







https://ojs.aaai.org/index.php/AAAI/article/view/27999
问题
如何使视觉语言模型(VLM)更有效地处理图像中的文本信息,提高在文本丰富的视觉问答(VQA)任务中的性能,同时在一般 VQA 任务中保持良好表现。
挑战
- 现有模型在解释图像中的文本时存在困难,尽管在基于图像的人机交互方面表现出一定能力,但难以准确解读图像中的文字内容1。
- 标准的从图像中提取信息的方法存在局限性,如使用固定数量的查询嵌入来压缩视觉信息,可能会因令牌数量限制而无法充分识别文本丰富场景中的上下文2。
- 在训练过程中,视觉编码器和语言模型(LLM)的协同训练面临挑战,如解冻视觉编码器可能导致灾难性遗忘先前知识,同时训练 LLM 不仅未带来改进,反而增加了训练复杂性3。
创新点
- 提出 BLIVA 模型,创新性地结合了学习查询嵌入和编码图像块嵌入,使模型能够捕捉到更丰富的图像细节,从而更有效地解释图像中的文本信息4。
- 采用了一种更紧凑的 0.5M 预训练字幕数据来训练视觉助手分支(编码图像块嵌入),相比其他模型使用的大量预训练数据(如 BLIP - 2 使用的 129M 预训练数据集),这是一种更高效的策略9。
贡献
- 提出 BLIVA 模型,为处理图像中的文本信息提供了更有效的方法,在文本丰富的 VQA 基准测试中性能显著提升(如在 OCR - VQA 基准测试中提升高达 17.76%)2。
- 实验证明 BLIVA 在一般 VQA 基准测试(如在视觉空间推理基准测试中提升高达 7.9%)和综合多模态 LLM 基准测试(MME)中也取得了出色的成绩(相比基线 InstructBLIP 总体提升 17.72%),展示了其在多种任务上的有效性21315。
- 通过引入新的 YouTube 缩略图数据集(YTTB - VQA)进行评估,证明了模型在实际应用中的广泛适用性,为模型在现实场景中的应用提供了支持10。
提出的方法
- 模型架构
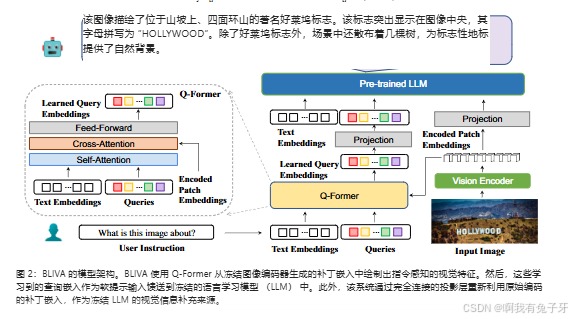
- BLIVA 模型结合了视觉塔、Q - Former、LLM 等组件。视觉塔将输入图像编码为编码图像块嵌入,一部分通过 Q - Former 提取学习查询嵌入,另一部分经过投影层后与学习查询嵌入连接,作为最终输入提供给冻结的 LLM。在推理时,采用束搜索选择最佳生成输出;对于分类和多选 VQA 基准测试,使用词汇排名方法56。
- 两阶段训练方案
- 预训练阶段:使用图像字幕数据集的图像 - 文本对,使 LLM 熟悉视觉嵌入空间。此阶段视觉编码器和 LLM 均保持冻结状态7。
- 指令调整阶段:利用指令调整数据进一步优化模型,使视觉嵌入与 LLM 和人类价值观更好地对齐,同时保持视觉编码器和 LLM 的冻结状态8。
指标
- 在文本丰富的 VQA 基准测试中,使用 OCR - VQA、Text - VQA 等数据集的准确率作为评估指标。
- 对于一般 VQA 基准测试,根据不同数据集的特点采用相应指标,如 Flickr30K 数据集使用 CIDEr 分数、Hateful Memes 数据集使用 AUC 分数、Visual Dialog 数据集使用 Mean Reciprocal Rank(MRR),其他数据集使用 top - 1 准确率14。
- 在 MME 基准测试中,评估模型在感知和认知任务的各个子任务上的表现,包括存在性(Existence)、计数(Count)、位置(Position)、颜色(Color)、OCR、海报(Poster)、名人(Celebrity)、场景(Scene)、地标(Landmark)、艺术作品(Artwork)、常识推理(Commonsense Reasoning)、数值计算(Numerical Calculation)、文本翻译(Text Translation)和代码推理(Code Reasoning)等16。
模型结构
- 视觉塔:对输入图像进行编码,生成编码图像块嵌入。
- Q - Former:用于从编码图像块嵌入中提取学习查询嵌入,这些查询嵌入将作为软提示输入到 LLM 中。
- LLM:接收来自 Q - Former 的学习查询嵌入以及经过投影层处理后的编码图像块嵌入,进行文本生成或回答问题。
- 投影层:将编码图像块嵌入通过全连接投影层进行处理,使其能够作为补充的视觉信息输入到 LLM 中5。
结论
- BLIVA 模型通过结合学习查询嵌入和编码图像块嵌入的设计,在文本丰富和一般 VQA 基准测试中均取得了显著的性能提升,在 MME 基准测试中也表现出色,展示了其在多模态任务中的有效性21315。
- 在实际应用中,如对 YouTube 缩略图的识别任务,BLIVA 模型也展现了良好的能力,能够从图像中提取额外的视觉信息17。
- 模型在解读图像中的数字符号方面存在困难,这可能是由于数字符号在图像中常以减少的像素表示所致,需要未来进一步研究18。
剩余挑战和未来工作
- 剩余挑战
- 模型在解读图像中的数字符号方面存在困难,可能是因为数字符号在图像中的像素表示方式导致信息丢失,影响了模型的识别能力18。
- 未来工作
- 探索如何改进模型对数字符号的识别能力,进一步提高模型在处理图像文本信息时的准确性18。
- 研究如何将更多类型的视觉嵌入有效地扩展到 LLM 中,以推动大视觉语言模型的发展18。
数据集
- 训练数据集
- 由于 LAION - 115M 数据集存在非法内容无法安全下载,使用了 MSCOCO(用于图像字幕)、TextCaps、VQAv2、OKVQA、A - OKVQA、OCR - VQA、LLaVA - Instruct150K 等数据集进行训练。同时,为了训练编码图像块嵌入的投影层,使用了由 LLaVA 过滤后的 558K 图像 - 文本对(来自 LAION、CC3M 和 SBU 数据集,并由 BLIP 进行字幕标注)1112。
- 评估数据集
- 包括 Flickr30K、VSR、IconQA、TextVQA、Visual Dialog、Hateful Memes、VizWiz、MSRVTT QA 等数据集。在一些数据集(如 Text - VQA)的评估中,遵循 InstructBLIP 的方法使用 OCR - 令牌进行比较11。
- 新引入数据集(YTTB - VQA)
- 为展示模型在实际应用中的能力,引入了 YTTB - VQA 数据集,该数据集包含 400 对 YouTube 缩略图视觉问答对,涵盖 11 个不同类别。数据收集过程包括随机选择带有文本丰富缩略图的 YouTube 视频,获取高分辨率缩略图,并创建包含视频 ID、问题、视频类别、答案和视频链接等字段的注释文件10。
抽象
视觉语言模型(VLMs)通过纳入视觉理解能力扩展了大型语言模型(LLM),在解决开放式视觉问答(VQA)任务方面取得了重大进展。然而,这些模型无法准确解释包含文本的图像,而这在现实世界场景中很常见。从图像中提取信息的标准程序通常涉及学习一组固定的查询嵌入。这些嵌入旨在封装图像上下文,随后用作 LLM 中的软提示输入。然而,这个过程受到标记数量的限制,可能会限制对具有丰富文本上下文的场景的识别。为了改进它们,本研究引入了 BLIVA:带有视觉助手的 InstructBLIP 的增强版本。BLIVA 结合了 InstructBLIP 的查询嵌入,并将编码的补丁嵌入直接投影到 LLM 中,这一技术受到 LLaVA 的启发。这种方法帮助模型捕获在查询解码过程中可能错过的复杂细节。经验证据表明,我们的模型 BLIVA 在处理富含文本的 VQA 基准测试(在 OCR-VQA 基准测试中高达 17.76%)和进行一般(不是特别富含文本)的 VQA 基准测试(在视觉空间推理基准测试中高达 7.9%)方面显著提高了性能,并且与我们的基线 InstructBLIP 相比,在综合多模态 LLM 基准测试(MME)中实现了 17.72% 的整体改进。BLIVA 在解码现实世界图像方面表现出显著能力,无论是否存在文本。为了展示 BLIVA 实现的广泛行业应用,我们使用一个新的数据集评估该模型,该数据集由 YouTube 缩略图与涵盖 11 个不同类别的问答集配对组成。对于有兴趣进一步探索的研究人员,我们的代码和模型可在 GitHub - mlpc-ucsd/BLIVA: (AAAI 2024) BLIVA: A Simple Multimodal LLM for Better Handling of Text-rich Visual Questions 免费获取。
介绍
最近,大型语言模型 (LLM) 改变了自然语言理解领域,在零样本和少样本设置中展示了在广泛任务中泛化的令人印象深刻的能力。这一成功主要归功于指令调优(Wuet al. 2023),它通过将各种任务构建为指令来提高对看不见任务的泛化。视觉语言模型 (VLM),例如 OpenAI 的 GPT-4 (OpenAI 2023),将 LLM 与视觉理解功能相结合,在解决开放式视觉问答 (VQA) 任务方面取得了重大进步。已经提出了几种通过直接与视觉编码器的补丁特征对齐(Liu 等人,2023a)或通过固定数量的查询嵌入提取图像信息(Li 等人,2023b;Zhu 等人,2023)在视觉相关任务上使用大型语言模型的方法。
然而,尽管这些模型在基于图像的人机交互方面表现出相当大的能力,但在解释图像中的文本方面却存在困难。带有文字的图像在我们的日常生活中无处不在,理解这些内容对于人类的视觉感知至关重要。以前的工作使用带有查询嵌入的抽象模块,限制了它们在图像中文本细节的能力(Li 等人,2023b;Awadalla 等人,2023 年;Ye et al. 2023)。
在我们的工作中,我们利用编码的补丁嵌入,将学习到的查询嵌入与额外的视觉助手分支结合使用。这种方法解决了通常提供给语言模型的约束图像信息,从而改善了文本图像的视觉感知和理解。从实证上讲,我们根据 (Dai et al. 2023) 的评估数据集和来自 (Liu et al. 2023b) 的富文本图像评估协议,报告了我们的模型的一般(不是特别文本丰富的)VQA 基准的结果。我们的模型是从预先训练的 InstructBLIP 和从头开始训练的编码补丁投影层初始化的。遵循(Zhu 等人,2023 年;Liu et al. 2023a),我们进一步展示了一个两阶段的训练范式。我们首先预训练 patch embeddings 投影层。随后,利用指令调优数据,我们对 Q -former 和 patch embeddings 投影层进行了微调。在此阶段,我们将图像编码器和 LLM 都保持在冻结状态。我们基于实验的两个发现采用这种方法:首先,解冻视觉编码器会导致对先验知识的灾难性遗忘;其次,同时培训 LLM 并没有带来改进,但带来了显着的培训复杂性。
总之,我们的研究包括以下亮点:
・我们介绍了 BLIVA,它利用了学习到的查询入向量和编码的补丁嵌入向量,为解释图像中的文本提供了一种有效的方法。
・我们的实验结果表明,BLIVA 在理解图像中文本方面提供了改进,同时在一般(不是特别丰富的文本)VQA 基准测试中保持了稳健的性能,并在以前的方法中实现了 MME 基准测试的最佳性能。
・为了强调 BLIVA 在现实世界中的适用性,我们使用新的 YouTube 缩略图数据集和相关问答对来评估该模型。
相关工作
多模态大型语言模型
大型语言模型 (LLM) 在各种开放式任务中表现出令人印象深刻的零镜头能力。最近的研究探索了 LLM 在多模态生成中的应用,以理解视觉输入。一些方法利用预先训练的 LLM 来构建多模态的统一模型。例如,Flamingo (Alayrac et al. 2022) 通过 Perceiver Resampler 连接视觉编码器和 LLM,该采样器表现出令人印象深刻的小样本性能。此外,BLIP-2 (Li et al. 2023b) 设计了一个 Q 成型器,以使视觉特征与 OPT (Zhang et al. 2022) 和 FLAN-T5 (Wei et al. 2021) 保持一致。MiniGPT-4(Zhu 等人,2023 年)采用了相同的 Q 成型器,但将 LLM 更改为 Vicuna(Zheng 等人,2023 年)。一些方法还对 LLM 进行了微调,以便更好地与视觉特征对齐,例如 LLaVA(Liu 等人,2023a)直接微调 LLM 和 mPLUG-Owl(Ye 等人,2023 年)执行低秩适应 (LoRA)(胡 等人,2022 年)以微调 LLaMA 模型(Touvron 等人,2023 年)。PandaGPT(Su 等人,2023 年)
还使用 LoRA 在 ImageBind 之上微调 Vicuna 模型(Girdhar 等人,2023 年),该模型可以接受除视觉之外的多模态输入。在共享相同的两阶段训练范式的同时,我们专注于为文本丰富的 VQA 基准测试和通用 VQA 基准测试开发端到端多模态模型。
多模态指令调优
指令调优已被证明可以提高语言模型对看不见的任务的泛化性能。在自然语言处理 (NLP) 社区中,一些方法通过将现有的 NLP 数据集转换为指令格式来收集指令调整数据(Wang 等人,2022b;Wei 等人,2021 年;Sanh 等人,2022 年;Chung 等人,2022 年),其他人使用 LLM 生成指令数据(Taori 等人,2023 年;Zheng 等人,2023 年;Wang 等人,2023 年;Honovich 等人,2022 年)。最近的研究将指令调整扩展到多模态设置。特别是,对于基于图像的指令调整,MiniGPT-4 (Zhu et al. 2023) 在微调阶段采用人工策划的指令数据。LLaVA (Liu et al. 2023a) 通过提示带有图像标题和边界框坐标的 GPT-4 (OpenAI 2023) 生成 156K 多模态指令跟踪数据。mPLUG-Owl (Ye et al. 2023) 还使用仅 400K 混合文本和多模态指令数据进行微调。指令调优还增强了以前的 Vision Language Foundation 模型的性能。例如,MultimodalGPT (Gong et al. 2023) 设计了各种指令模板,这些模板结合了视觉和语言数据,用于多模态教学调整 OpenFlamingo(Awadalla et al. 2023)。(Xu, Shen, and Huang 2023) 构建了一个多模态指令调优基准数据集,该数据集由 62 个不同的多模态任务组成,采用统一的 seq-to-seq 格式,并进行了微调的 OFA(Wang MIMIC-IT(Li et al.2023a)构建了一个包含 280 万多模态指令响应对的更大数据集,以训练更强的模型 Otter(Li et al.2023a)。我们还使用了与 InstructBLIP 相同提示的指令调整数据(戴等人 2023)来证明利用额外编码补丁嵌入的有效性。
方法
架构概述
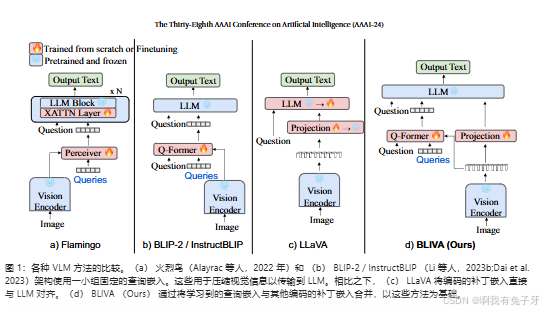
如图 1 所示,主要有两种类型的端到端多模态 LLM:1)为 LLM 使用学习查询嵌入的模型。例如,MiniGPT-4(Li et al.2023)使用来自 BLIP2(Li et al.2023b)的冻结 Q - 形成器模块通过查询 CLIP 视觉编码器来提取图像特征。Flamingo(Alayrac et al.2022)使用 Percader Respler,它将图像特征减少到 LLM 的固定数量的视觉输出。2)直接使用图像编码的补丁嵌入的模型,例如 LLaVA(Liu et al.2023a),它使用 MLP 将其视觉编码器连接到 LLM。然而,这些模型表现出某些约束。一些模型为 LLM 使用学习查询嵌入,这有助于更好地理解视觉编码器,但可能会错过编码补丁嵌入的关键信息。另一方面,一些模型通过线性投影层直接使用编码图像块嵌入,这可能在捕获 LLM 所需的所有信息方面的能力有限。
为了解决这个问题,我们引入了 BLIVA,这是一种多模态 LLM,旨在结合学习的查询嵌入 -
它们与 LLM 更紧密地对齐 —— 以及携带更丰富图像信息的图像编码的补丁嵌入。特别是,图 2 说明了我们的模型合并了一个视觉塔,它将来自输入图像的视觉表示编码为编码的补丁嵌入。随后,它被单独发送到 Q 型器以提取精炼的学习查询嵌入,并发送到投影层,允许 LLM 掌握丰富的视觉知识。我们将两种类型的嵌入连接起来,并将它们直接馈送到 LLM。这些组合的视觉嵌入立即附加在问题文本嵌入之后,作为 LLM 的最终输入。在推理过程中,我们采用光束搜索来选择最佳生成的输出。相反,对于分类和多选 VQA 基准,我们采用了 InstructBLIP 中概述的词汇排序方法(戴等人 2023)。鉴于我们对候选列表的先验知识,我们计算了每个候选列表的对数可能性,并选择值最高的一个作为最终预测。为了支持我们架构的另一个商业用途版本,我们还选择了 FlanT5 XXL 作为我们的 LLM。这在本文中被命名为 BLIVA。
两阶段培训计划
我们采用了典型的两阶段训练方案:1)在预训练阶段,目标是使用来自提供图像全局描述的图像字幕数据集的图像 - 文本对将 LLM 与视觉信息对齐。2)预训练后,LLM 熟悉视觉嵌入空间并可以生成图像。然而,它仍然缺乏辨别图像更精细细节和响应人类问题的能力。在第二阶段,我们使用指令调整数据来增强性能,并进一步将视觉嵌入与 LLM 和人类值对齐。最近的方法主要采用了两阶段训练方法(朱等人 2023;刘等人 2023a;叶等人 2023),除了 PandaGPT(苏等人 2023),它利用了一阶段训练方法,也展示了值得称赞的结果。
在 BLIVA 中,我们的视觉助手分支,特别是编码的补丁嵌入,不同于使用 129M 预训练集的 BLIP-2 方法(Li et al.2023b)。相反,它利用了更紧凑的 0.5M 预训练字幕数据跟随(Liu et al.2023a)。这为在第一阶段对齐视觉编码器和 LLM 提供了一种更有效的策略。我们采用语言模型损失作为我们的训练目标。该模型根据前面的上下文学习生成后续标记。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









