










https://github.com/Andoree/GEBERT
Sakhovskiy, A., Semenova, N., Kadurin, A., Tutubalina, E. (2023). Graph-Enriched Biomedical Entity Representation Transformer. In: Arampatzis, A., et al. Experimental IR Meets Multilinguality, Multimodality, and Interaction. CLEF 2023. Lecture Notes in Computer Science, vol 14163. Springer, Cham. https://doi.org/10.1007/978-3-031-42448-9_10
问题
在生物医学领域,从自由文本中识别特定生物医学概念(如疾病、症状和药物)存在困难,因为它们的名称、缩写和拼写不一致性变化很大,且单个概念可能有多种非标准形式。这一问题可通过医学概念归一化(MCN)解决,即将实体提及与知识库(KB)中的大量医学概念名称及其概念唯一标识符(CUI)进行映射12。
挑战
- 概念表示学习:现代方法利用语言模型(LMs)构建实体提及和概念的嵌入,但学习有意义且稳健的实体表示对 LMs 仍是挑战。
- 知识注入与利用:虽有尝试将外部领域特定知识(如 UMLS)注入预训练 LMs,但现有结构方法难以有效利用文本节点特征,且如 SAP 等过程未利用 UMLS 图结构描述概念间关系357。
- 词汇归一化困难:生物医学领域词汇丰富,存在大量语义相关但不同的概念,为概念归一化带来挑战,例如模型预测的概念可能与真实概念存在上下位关系等17。
创新点
- 提出 Graph - Enriched Biomedical Entity Representation Transformer(GEBERT)模型,通过图神经网络和对比学习捕获 UMLS 的图结构数据。
- 引入额外基于图的节点级对比目标,丰富实体表示,使概念嵌入独立于表面形式选择。
- 提出模态间对比损失,实现文本和结构模态间的知识共享,最小化概念的节点表示与其通过 LM 获得的文本嵌入之间的对比目标。
贡献
- 提出 GEBERT 模型,其架构包含文本对比损失、节点级对比损失和模态间对比损失,有效结合文本和图结构信息6。
- 探索了 GraphSAGE 和 GAT 等先进卷积图架构用于从局部节点邻居学习关系信息。
- 在五个英语 MCN 数据集上取得了最先进的结果,证明了模型在生物医学实体表示和概念归一化任务上的有效性。
提出的方法
- 基于自对齐预训练(SAP)的文本损失:采用 SAP 过程,通过在线硬挖掘有效三元组,利用 Multi - Similarity(MS)损失学习文本知识,将概念名称表示为正、负样本对并优化对比学习损失函数89。
- 节点级损失:定义批次子图,用文本编码器产生文本嵌入,通过堆叠多层 MPNN 聚合结构信息,将图增强表示传入 SAP 过程获得节点级对比损失,使相同概念的术语表示在余弦距离上接近101112。
- 模态间损失:构造包含节点级和术语级表示的跨模态正样本,应用 SAP 过程优化跨模态对比 MS 损失,使文本和节点表示距离最小化,推动不匹配概念表示远离13。
指标
使用 top - k 准确率(Acc@k)作为评估指标,若在排名≤k 时检索到正确的 UMLS 概念唯一标识符,则 Acc@k = 1,否则 Acc@k = 016。
模型结构
- 文本编码器:使用基于 BERT 的文本编码器,为文本术语生成嵌入。
- 图编码器:采用 GraphSAGE 或 GAT 等图神经网络架构,将文本嵌入作为额外输入,学习节点表示并聚合邻居信息。
- 损失函数:由文本对比损失()、节点级对比损失()和模态间对比损失()组成,,其中和是预定义权重413。
结论
- GEBERT 模型通过文本和图编码器间的知识交换,在五个基准数据集上经过任务特定微调后优于现有最先进的概念归一化模型。
- 模型在零样本设置下表现不错,在生物医学领域经过域内微调后性能更优。
剩余挑战和未来工作
- 目前的方法可能未充分利用 UMLS 图中的关系知识,需要探索更有效编码图结构知识到 LMs 的方法。
- 未来计划将模型用于多语言预训练,以及在节点邻居聚合阶段注入关系类型。
数据集
- 训练数据:使用 UMLS 2020AB 版本,包含约 440 万个概念和 1590 万个独特概念名称(去除非英语源词汇的概念名称和重复边),并遵循 SapBERT 的批处理策略,预计算同义词对以确保每批包含足够正样本14。
- 测试数据:使用五个数据集进行评估,包括 NCBI、BC5CDRD、BC5CDR - D、TAC2017ADR、BC2GN,因官方训练 / 测试集存在重叠,使用 [32] 中提出的精炼测试集。具体为:
- NCBI Disease Corpus:793 篇 PubMed 摘要,包含疾病提及及其对应概念15。
- BC5CDRD:用于从 1500 篇 PubMed 摘要中提取化学 - 疾病关系(CDR),标注了化学和疾病信息1518。
- BC5CDR - D:同 BC5CDRD 任务相关15。
- TAC 2017 ADR challenge:从产品标签(如处方信息或包装插页)中提取不良药物反应(ADRs)1519。
- BC2GN:包含 PubMed 摘要中的人类基因和基因产物提及,用于基因归一化(GN)1520。
摘要。
将关于不同生物医学概念和关系的外部领域特定知识注入语言模型(LM)提高了它们处理专业领域内任务的能力,如医学概念规范化(MCN)。然而,现有的生物医学 LM 主要使用术语(例如 UMLS)中的同义概念名称作为正锚进行对比学习训练,而图节点和邻居特征的准确聚合仍然是一个挑战。在本文中,我们提出了图丰富的生物医学实体表示转换器(GEBERT),它通过图神经网络和对比学习从 UMLS 捕获图结构数据。在 GEBERT 中,我们通过引入额外的基于图的节点级对比目标来丰富实体表示。为了实现文本和结构模式之间的相互知识共享,我们最小化了概念的节点表示与其通过 LM 获得的文本嵌入之间的对比目标。我们探索了几种最先进的卷积图架构,即 GraphSAGE 和 GAT,以从局部节点邻域学习关系信息。经过特定任务的监督,GEBERT 在五个英文 MCN 数据集上取得了最先进的结果。
1 介绍
生物医学实体表示在许多生物医学任务中得到了应用,例如知识发现、信息提取和搜索 [5,9,15,21,29,31]。尽管如此,在自由格式的文本中识别特定的生物医学概念(如疾病、症状和药物)可能会有问题,因为它们的名称、缩写和拼写不一致是高度可变的。此外,一个单一的生物医学概念可以以许多非标准形式出现。这一挑战可以通过医学概念规范化(MCN;也称为医学概念链接)来解决,这是一项任务,其中实体提及与来自知识库(KB)的大量医学概念名称及其概念唯一标识符(CUI)相映射。除了提及的高度变化之外,生物医学领域还具有广泛的知识库,如统一医学语言系统(UMLS)[3]。
MCN [19,26] 常用分类类型损失的早期模型通常在狭窄的基准上进行训练,并导致其他领域和结构不同文本的性能显著下降。现代方法通常采用实体提及的嵌入(分布式表示)和由语言模型(LM)构建的概念与类似 BERT [7] 的排序架构 [30,32,38] 之间的相似性。然而,学习有意义和鲁棒的实体表示的问题仍然对 LM 构成挑战。
生物医学知识已经通过度量学习和对比学习注入神经网络 [17,22,24,27,37]。自然,来自知识库的知识通常表示为三元组(头、关系、尾);相同和不同概念的头尾术语充当正负对(例如,糖尿病肾病是糖尿病肾病的同义词,不同于糖尿病,如图 1 所示)。除了文本三元组的表示学习 [17,22,27,37] 之外,还提出使用受 TransE [4] 和 DisMult [36] 等语义匹配方法启发的术语 - 关系 - 术语相似性。然而,这些结构方法无法有效地使用文本节点特征。
在本文中,我们提出了使用对比学习和图神经网络的图丰富的生物医学实体表示转换器(GEBERT)致力于从 KB 中捕获图形结构数据。如图 1 所示,GEBERT 架构由三个损失组成:(i)学习同义概念名称的文本对比损失;(ii)节点级对比损失,学习产生独立于表面形式选择的概念嵌入;(iii)允许文本和图形编码器之间信息交换的模态对比损失。源代码和预训练模型是免费提供的 1。
图 1. GEBERT 模型的架构概述。我们的模型由文本和图形数据的两个编码器组成。图形编码器使用来自 BERT 的文本嵌入作为附加输入。损失函数是三项的加权和:文本和节点级对比损失,以及多模态对比损失,以匹配不同编码器之间的表示。
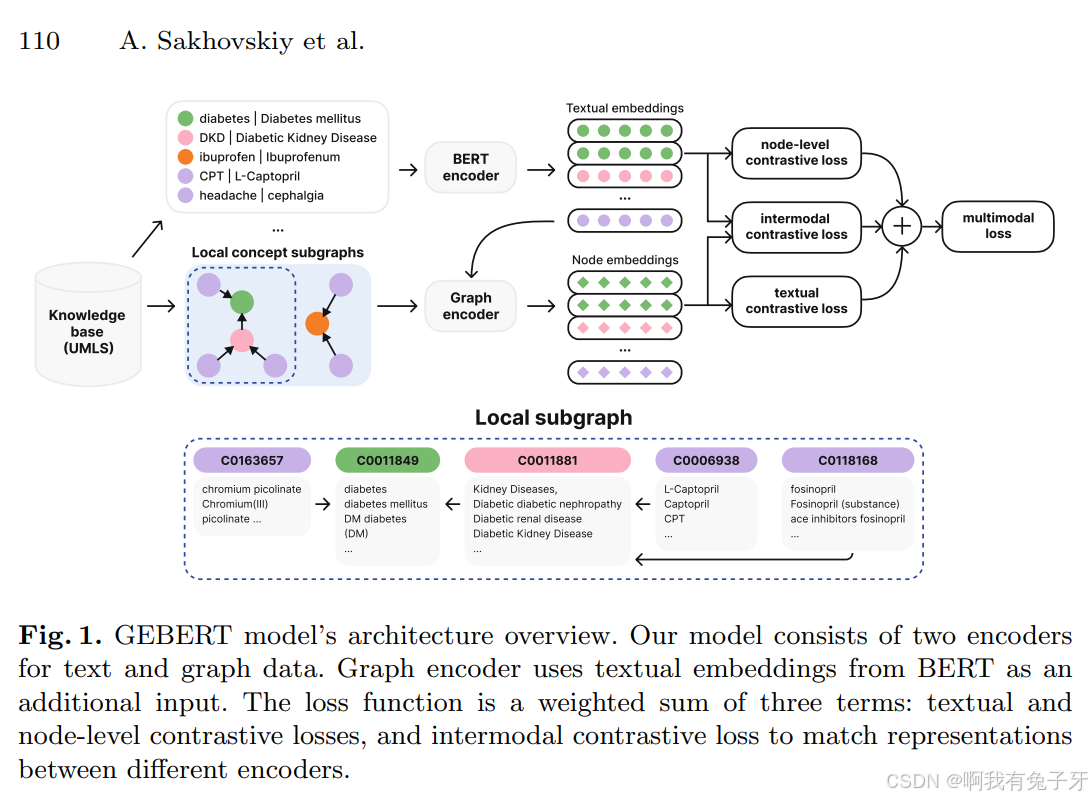
致力于从 KB 中捕获图形结构数据。如图 1 所示,GEBERT 架构由三个损失组成:(i)学习同义概念名称的文本对比损失;(ii)节点级对比损失,学习产生独立于表面形式选择的概念嵌入;(iii)允许文本和图形编码器之间信息交换的模态对比损失。源代码和预训练模型是免费提供的 1。
2 相关工作
MCN 通常被表述为具有广泛特征的分类或排序问题,包括句法、形态学解析、医学概念及其同义词的字典,以及正式概念名称和原始实体提及之间的距离(稀疏 / 密集表示)[1,6,33]。
分类方法 [19,26] 通常在标记数据集上进行训练,其中提及与一小部分目标概念相关联,而现有的生物医学知识库,如 UMLS,拥有数百万个概念。排名模型使用字典中的正负项训练对来确定实体提及和概念名称的相似程度。[24] 训练了一个三元组网络,根据候选概念名称与疾病提及的相似程度对其进行排名。基于词嵌入的卷积和池化层被选为编码器。[30] 提出了 BioSyn 模型,该模型最大限度地提高了所有同义词表示存在于前 20 名候选中的可能性。作为相似性函数,BioSyn 将稀疏和密集分数与标量权重相结合。为了对给定字符串的形态信息进行编码,稀疏分数在字符级 TF-IDF 表示上计算。密集分数由 BioBERT [14] 中单个输入向量的 CLS 标记之间的相似性来定义。[22] 提出了一种 DILBERT 模型,该模型通过三元组损失优化术语中提及和概念名称的相对相似性。不同的负抽样策略被应用于 DILBERT 模型,包括随机抽样和使用概念父母(父子或更宽更窄的关系)的概念名称进行重新抽样。然而,DILBERT 和 BioSyn 都在英语数据集上进行了训练,其中包含来自特定术语的狭窄概念子样本。
很少有人尝试将外部特定领域的知识(例如,UMLS)注入预训练语言模型(LM)中,以便学习实体表示 [17,18,20,27,37]。[27] 提出了一个具有上下文、概念和基于同义词的目标的编码框架。基于同义词的目标在同义词名称之间强制执行相似的表示,而基于概念的目标则将名称的表示拉近其概念的形心。该模型在 2900 万 PubMed 摘要上进行了训练,这些摘要用疾病和化学物质的 UMLS 概念进行了注释。然而,在这些嵌入上的排名显示出比在英语的三个集合上具有字典和特征的模型更糟糕的结果。UmlsBERT [20],一个类似 bert 的 LM,在
通过一种新颖的知识增强策略进行预训练过程。最近,提出了一种用于从 UMLS 学习同义词对的自对齐预训练(SAP)[17] 程序。该程序的作者发布了一个基于 BERT 的 SapBERT 模型,该模型在 UMLS 的英语同义词上进行预训练。SapBERT 在 UMLS 上预训练优于 MCN 任务中的几个特定领域的 LM,如 BioBERT [14]、SciBERT [2] 和 UmlsBERT [20]。
SAP 过程没有使用描述概念之间关系的 UMLS 图的结构。为了解决这一限制,提出了一种名为 CODER 的关系感知语言模型 [37]。作者将 UMLS 图中的关系知识注入到原始 SAP 过程中,除了基于同义词的对比损失之外,还引入了关系损失。与 SapBERT 相比,主要区别在于 CODER 同时从同义词和相关概念中学习。
3 背景和架构
设 V 表示知识库中存在的所有概念的集合。知识图,如 UMLS,通常以关系三元组的形式存储关系信息其中 h 和 t 是来自 V 的概念,r 是关系类型。在这项工作中,我们省略了关系类型,并将 UMLS 图视为定向无标记图,其中 ε 是去掉关系类型的定向边集。对于的每个概念,UMLS 呈现一组 k 个同义术语。对于来自的每个术语,UMLS 存储它来自的语言的标签。让我们表示一个任意的文本术语,换句话说,它是一个概念名称。生物医学实体链接任务的目标是预测 s 所属的概念。
3.1 自我对齐预训练
学习生物医学实体信息表示空间的一个合理而直接的方法是以正负项对的形式表示来自 KG 的文本知识,并优化一些对比学习损失函数。
在这项工作中,我们采用了自对齐预训练(SAP)程序 [17]。为了用更硬的负样本丰富训练程序,SAP 采用在线硬挖掘有效三元组 [10,23]。在 SAP 期间,鼓励模型为代表相同概念的所有术语产生相似的表示(共享相同的 CUI)。在每个预训练步骤,我们对由 N 个正样本组成的批次 B 进行采样。给定 B,SAP 构造所有可能的术语三元组使得和称为锚术语;是的正术语(即和是代表相同概念的同义术语);是的负术语(即…和代表不匹配的概念)。每个三元组产生一个正对和一个负对。为了只保留信息最多的三元组,我们使用在线硬挖掘对有效三元组进行以下约束:
其中是基于 BERT 的文本编码器,是归一化的范数,λ 是预定义的挖掘余量。因此,挖掘过程丢弃所有三元组,使得从锚到其负样本的距离大于到其正样本的距离超过 λ。让 P 和 N 分别表示所有正负项对的集合。SAP 过程利用多相似度(MS)损失 [35] 从 P 和 N 中学习其中 α , β , 和😍是 MS 损失的参数。和是锚概念 i 的正负样本集。
3.2 图神经网络
消息传递框架。从图中学习结构化知识的一种常见方法是通过使用图神经网络传递和聚合来自本地节点邻域的消息来迭代地更新节点 v 的表示。消息传递神经网络(MPNN)[11] 框架,描述了节点表示的更新在)- 第 MPNN 层作为消息函数和更新函数的组成:其中是节点 v 的相邻节点集。由于邻居的数量可以在不同的节点之间显着变化,并导致过多的计算复杂性,我们使用统一绘制的固定大小的邻居子集,而不是 [13] 提出的完整节点邻域。和的选择是属于 MPNN 框架下的各种 GNN 模型之间的关键区别。在 MPNN 框架的一种常见且相当简单的实现 GraphSAGE [13] 中,使用元素级运算符(例如 max - 或均值池化)作为,将相邻节点的向量聚合成单个向量。聚合的表示进一步与原始表示连接,并传递给具有非线性激活函数 σ 的线性层。在这项工作中,我们使用具有均值池化聚合的 GraphSAGE 实现:其中是均值池化运算符,是两个向量的连接。GraphSAGE 的简单性防止了上下文感知消息传递,因为均值池化以相等的权重对待来自的所有节点。
这意味着图形 SAGE 无法根据与目标节点的相关性来权衡邻域。
图注意力网络(GAT)[34] 通过引入相邻节点上的自注意力并学习聚合邻域表示作为相邻节点表示的加权和来解决这一限制。给定两个节点表示和,第 l 个 GAT 层计算节点 u 与目标节点 v 的相关性作为归一化注意力分数$\alpha_{u v}^{(l)}
\alpha_{u v}^{(l)}=\frac{exp \left(e_{u v}^{(l)}\right)}{\sum_{w \in N(v)} exp \left(e_{w v}^{(l)}\right)}$
使用获得的注意力分数,将聚合的邻域表示计算为相邻节点嵌入的加权和。
3.3 轴承
文本损失。在 GEBERT 中,我们采用并扩展了第 3.1 节中描述的预训练过程。在每个训练步骤中,我们从随机正样本的批 B 开始。每个正样本是一个三元组由概念(节点)标识符和两个同义概念名称组成。对于每个 t,我们使用图 G 随机采样一组概念节点的邻居(概念的邻居)。接下来,我们使用文本编码器为 B 中存在的每个术语生成文本嵌入并使用来自批 B 的概念名称的表示来计算文本损失。
节点级损失。我们将批处理的子图定义为来自批处理 B 的概念节点以及来自概念邻域、的所有节点和边的联合。我们的目标是丰富文本编码器的嵌入空间存储在中的结构知识,同时保持表示相同概念的术语的嵌入以余弦距离彼此接近。如图 1 所示,对于每个正对,文本编码器产生两个文本嵌入:分别针对该对的第一个和第二个术语。这些嵌入被传递到图编码器进行节点初始化。
让和分别表示来自 B 的正对的第一项和第二项的 d 维文本嵌入矩阵。为了获得节点(概念)c 的两个图丰富的表示和,我们堆叠多个 MPNN 层来聚合来自节点邻域的结构信息使用和作为节点的初始表示。接下来,我们收集所有正节点样本并将它们传递给 SAP 过程以获得节点级对比
失。因此,nd之间的主要区别在于后者在图感知节点(概念)嵌入上运行,而不是概念术语的文本嵌入。
联运损失。让和)分别表示概念 c 的术语级和节点级正样本。我们构建两个联运正样本和,每个样本都包含 c 的节点级和术语级表示。为了允许文本编码器和图编码器之间的相互知识交换,我们收集所有联运正对,并再次应用 SAP 程序来优化联运对比 MS-Loss,它最小化了同一概念的文本和节点表示之间的距离,并推开了不匹配概念的表示。和是和的预选权重
4 实验评估
我们用 PubMedBERT2 [12] 初始化了 GEBERT。该模型在英国 UMLS 图上训练了 1 个时代,学习率为。我们将和节点邻域的最大大小设置为 3。作为图编码器,我们使用 GraphSAGE 或 GAT 的连续 3 层。
我们实现了两个不同于图形编码器架构的 GEBERT 版本:(i)GraphSAGE-GEBERT 和(ii)GAT-GEBERT。为了训练我们的 GEBERT 实现,我们使用 UMLS 2020AB 版本,该版本包含大约 440 万个概念和 215 个源词汇表中的 1590 万个唯一概念名称。我们删除了所有源自非英语源词汇表的概念名称,并删除了所有重复的边。我们遵循 SapBERT [17] 作者提出的批处理策略:为了确保每批包含足够数量的正对,我们使用常见的 CUI 预先计算同义词对。如果一个概念产生超过 50 个正对,我们随机采样其中的 50 个。
数据。为了评估我们的模型,我们使用了 5 个数据集:(i)NCBI [8],(ii)BC5CDRD [16],(iii)BC5CDR-D [16],(iv)TAC2017ADR [28],(v)BC2GN [25]。由于官方训练 / 测试集之间的重叠,我们遵循 [32] 并使用所呈现的精炼测试集。有关预处理和集合的详细信息,请参阅 [32]。我们使用了作者在 https://github.com/insilicomedicine/Fair-Evaluation-BERT提供的公开可用代码。
NCBI 疾病语料库 [8] 是 PubMed 的 793 篇摘要的集合,其中包括疾病及其相应概念的提及。[16] 介绍了从 1500 年提取化学疾病关系(CDR)的任务
PubMed 摘要,带有化学品和疾病的注释。BioCreative II GN(BC2GN)[25] 包含 PubMed 摘要中对人类基因和基因产物的提及,用于基因归一化(GN)。TAC 2017 ADR 挑战赛 [28] 侧重于从产品标签中提取不良药物反应(ADR),例如处方信息或包装插页。
实验设置。我们在两个设置中评估所提出的模型:(i)零射击评估和(ii)微调评估。
对于零样本评估,我们采用了一种基于提及和潜在概念嵌入的排名方法 [32]。每个实体提及和概念名称首先通过生成其嵌入的模型,然后通过产生固定大小向量的平均池化层。这
后将推理任务简化为在公共嵌入空间中找到最接近实体提及表示的概念名称表示,其中欧氏距离可以用作度量。选择最近的概念名称作为实体的 top-k 概念。
对于微调的评估,我们使用 BioSyn [30],这是一种通过应用同义词边缘化迭代更新候选者的模型。该模型利用两个不同的相似函数来捕获形态和语义信息。稀疏表示是使用 TF-IDF 获得的,密集表示是使用基于 BERT 的模型获得的。我们采用默认的 BioSyn 超参数 [30]。对于每个数据集,我们训练 BioSyn 20 个时期,接下来是 [32]。
我们在 IR 场景中评估模型,其目标是为概念名称及其标识符字典中提到的每个实体找到 top-k 概念。遵循以前的工作 [17,18,27,30,32,37],我们使用 top-k 准确性作为评估指标:如果在检索到正确的 UMLS 概念唯一标识符,否则
比较表示。我们比较以下表示:
enSapBERT:一个基于 BERT 的度量学习框架,基于 UMLS 生成硬三元组用于预训练 [17]。该模型采用来自 huggingface.co/cambridgeltl/SapBERT-from-PubMedBERT-fulltext。enCODER:一种受语义匹配方法启发的对比学习模型,该方法使用来自 UMLS 的同义词和关系 [37]。我们使用了 huggingface.co/GanjinZero/coder 提供的模型。
4.1 结果
表 1 显示了五个数据集的 Acc@1 和 Acc@5 指标。在零样本评估中,基本 enSapBERT 在 5 个数据集中的 3 个数据集上的 Acc@1 方面优于 CODER 和 GEBERT。在 BC5CDR 的疾病和化学提及方面,最好的模型是 GraphSAGE-GEBERT 和 GAT-GEBERT,比 enSapBERT 略有改进。一个有趣的发现是,enCODER 是所有五个数据集上表现最差的模型 Acc@1 尽管它继承了 enSapBERT 的两个训练目标之一。微调后情况发生了变化:我们的 GraphSAGE-GEBERT 模型在所有五个学术数据集上成为领导者,在 TAC ADR 和 BC2GN 上与 enSapBERT 相比没有显著改善(分别为 0.13% 和 0.1%),在 NCBI、BC5CDR 疾病和 BC5CDR 化学(分别为 0.98%、0.91% 和 1.41%)上有显著改善。平均而言,GraphSAGE-GEBERTAcc@1 分别优于 enSapBERT 和 enCODER 0.71% 和 1.36%。enCODER 在 5 个数据集中的 3 个上仍然表现最差。因此,我们提出的 GraphSAGE-GEBERT 在零镜头设置下具有不错的性能,经过域内微调后在生物医学领域显示出卓越的性能。
讨论和错误分析。我们在 TAC 2017 ADR 语料库的精细测试集上查看了微调 GraphSAGE-GEBERT 模型的错误预测。表 2 中提供了模型错误的一些示例。在错误分析之后,我们可以得出以下关键观察结果。首先,在许多情况下,模型预测的概念与真实概念存在某种关系(例如,低音或超音)。例如,模型将与心率变化相关的提及标记为它的部分情况 —— 心率下降。其次,从示例中可以看出,词汇丰富的归一化问题通过提供过多不同但语义相关的概念(如 “杀人未遂” 和 “杀人意念”)构成了巨大挑战。因此,在许多情况下,一个真正的概念和错误预测的概念在 UMLS 中通过某种关系联系在一起。我们认为正确利用这种关系知识是提高归一化质量的关键。据推测,GEBERT 和 enCODER 都没有完全揭示存储在 UMLS 图中的关系知识的力量。将图中的结构知识编码成 LM 的更棘手和有效的方法还有待探索。
5 结论
在这项工作中,我们提出了一个名为 GEBERT 的新模型,它允许文本编码器和图编码器之间的相互知识交换。我们在包含 4M 概念(节点)、15M 文本概念名称和 38.8M 关系(边)的英文 UMLS 图上使用不同的最先进的 GNN 编码器预训练了两个 GEBERT 模型。在五个英文基准数据集上的实验结果表明,经过特定任务的微调后,GEBERT 优于现有的最先进的概念规范化模型。我们考虑未来工作的以下两个方向。首先,我们计划采用所提出的模型进行多语言预训练。其次,我们计划在节点邻域聚合阶段注入关系类型。
致谢。这项工作得到了俄罗斯科学基金会赠款 #23-11-00358 的支持。
- Michalopoulos,G.,Wang,Y.,Kaka,H.,Chen,H.,Wong,A.:UmlsBERT:使用统一医学语言系统元词库对上下文嵌入进行临床领域知识增强。在:计算语言学协会北美分会 2021 年会议论文集:人类语言技术,第 1744-1753 页(2021)
- Michalopoulos, G., Wang, Y., Kaka, H., Chen, H., Wong, A.: UmlsBERT: clini-
cal domain knowledge augmentation of contextual embeddings using the unified
medical language system metathesaurus. In: Proceedings of the 2021 Conference
of the North American Chapter of the Association for Computational Linguistics:
Human Language Technologies, pp. 1744–1753 (2021)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









