









Two complementary AI approaches for predicting UMLS semantic group assignment: heuristic reasoning and deep learning
Yuqing Mao, Randolph A Miller, Olivier Bodenreider, Vinh Nguyen, Kin Wah Fung
Journal of the American Medical Informatics Association, Volume 30, Issue 12,
预测 UMLS 语义组分配的两种互补 AI 方法:启发式推理和深度学习
该论文的数据集是公开的。数据存储在 Dryad 数据平台上,链接为:Dryad | Data -- Two complementary AI approaches for predicting UMLS semantic group assignment: heuristic reasoning and deep learning。提供的是一个管道分隔的文本文件,可以在任何文本编辑器中打开或导入到任何电子表格软件中,并且附带的 readme.txt 文件解释了每一列的信息。
关于代码,从目前公开的信息来看,文中未明确提及代码是否公开以及公开的获取途径等相关信息,所以尚不能确定代码是否公开。如果你对该论文的代码获取有进一步需求,建议联系论文的作者或相关研究团队。
问题
在 UMLS 中,每半年需要将大量新原子(特定来源的文本字符串)整合到元词库(Metathesaurus)中,其中关键部分是将同义原子合并为 UMLS 概念并分配永久概念唯一标识符(CUI)。但随着 UMLS 概念数量增加,新原子分类工作难度增大且易出错,因此需要自动化方法辅助将新原子分配到 UMLS 概念中,而预测新原子的语义组(SG)是此任务中的关键步骤,若要使 SG 在该任务中发挥作用,需高精度预测新原子的 SG。
挑战
- 数据多样性和复杂性:UMLS 整合了来自 222 个来源的术语,不同来源在术语贡献数量、新原子语义类型分布、新原子名称等方面存在差异,且更新内容变化多样,增加了预测新原子 SG 的难度。
- 准确性要求高:作为辅助 UMLS 编辑的中间步骤,SG 预测需达到至少 95% 的准确率,才能有效帮助将新原子分组到 UMLS 概念中。
- 方法的可解释性与可调整性:启发式方法依赖手动推导算法,可能在通用性上受限,但具有灵活性、处理时间短和部分步骤高精度的优点;深度学习方法虽一致性和可重复性高,但模型调整困难且像黑箱,修改需重新训练整个模型,耗时且占用计算资源多。
创新点
- 设计了一种 “瀑布式” 的启发式算法,通过一系列不同的预测方法逐步处理新原子,若一种方法无法以高置信度(95%)分配 SG,则将原子传递到下一个方法,且各方法顺序基于其在训练数据上的预测准确性确定。
- 提出两种混合方法(步骤级混合和原子级混合),结合启发式和深度学习方法,利用各自优势提高 SG 预测准确性。步骤级混合方法在启发式方法的特定步骤后切换到深度学习方法;原子级混合方法对每个原子都生成启发式和深度学习的预测结果,然后根据预测准确性选择最终结果。
【
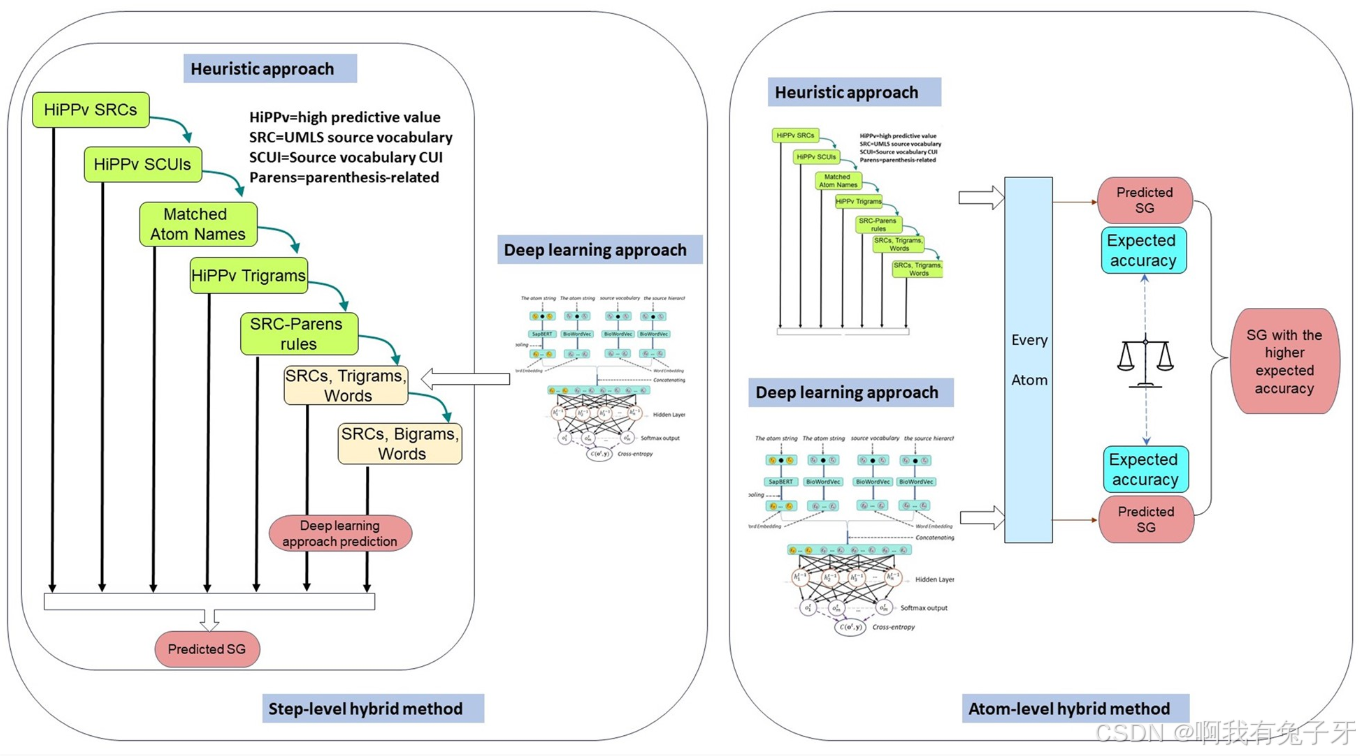
步骤级混合方法
- 流程:此方法起始于启发式方法的步骤 1,按照既定顺序依次执行各步骤。在执行过程中,持续评估每个步骤的估计准确率。一旦发现下一个步骤的估计准确率低于深度学习方法时,便立即切换到深度学习方法,由深度学习方法处理剩余的原子。例如,若在执行到启发式方法的某个中间步骤时,经评估发现下一步骤的准确率可能不如深度学习方法,此时就不再继续执行启发式方法的后续步骤,而是将剩余原子交给深度学习方法进行处理。
- 优势:这种方式能够充分发挥启发式方法在前几个高精度步骤中的优势,同时借助深度学习方法的强大学习能力处理启发式方法可能难以处理的原子,从而提高整体的预测准确性。
原子级混合方法
- 流程:针对每一个原子,分别运用启发式方法和深度学习方法独立地进行语义组(SG)预测。在得到两种方法的预测结果后,将它们进行结合。当两种方法对特定原子的预测结果不一致时,优先选择预期准确率较高的方法所给出的预测结果作为最终的预测。例如,对于某个原子,启发式方法预测其属于 SG1,深度学习方法预测其属于 SG2,此时会根据之前对两种方法准确率的评估,选择准确率更高的那个方法的预测结果作为该原子的最终 SG 预测。
- 优势:通过综合考虑两种方法对每个原子的预测,并依据准确率进行决策,原子级混合方法能够更精准地确定每个原子的 SG,从而进一步提升整体的预测性能。
】
【计算方法
- 启发式方法各步骤置信度计算
- 在启发式方法中,各步骤的置信度主要是基于训练数据中规则的匹配频率来计算的。例如在 “HiPPv SRCs(高阳性预测值来源)” 步骤中,会统计原子在先前 UMLS 版本中的来源与特定 SG 匹配的频率。如果来自某个特定来源的原子在过去被分配到某一 SG 的比例很高,比如达到 99.6%(如论文中该步骤的准确率),那么这个步骤对于来自该来源的新原子分配到这个 SG 的置信度就很高。
- 对于 “匹配原子名称” 步骤,当新原子名称与训练集中原子名称完全匹配且频率≥95% 时,就以这个 95% 作为置信度来使用匹配原子的 SG。
- 在 “HiPPv Trigrams(高阳性预测值三元组)” 步骤中,是根据从原子名称中提取的三元组在训练集中与 SG 的关联频率(≥95%)来确定置信度的。如果一个三元组与某个 SG 的关联频率达到这个阈值,那么在遇到包含该三元组的新原子时,就以这个频率对应的置信度来预测新原子的 SG。
- 深度学习方法置信度计算
- 在深度学习方法中,通过计算模型对原子的最高得分 SG 和第二高得分 SG 之间的差值(delta)来估计预测的概率。一般来说,delta 值越大,预测正确的概率越高。例如,当 delta 值很大时,表明模型对最高得分 SG 的判定很有把握,从而可以认为这个预测的置信度较高。具体的概率估计可能是通过对验证集等数据进行分析得到的,比如在不同 delta 区间内观察预测准确性,以此来建立 delta 值与置信度(预测正确概率)之间的关系。
- 混合方法置信度考虑因素
- 在混合方法中,步骤级混合方法是比较启发式方法下一个步骤的估计准确率与深度学习方法的准确率。这个估计准确率可能是基于启发式方法各步骤在训练数据上的历史准确率来确定的。例如,如果启发式方法的下一个步骤在历史数据中准确率较低,低于深度学习方法的已知准确率,就会切换到深度学习方法,这里对启发式方法步骤准确率的评估就是一种置信度的比较。
- 原子级混合方法是当两种方法对特定原子的预测不一致时,根据预期准确率较高的方法来选择最终结果。这个预期准确率可能是通过对启发式方法各步骤的历史准确率和深度学习方法在不同情况下的准确率综合评估得到的,以此作为选择的依据,其实也是在比较两种方法对于该原子预测的置信度。
】
贡献
- 证明了人工智能方法能够以足够高的潜在准确性预测新 UMLS 原子的 SG 分配,有助于将新原子分配到 CUIs 的任务。
- 表明在 SG 预测中,将启发式方法和深度学习方法相结合比单独使用任何一种方法能产生更好的结果。
提出的方法
- 启发式方法:采用 “瀑布式” 结构,包含多个定制方法(步骤)。
- 步骤 1(HiPPv SRCs - 高阳性预测值来源):根据原子在先前 UMLS 版本中的来源与特定 SG 的匹配频率来预测。
- 它会查看原子在以前 UMLS 版本中的来源,统计这个来源与特定 SG 匹配的频率。如果这个频率很高,就根据这个匹配来预测新原子的 SG。比如,来自某个特定医学文献数据库的原子,之前大部分都被归为某一个 SG,那么新原子如果也来自这个数据库,就很可能属于这个 SG。
- 步骤 2(HiPPv SCUIs - 高阳性预测值 SCUIs):结合原子的来源及其 SCUI(源词汇概念唯一标识符),基于训练数据中的组合频率预测 SG(仅在来源提供 SCUIs 时有用)。
- 这一步会结合原子的来源以及 SCUI(源词汇概念唯一标识符)。只有当来源提供了 SCUI 时,这一步才有用。它会根据训练数据中原子来源和 SCUI 组合的频率来预测 SG。例如,当某个特定的来源 - SCUI 组合在过去常常与某个 SG 相关联,那么新原子如果有相同的组合,就可能被预测为这个 SG。
- 步骤 3(匹配原子名称):若新原子名称与训练集中原子名称完全匹配且频率≥95%,则使用匹配原子的 SG。
-
- 当新原子的名称与训练集中原子的名称完全匹配,并且这种匹配的频率大于等于 95% 时,就直接使用匹配原子的 SG。就好像找到一个一模一样的名字,就直接用之前这个名字对应的 SG。
-
- 步骤 4(HiPPv Trigrams - 高阳性预测值三元组):从原子名称中提取单词、二元组和三元组,根据训练集中三元组与 SG 的关联频率(≥95%)预测新原子的 SG。
- 从原子名称中提取单词、二元组和三元组。如果训练集中某个三元组与 SG 的关联频率大于等于 95%,就根据这个关联来预测新原子的 SG。例如,原子名称中有 “心脏疾病” 这个三元组,而在训练数据中 “心脏疾病” 大多与某个 SG 相关联,那么新原子就可能被预测为这个 SG。
- 步骤 5(SRC - Parens 规则 - 源括号规则):基于源在构造原子名称时使用的特定括号表达式模式预测 SG。
- 这一步是基于源在构造原子名称时使用的特定括号表达式模式来预测 SG。这是手动推导出来的规则,不过目前正在开发自动推导这个规则的方法。
- 步骤 6(SRCs,Trigrams,Words):对包含 3 个或更多单词的未分类原子,通过计算原子名称中三元组和来源与每个 SG 的关联百分比之和来预测 SG,若无法确定则用单词重复该过程。
- 对于包含 3 个或更多单词的未分类原子,会计算原子名称中三元组和来源与每个 SG 的关联百分比之和来预测 SG。如果这样还不能确定,就用单词来重复这个过程。
- 步骤 7(SRCs,Bigrams,Words):类似于步骤 6,但处理仅由 1 或 2 个单词组成的原子,使用二元组和单个单词预测 SG,若仍未确定则将 SG 设为 “DISO”。
- 对于仅由 1 个或 2 个单词组成的原子,会使用二元组和单个单词来预测 SG。如果经过这些操作还是不能确定 SG,就把 SG 设为 “DISO”。
-
启发式方法的每个步骤都有其特定的规则,而且是按照在训练数据上的预测准确性来排序的。如果一个步骤不能以高置信度(95%)分配 SG,就会把原子传递到下一个步骤进行处理。
- 步骤 1(HiPPv SRCs - 高阳性预测值来源):根据原子在先前 UMLS 版本中的来源与特定 SG 的匹配频率来预测。
- 深度学习方法:将文本数据转换为数值向量,使用 BioWordVec 和 SapBERT 语言模型生成原子字符串、源词汇名称和源层次结构中第二个顶层原子字符串的嵌入,将这 4 个嵌入连接后输入到全连接多层神经网络中,输出层有 15 个节点(对应 15 个 SG)。在训练时将基础 UMLS 版本的数据分为训练集和验证集(80% 和 20%),使用验证集微调神经网络超参数。通过计算深度学习模型对原子的最高得分 SG 和第二高得分 SG 之间的差值(delta),并分析不同 delta 区间内的预测准确性,以此估计预测的概率。
- 混合方法:
- 步骤级混合方法:从启发式方法的步骤 1 开始,按顺序执行各步骤,直到下一个步骤的估计准确率低于深度学习方法时,切换到深度学习方法处理剩余原子。
- 原子级混合方法:分别使用启发式和深度学习方法对所有原子进行 SG 预测,然后结合结果,当两种方法对特定原子的预测不一致时,使用预期准确率较高的方法的预测结果。
指标
- 准确率:预测正确的 SG 数量占总处理原子数量(AUI)的比例,用于评估启发式、深度学习和混合方法在预测新原子 SG 时的准确性。
- Delta 值:深度学习方法中,最高得分 SG 和第二高得分 SG 的模型输出分数之差,用于估计预测的准确性,delta 值越大,预测正确的概率越高。
模型结构
深度学习模型结构为全连接多层神经网络,包含一个隐藏层(2048 个神经元)、一个辍学层(比率 = 0.2)、一个批量归一化层,隐藏层使用整流线性单元(ReLU)激活函数,计算损失使用交叉熵损失函数,学习率为 0.00002,训练轮数为 100。
结论
人工智能方法能够以足够的准确性预测新 UMLS 原子的 SG 分配,可作为将新原子分配到 UMLS 概念这一耗时任务中的中间步骤,且结合启发式和深度学习方法在 SG 预测中能取得比单独使用更好的结果。
论文中不同方法的准确性如下:
- 启发式 “瀑布” 方法:对 1563692 个新的未见过的原子,准确预测了 94.3% 的语义组(SGs)。
- 深度学习(DL)方法:在同样的数据集上,其准确率也为 94.3%。
- 混合方法:两种混合方法的平均准确率达到了 96.5%。
具体来看,启发式方法中各步骤的准确率如下:
- HiPPv SRCs(高阳性预测值来源):处理的原子数占原始总数的 38%,预测准确率为 99.6%。
- HiPPv SCUIs(高阳性预测值 SCUIs):处理的原子数占比 21%,准确率为 99.6%。
- 匹配原子名称:处理的原子数占比 15%,准确率为 98%。
- HiPPv Trigrams(高阳性预测值三元组):处理的原子数占比 8%,准确率为 95%。
- SRC-Parens 规则(源括号规则):处理的原子数占比 2%,准确率为 95%。
- SRCs, Trigrams, Words:处理的原子数占比 12%,准确率为 71%。
- SRCs, Bigrams, Words:处理的原子数占比 4%,准确率为 65%。
这些结果表明,启发式方法和深度学习方法相结合的混合方法在 SG 预测中取得了比单独使用任何一种方法更好的结果。同时也说明人工智能方法能够以较高的准确性预测新 UMLS 原子的 SG 分配,可作为将新原子分配到 UMLS 概念这一耗时任务中的中间步骤。但文中也指出了一些挑战和未来工作的方向,例如数据集的性能差异、混合方法的局限性、启发式方法规则的可重复性等,还需进一步研究和改进。
剩余挑战和未来工作
- 数据集相关:研究中 5 个数据集存在性能差异,且基于 UMLS 版本间的变化,结果对未来版本的通用性有待验证,未来需定期回顾和改进方法以确保性能稳定。
- 混合方法局限性:混合方法依赖对两种方法预测准确性的估计,当前简化实验设计使用了所有数据集的微平均实际性能来推导单一预期准确性,未来可针对每个数据集更精确地计算预期准确性。
- 启发式方法规则可重复性:启发式方法步骤 5 中的括号相关规则是手动推导的,未来可能不可完全重现,目前正在开发自动推导该规则的方法,初步结果显示性能与手动规则相当。
- 方法扩展应用:尝试将 SG 预测方法应用于 UMLS 编辑过程中的语义类型算法分配,并作为审计工具,同时关注更新的深度学习模型和技术(如 ChatGPT 和 GPT - 4),可能对现有方法进行改进。
抽象的
使用启发式、深度学习 (DL) 和混合 AI 方法预测新 UMLS 元词库原子的语义组 (SG) 分配,目标准确率≥95%。
我们使用了来自 2020AA–2022AB UMLS Metathesaurus 连续版本的训练测试数据集。我们的启发式“瀑布”方法采用了 7 种不同的 SG 预测方法。不符合方法的原子被传递给下一种方法。DL 方法为原子名称生成 BioWordVec 和 SapBERT 嵌入,为源词汇表名称生成 BioWordVec 嵌入,为原子源层次结构中倒数第二节点的原子名称生成 BioWordVec 嵌入。我们将 4 个嵌入的连接输入到一个完全连接的多层神经网络中,该网络的输出层有 15 个节点(每个 SG 一个)。对于这两种方法,我们都开发了方法来估计它们预测的原子 SG 正确的概率。基于这些估计,我们开发了 2 种混合 SG 预测方法,结合了启发式和 DL 方法的优势。
启发式瀑布方法准确预测了 1 563 692 个新未见原子的 SG,准确率为 94.3%。同一数据集上的 DL 准确率也为 94.3%。混合方法的平均准确率为 96.5%。
我们的研究表明,AI 方法可以足够准确地预测新 UMLS 原子的 SG 分配,因此可以作为将新原子分配给 UMLS 概念这一耗时任务的中间步骤。我们表明,对于 SG 预测,结合启发式方法和 DL 方法可以产生比单独使用任何一种方法更好的结果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









