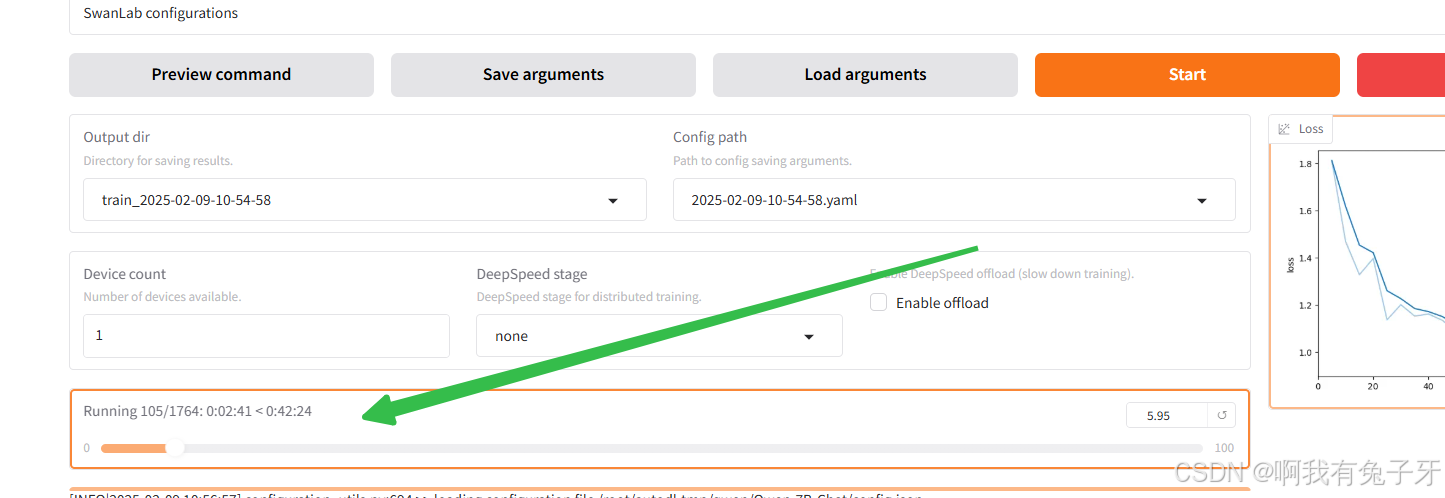
这里会显示训练的进度,上面说要40min左右,挂着服务器哈
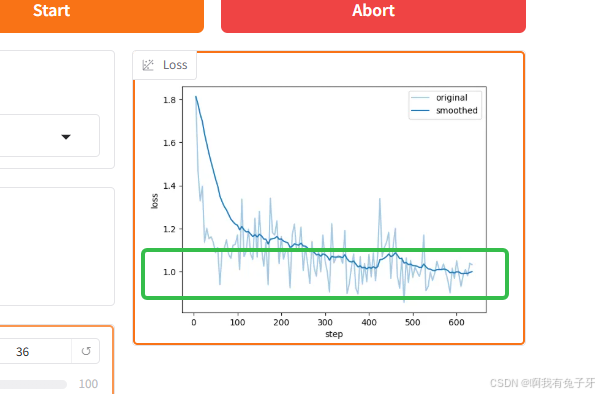
Loss越低说明你的训练效果越好
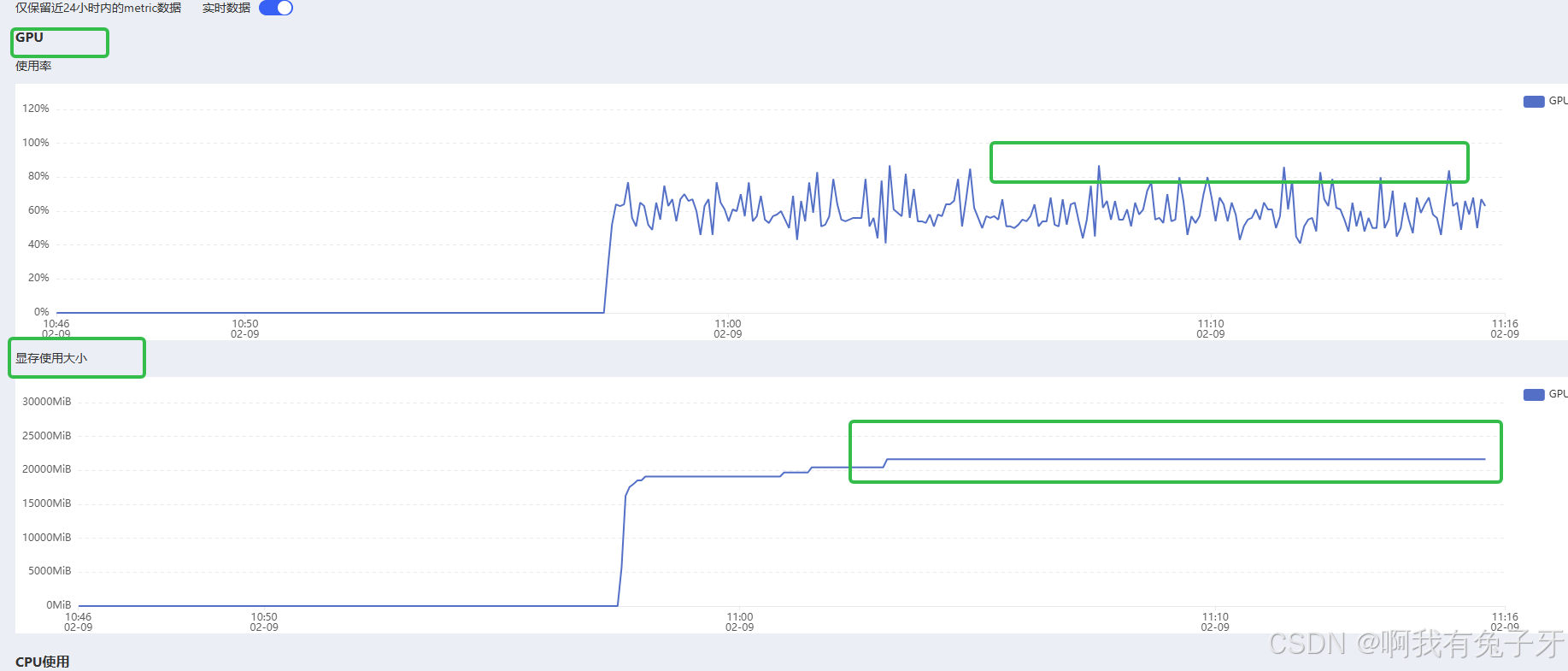
等待训练结束,如果你像我一样担心服务器会不会资源不够导致我的微调嘎了,可以看这里
gpu是负责运算的,显存是你计算的内存大小,都还够着呢,别担心。这也是咱为什么要租服务器的原因,咱们自己的电脑不仅对gpu和显存要求很高,还要配置很多镜像需要的环境,会浪费很多时间
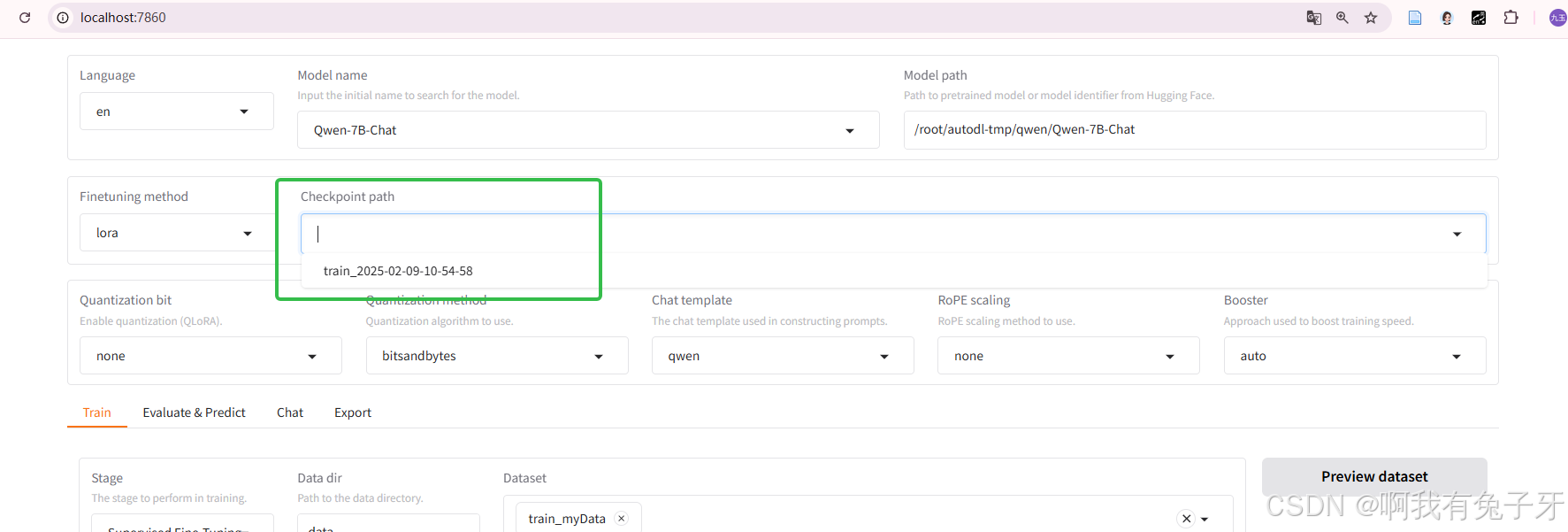
任务10 可以使用自己训练后的领域加强模型啦
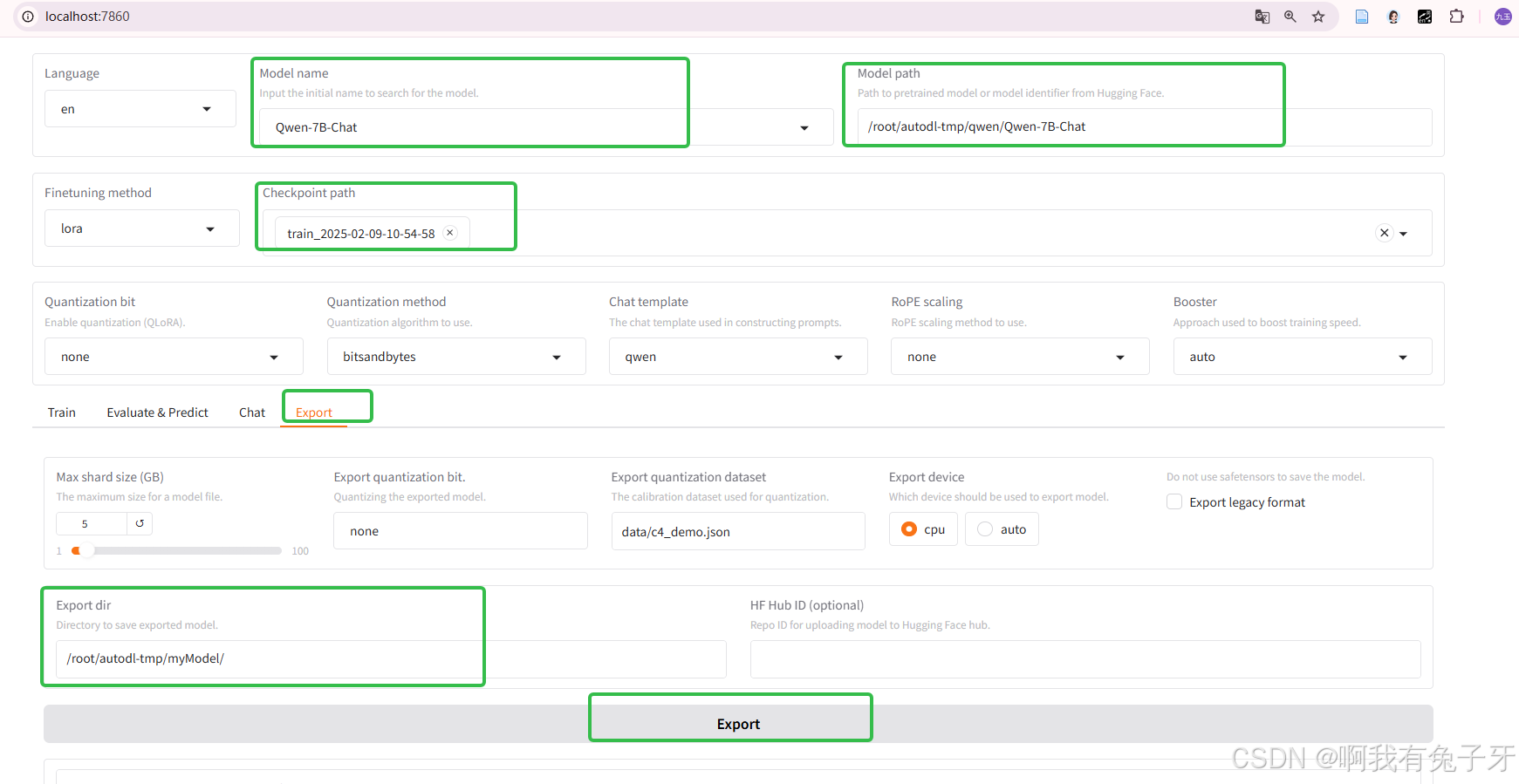
训练后模型权重文件可以在顶部的checkpoint path找到
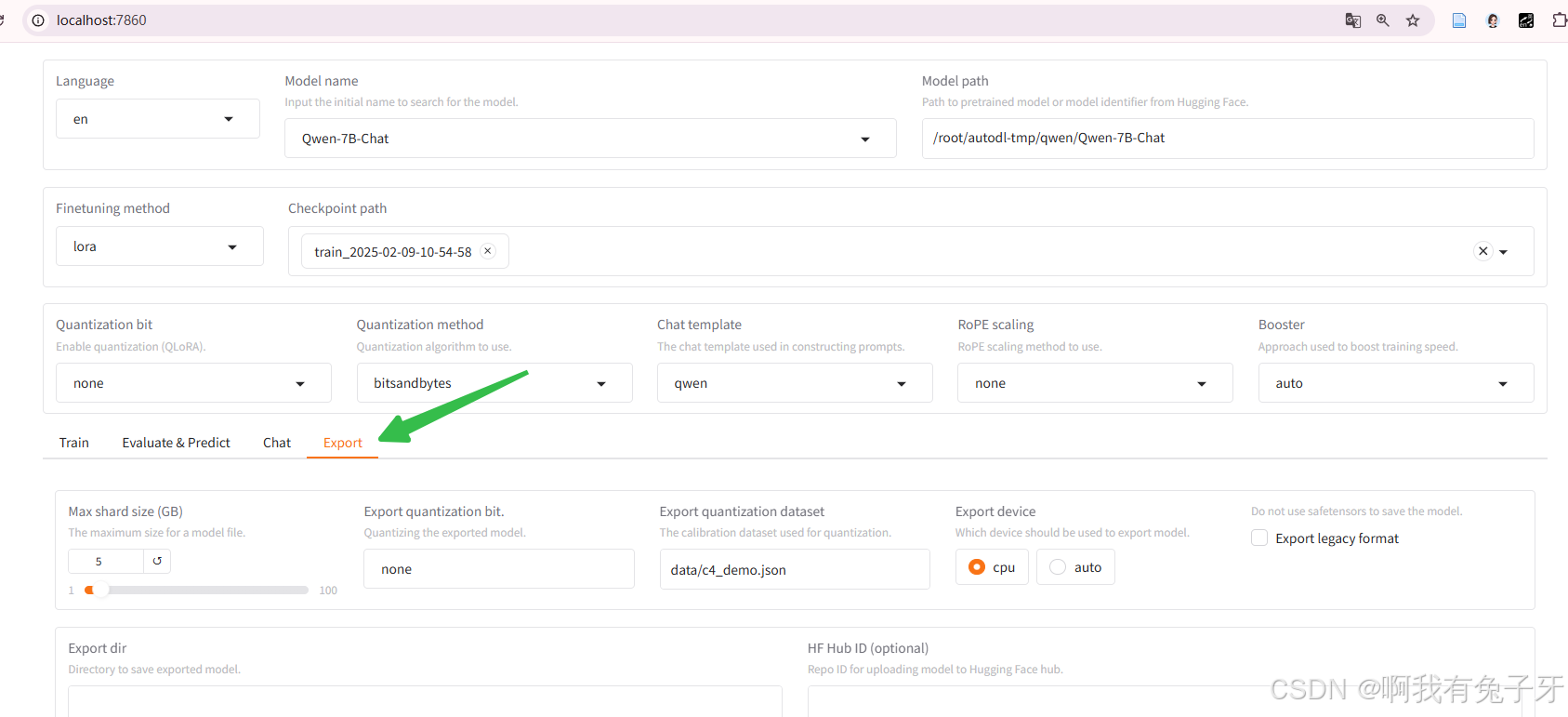
点击“Export”进入模型合并的操作界面
-
选择原来的模型及其路径、
-
选择训练后的权重文件
-
选择整合的新模型输出路径(这里我们记得放到AutoDL的数据盘autodl-tmp),我新建了一个myModel文件夹,路径为/root/autodl-tmp/myModel/
-

-
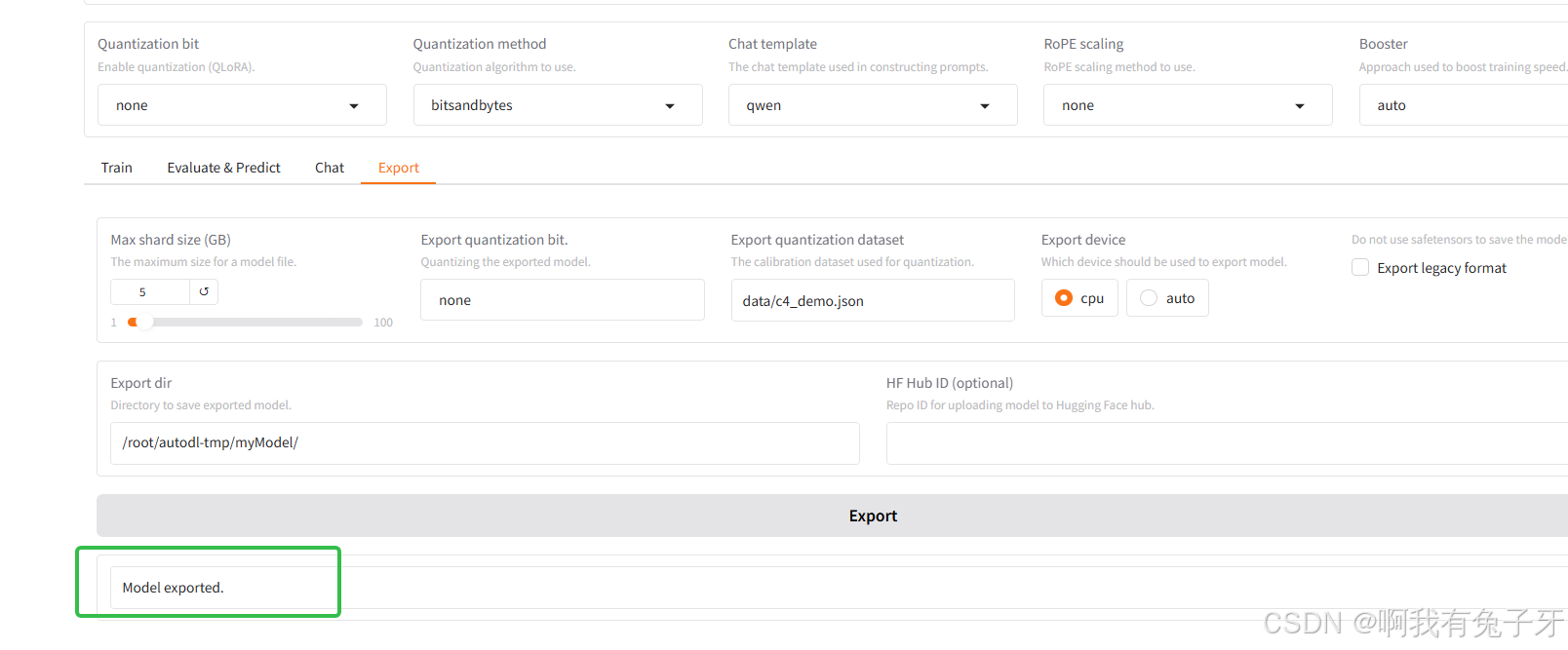
点击"Export"输出
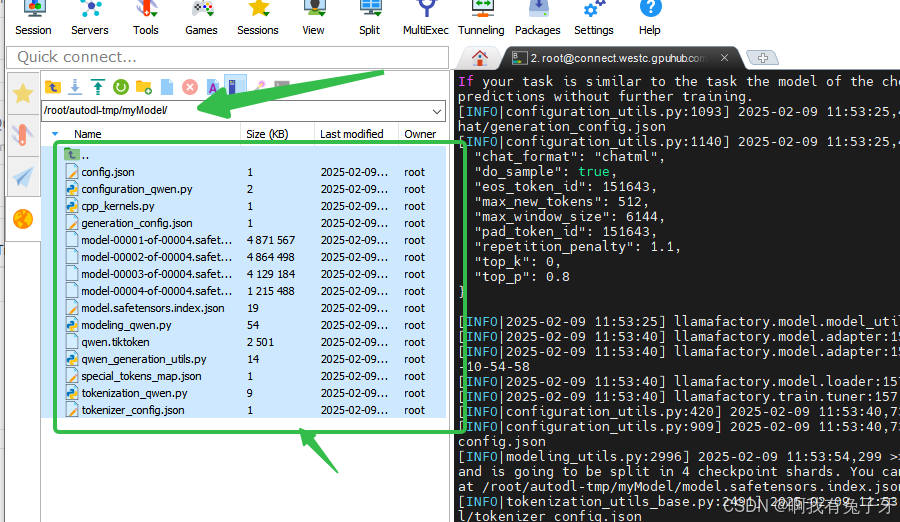
最后完成可以在mobaXterm中发现,在你的新模型输出路径中,微调后的新模型已经导出
回到lamafactory的界面,,方法同上述部署模型方法一致,把加载模型路径改为微调模型的输出路径就行了(就是上图的路径)/root/autodl-tmp/myModel,模型名字没变,因为它就是Qwen-7B-Chat的升级版,底层架构啥的都一样。chekpoint path清空一下
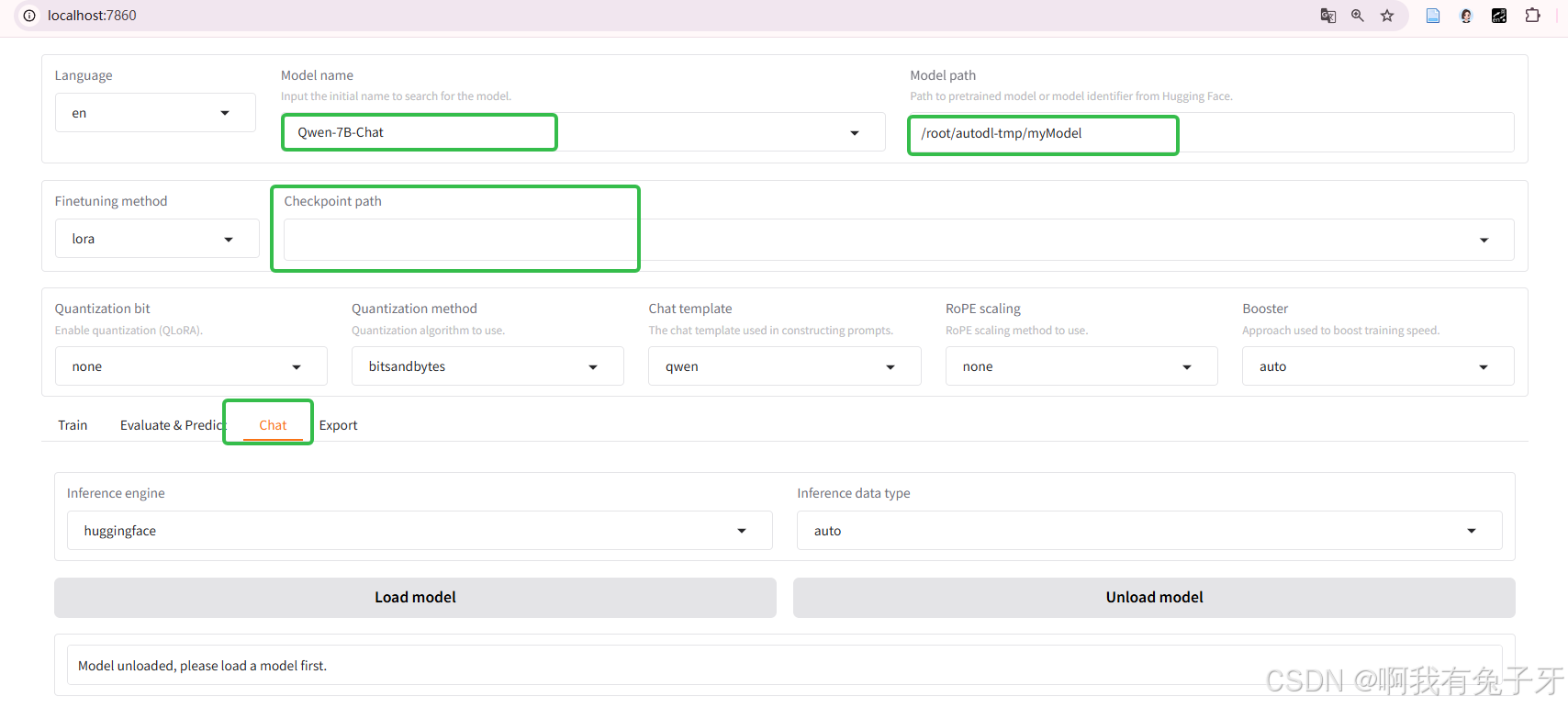
在chat部分测试模型的结果:
system prompt填”请把现代汉语翻译成古文“
小剧场测试一下~:
今天出门,风把我的帽子吹跑了,我追着帽子跑了好远。
原来的实验结果:
新的实验结果~是不是文言文的味道明显更重啦
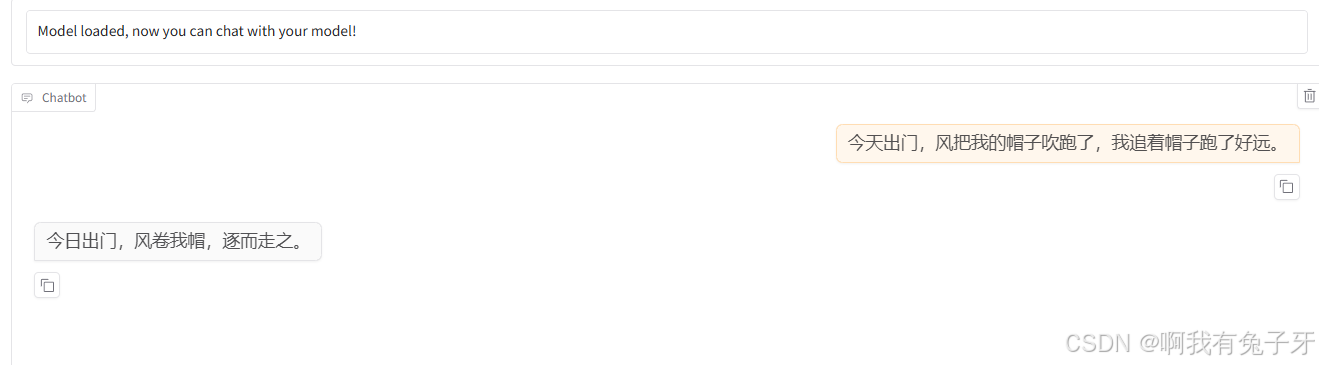
这里注意微调的数据集以短句为主,所以对于其它格式的文本表现可能不明显,甚至可能有倒退倾向,这就是微调的玄学之处了



















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









