










第三届健康机器学习研讨会论文集,PMLR 225
Multi-modal Graph Learning over UMLS Knowledge Graphs
抽象的
- 问题:如何从电子健康记录(EHR)数据中学习更有意义的医学概念表示,以辅助临床决策,特别是在面对多模态数据和样本稀缺问题时。
- 挑战
- 当前基于 UMLS 的方法未充分利用完整关系信息,且多局限于树状结构的简单图,忽略了复杂图结构。
- 多模态数据融合通常依赖复杂架构和大量数据,难以有效处理 EHR 中的结构化和非结构化数据。
- 医疗领域存在监督标签稀缺问题,影响模型性能和泛化能力。
- 创新点
- 提出多模态 UMLS 图学习(MMUGL)方法,利用 UMLS 知识图谱和图神经网络学习医学概念表示,考虑多种词汇和复杂关系。
- 引入共享潜在概念嵌入空间和共享访问编码器,以统一方式处理多模态数据,提高参数效率。
- 提出新的预训练方法,包括加权重建预训练、疾病聚焦预训练和 Sum Aggregation Loss,以适应不同下游任务并提高模型性能。
- 贡献
- 提出新的医疗知识表示技术,通过 GNN 在复杂 UMLS 知识图谱上学习概念表示,提升性能。
- 引入共享潜在空间和编码器,优化单一潜在空间,实现多模态信息融合。
- 在多个下游任务中超越先前方法,展示了所提方法在医疗数据建模中的有效性。
- 提出的方法
- 概念嵌入模块:从 UMLS 中构建知识图谱,用 SapBERT 初始化节点,训练多层 GNN 获取概念表示,考虑不同基线图对比。
- 概念提取:用 QuickUMLS 从临床报告中提取概念,结合 NegEx 处理否定信息,与离散代码融合。
- 访问编码器:基于 Transformer,对不同概念类型分别编码,通过 CLS token 聚合访问表示,可选择是否包含临床报告信息。
- 预测器与训练
- 预训练模块:扩展自编码器预训练,进行多任务预测,采用加权和疾病聚焦预训练,引入 Sum Aggregation Loss,结合临床报告概念,调整损失函数。
- 下游模块:基于现有架构进行时间序列建模,在多个下游任务中评估,包括心力衰竭、诊断、再入院和住院时间预测。
- 指标
- 药物推荐任务:样本平均精确召回曲线下面积(AuPRC)和样本平均宏 F1 分数。
- 心力衰竭任务:F1 分数和接收者操作特征曲线下面积(AuROC)。
- 诊断任务:阈值加权 F1 分数(w - F1)、F1 分数(infl.)和召回率(R@k)。
- 再入院任务:不同时间范围的再入院预测使用 AuROC 评估。
- 住院时间预测任务:加权 AuROC。
- 模型结构
- 由概念嵌入模块、访问编码器和预测器模块组成。概念嵌入模块基于 UMLS 知识图谱和 GNN 学习概念表示;访问编码器利用 Transformer 架构聚合访问信息;预测器模块在预训练和下游任务中分别执行相应预测。
- 结论
- MMUGL 方法通过多模态学习和 UMLS 知识图谱有效提高下游任务性能。
- 预训练和知识图谱概念嵌入对提升性能重要,可处理多模态 EHR 数据。
- 方法为临床提供更丰富信息,有助于理解疾病进展,为医疗机器学习提供有力工具。
- 剩余挑战和未来工作
- 探索整合更多类型数据,如实验室测试或程序代码,进一步丰富患者表征。
- 研究如何利用更通用的医学概念嵌入,避免不同系统间的映射问题,提高方法的通用性。
- 进一步探索如何在模型中更好地利用知识图谱的结构和语义信息,提高模型的可解释性和临床实用性。
- 数据集:使用 MIMIC - III 数据集(版本 1.4)进行实验,该数据集包含丰富的患者信息,如结构化 EHR 数据(以计费代码形式)和非结构化文本(临床报告)。在实验中,对数据集进行了预处理,包括将药物映射到 ATC 层次结构,根据不同任务需求划分训练、验证和测试集,并在多个下游任务中使用该数据集评估模型性能。
- 引言
现代医疗保健机构将患者信息记录为电子健康记录 (EHR)。EHR 数据集,如 MIMIC-III(Johnson 等人,2016 年)、HiRID(Faltys 等人,2021 年)和 eICU(Pollard 等人,2018 年)可以在一次医院就诊中对疾病进展进行建模,例如在重症监护病房 (ICU) 中(Harutyunyan 等人,2019 年;Y'eche et al., 2021),或多次患者就诊的进展(Choi et al., 2018)。正如许多先前的工作所表明的那样,这些进展可以使用深度学习有意义地编码为患者表征(Choi 等人,2016 年、2018 年、2017 年;Bai et al., 2018;Lu et al., 2021a, 2022)。大量工作凸显了强大的患者表征的价值,这些表征汇总了来自多次住院的整个患者病史的信息,使临床医生能够在有关患者演变的各种预测任务中对潜在风险进行建模。
我们看到了最近在 ICU 环境中多模式方法的优势(Khadanga等人,2019 年;Husmann等人,2022 年)和访问序列建模(Lu et al.,2021a)。在多模态 EHR 表示学习(Park et al., 2022)中,我们受益于两种模式:结构化 EHR 数据(例如,计费代码)和存储在丰富临床报告中的非结构化文本信息。在医院数据集之外还存在其他形式的医疗数据,其中大量的先前医学知识以静态形式存储在数据库中,例如统一医学语言系统 (UMLS) (Bodenreider, 2004)。
我们确定了当前基于 UMLS 的方法的两个缺点(Beam et al., 2020;Skreta等人,2021 年;毛和冯,2020 年)。首先,这些方法不考虑存储在 UMLS 中的一整套关系信息(不考虑多个词汇表),而只使用 UMLS 作为统一的概念空间。其次,先前的解决方案(Skreta等人,2021 年;毛 和 Fung,2020 年)指定了分层关系的使用,这意味着使用树形式的底层图(单个词汇)。因此,省略了词汇表内部和跨词汇表的更复杂的图形结构。
我们引入了多模态 UMLS 图形学习 (MMUGL) 来克服前面提到的限制。MMUGL 是一种新颖的方法,用于学习以复杂知识图谱和关系的形式从 UMLS 元词库中提取的医学概念的表示;使用简单而雄心勃勃的程序提取,包括相当多的词汇集以及它们之间和内部的所有关系。
我们使用自动编码器预训练技术(Shang et al., 2019)训练共享的潜在空间(Liu et al., 2021b),并弥合结构化 EHR 代码和非结构化文本之间的模态差距。所提出的方法包括丰富的先验知识,这在医学领域很重要。它依靠先验知识结构和预训练技术来解决样本稀缺问题,并利用多种模态作为输入。
贡献
・在第 4.1 节中,我们提出了一种新的医学知识表示技术,该技术在前所未有的复杂 UMLS 元词库上使用图神经网络 (GNN)。以前的研究已经探索了这些知识,但我们更进一步,证明我们可以通过考虑整个 UMLS 元词库的很大一部分并将强大的结构先验纳入我们的机器学习模型来提取大型而复杂的知识图谱,从而提高性能。
我们引入了一个共享的潜在概念嵌入(第 4.1 节)空间和一个共享的访问编码器(第 4.3 节),以参数高效的方式共同优化来自任何模态的单个潜在空间。与每种模态单独模型输入的想法相反,我们展示了以相同的先验知识为基础所有模态并为所有输入模态(结构化和非结构化 EHR)训练单个潜在空间的好处。
・在第 6 节中,我们证明了我们在预训练和下游任务中的表现明显优于先前的基于图的工作,并且可以与在更大规模的数据中训练的先前工作竞争或优于先前的工作。我们表明,在更长的预测范围内,我们的方法与再入院预测的相关性更高。
- 相关工作
下面,我们介绍了 EHR 建模、知识图谱学习和 EHR 背景下的图学习方面的相关工作。
EHR 已经提出了各种类型的深度学习架构来学习不同粒度(患者、就诊、病史等)的表示
EHR 数据集。Choi 等人(2016 年);Bai et al. (2018) 提出了特定于 EHR 的访问序列模型。Choi 等人(2018 年)建议关注 EHR 的内在结构,包括治疗、诊断、就诊和患者。Rasmy et al. (2021) 采用掩蔽语言建模方法来学习医学概念嵌入。
多模态先前的工作考虑了来自 EHR 数据的结构化组件的学习表示(Choi 等人,2018 年、2017 年;Rasmy等人,2021 年)或非结构化临床文本报告(Alsentzer等人,2019 年;Peng et al., 2019)。Meng et al. (2021);Gong 和 Guttag (2018);Suresh 等人(2017 年)提出了多模态架构,Park 等人(2022 年)更进一步,引入了更强大的结构先验,同时考虑了结构化 EHR 数据和非结构化临床报告的两种模式。
知识图谱和 GNN:在当前的建模方法中,大量静态的先验医学知识通常保持不变。这些先验知识可以提取并转化为知识图谱(Rotmensch et al., 2017;Harnoune等人,2021 年)。自然语言处理方面的现有工作已经确定了知识图谱表示对各种下游应用程序的好处(Zhang et al., 2019;Sun等人,2020 年;He et al., 2020;Wang et al., 2021);其中最新的方法包括 GNN(Yasunaga et al., 2021, 2022)。我们的目标是利用 GNN 的成功来学习节点(和边缘)表示(Kipf 和 Welling,2017 年;Hamilton et al., 2017;Veliˇckovi'c et al., 2018)。
EHR GRAM 中的图学习(Choi et al., 2017)提议包括来自医学本体论的先验知识,例如国际疾病分类 (ICD)。为了显式地对结构和关系数据进行建模,方法已经开始使用 GNN。Shang et al. (2019) 提议将 Graph Attention (Veliˇckovi'c et al., 2018) 运算符与架构结合使用,以在两个本体上预训练嵌入。
其他工作在具有不同类型节点的异构图上学习(Lu et al., 2021a;毛等人,2022 年;Gong et al., 2021)。Lu et al. (2022) 构建了一个全球疾病图,以及动态的局部(单次访问内)子图。Choi 等人 (2020) 专注于单次就诊中的 EHR 结构。最后,Lu et al. (2021b, 2019) 考虑了医学本体的双曲嵌入。习得的嵌入然后可以将 dings 合并到特定于任务的架构中(Rasmy et al., 2021;Shang et al., 2019;Lu et al., 2021a; 马 et al., 2018) 来改善不同医疗保健环境中的结果预测。
以前的方法确实考虑了特定于数据集的结构,例如 EHR(患者、就诊等)的分层组织以及来自本体的共现信息或结构。然而,探索的本体集通常保持较小,并且大多数是树状结构。据我们所知,之前没有工作考虑过直接在复杂的大规模本体论(如 UMLS 元词库)及其中的全套非结构化关系信息之上使用 GNN。
此外,虽然以前的工作考虑了多种模式,但他们使用融合方法来连接模式,这些模式往往依赖于更大的架构,因此需要更多的数据来有效训练。我们的工作建议将 UMLS 元词库上的学习知识表示用作来自结构化(计费代码)和非结构化模态(临床报告)的信息的单个共享潜在空间。
- 词汇表
我们考虑多个患者的 EHR 数据集,并提出以下术语:
・患者: ndexed by i
访问:患者 有一次或多次访问 由 t 索引。一次访问包含一组医学概念 数据集上的医学概念总集是 。一个医学概念可以有不同的类型,我们通过索引 1 来区分它们
疾病:由 d s.t. 和 索引疾病概念的集合
– 药物:(或处方)与 m 型,类似于我们引入的疾病 和
临床报告的概念:从文本数据中提取的一组医学概念(临床报告,第 4.2 节)。来自文本 的考虑医学概念的总数,其中集合 是从患者 i 的特定访问 t 的所有报告中收集的。type 为 n 表示文本注释。
考虑特定类型 #\## 的访问的向量表示形式为 。
・本体论:每个本体都有一个医学概念 c 的词汇 ,并使用边集 定义词汇概念之间的一些关系,它构成了本体图 。我们考虑以下本体 / 数据库:
- (国际疾病分类),其中
– GAT C(解剖治疗化学分类),其中
(统一医学语言系统),其中
・模态:我们在这项工作中利用了两种 EHR 数据模式:结构化和非结构化 EHR。我们认为以表格形式提供的计费代码信息是结构化的 EHR,而临床记录是非结构化 EHR 的一种形式。
- 方法
该架构由 3 个主要组件组成(图 1 提供了概述)。
1:模型架构棕色箭头表示信息流(第 4 节); 访问信息 D217E1AA-661A-4016-9DAA-B1F49CB35AA6 介绍了概念嵌入 (第 4.1 节),表示由 (第 4.3 节)聚合,然后由预训练单次访问模型和下游序列模型(第 4.4 节)使用。数据提取如图 A 所示,图 4。
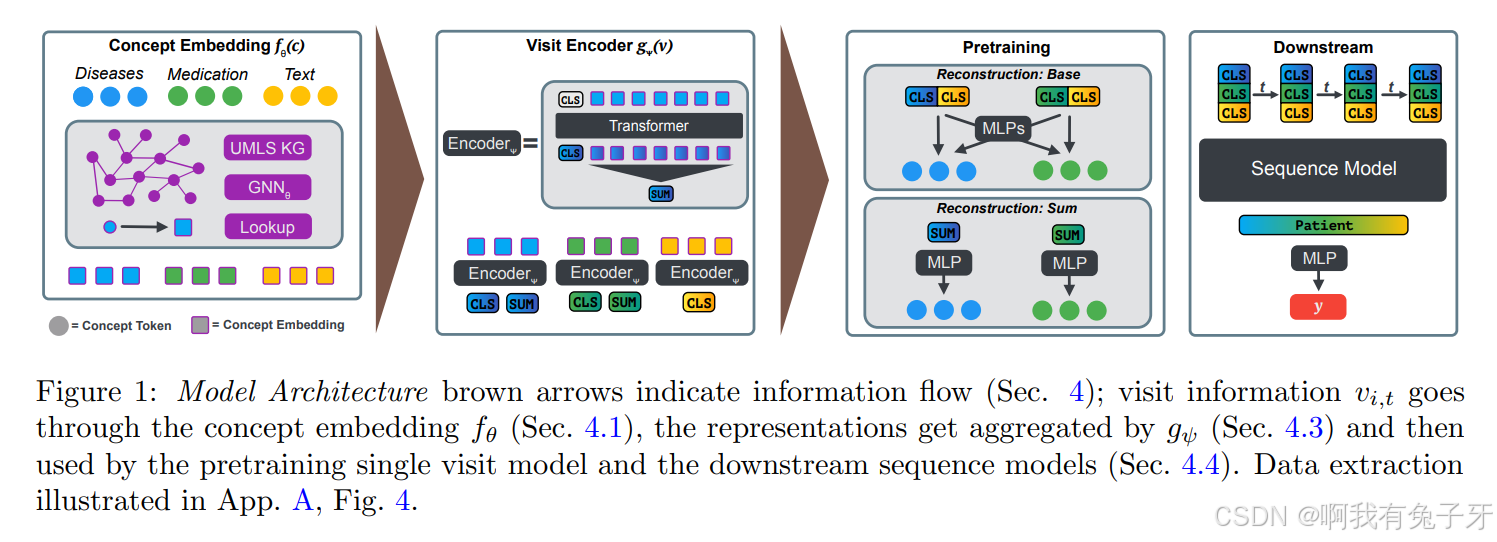
・概念嵌入模块 (由 θ 参数化),它计算任何给定医学概念 的表示
・访问编码模块 假设 和 考虑的概念类型的数量(文本中带有或不带有概念的疾病和药物),然后 (由 ψ 参数化),给定单次访问 计算其每种不同类型的标记的单个表示。
・Predictor 模块,可对单次访问执行预训练任务,或在一系列访问中执行下游微调任务。无论哪种情况,此模块都会从上一次访问编码模块接收患者每次访问的表示形式。
在以下小节中,我们介绍了概念嵌入模块(第 4.1 节),介绍了我们如何从临床报告中提取更丰富的概念(第 4.2 节),对信息进行编码(第 4.3 节)并执行预测(第 4.4 节)。
4.1. 概念嵌入
我们提出了我们的新方法,即依靠 UMLS 元词库作为统一的概念空间来学习基于多种模态的数据库中存在的任何一般医学概念的表示。鉴于此,我们将我们的方法称为多模态 UMLS 图学习 (MMUGL)。
为了限制我们从数据库中考虑的概念数量,我们使用 EHR 数据集中存在的临床报告集,例如 MIMIC-III(Johnson 等人,2016 年)。使用提取管道(第 4.2 节),我们收集了一组医学概念 。最终词汇包括疾病和药物 C(m) \cup C(n)}=C=V_{U M L S},用于通过提取词汇表中完全包含的 UMLS 中的所有边缘来构建 GUMLS。
在 UMLS 中,许多概念都使用简短的自然语言描述进行批注。我们使用 SapBERT (Liu et al., 2021a),这是一种经过微调的语言模型来表示 UMLS 概念,来初始化这些描述中的节点嵌入(附录 B.2 中的消融)。这以两种方式做出贡献: (i) 通过不使用可训练的嵌入,我们减少了给定大量词汇量 VUMLS 的大量自由参数 (ii) 我们通过考虑概念描述来整合先前的医学知识。然后,我们在提取的图上训练一个多层 GNN:
为了检索一个概念,我们返回其计算得到的节点嵌入。我们还发现,在同一图上考虑两个不同的 GNN 层堆栈并执行一个操作对性能有益
我们考虑两个基线图。首先是 ICD 和 ATC 层次结构 ICD/ATC 的元组(Shang et al., 2019),其次是它的扩展,包括共现信息 (例如 Lu et al. (2021a))。更多详细信息请参阅附录 A.3.2。此外,我们通过将概念嵌入替换为嵌入矩阵(参见 App. A.6.6)来考虑无结构基线,该矩阵在没有图形连接的情况下学习每个概念的表示。
4.2. 概念提取
我们方法的目标是包括来自其他模式的数据,例如在 EHR 数据集中发现的临床报告。MMUGL 基于 UMLS 知识学习医学概念的模态不可知表示。它将离散代码信息(例如 ICD 代码)与从文本中提取的医学概念融合在一起。使用 QuickUMLS 提取(Soldaini 和 Goharian,2016 年)根据该特定就诊的临床报告集合,产生了一组医学概念 。此外,我们使用 NegEx 执行基于规则的否定提取(Chapman et al., 2001); 对于每个概念,我们提取一个二进制特征,无论它是否被否定,并将其与其学习的概念嵌入(方程 1)连接起来。这是一项至关重要的信息,因为临床报告都可以提及某种情况的存在或不存在。
4.3. 访问 Encoder
访问编码器 依赖于已建立的 Transformer 架构(Vaswani et al., 2017)。我们
使用学习的 CLS 令牌,并且没有位置编码,这用作集合聚合函数。对于给定访问中的每种概念类型,我们使用相同的(权重共享)Transformerψ 对单独的表示形式进行编码,参数 ψ 其中 。串联表示 编码访问: 我们可以省略临床报告(方程 4)中的多模态信息,例如,在我们使用更简单的基线图的情况下,例如 (附录方程 12)或在没有 的 MMUGL 中。FAD2BF0A-95A8-4508-BE55-A38B739381BF
4.4. 预测变量和训练
下面,我们将介绍预训练模块和下游微调模块。
4.4.1. 预训练模块
我们扩展了 Shang 等人(2019 年)开发的自动编码预训练方法,使用重建损失 ,并使用不同的多层感知器 执行四种不同的预测(从疾病和处方两种类型中的每一种,作为来源到作为标签),从类型的表示中预测类型・),并附加二进制交叉熵损失 来建模多标签分类。
在预训练期间,我们在方程 2 的输入处随机屏蔽和替换标记(受掩码语言建模的启发(Devlin et al., 2019))。
加权重建预训练 我们考虑方程 5 的加权版本:
一些下游任务侧重于疾病诊断。因此,我们考虑一种量身定制的以疾病为中心的预训练方法。在这种情况下,我们省略了对药物的预测(和损失信号),只从就诊聚合疾病或药物表示中预测疾病。含义我们设置
对这种适应性能的贡献在第 6 节和附录 B.5 中介绍。
Sum Aggregation Loss 由于疾病和药物分布的强烈不平衡,我们探索了额外的损失成分,以防止注意力机制过度拟合到最常见的代币。我们没有采用 CLS 令牌表示形式,而是取除 CLS 之外的所有令牌的总和,并使用 再次解码这个无偏聚合,以预测疾病或处方集 (1) 的集合差异): 这个想法是确保更公正的聚合,同时仍然允许令牌交互并插补掩盖或缺失的信息。 通过这种方法,我们可以在注意力机制中诱导更分散的分布(App. B.4)。
临床报告中的概念 在我们的方法 MMUGL 中,我们考虑了从文本(临床报告)中提取的其他医学概念,并将这些概念的聚合表示连接起来,以便进行相应的访问 到预测变量 的输入处的两种模态中的每一种。例如,在 的情况下:
预训练 的最终损失是 (方程 5、6、8)和 (方程 7)的组合:
其中配置为具有超参数 λ 的正则化器(我们在第 B.4 节中提供了消融)。
4.4.2 下游模块
这项工作的贡献在于从多个模态中学习知识图谱上的概念表示。我们考虑了两个先前的架构来执行时间序列建模,并保持它们基本不变。我们没有提出新颖的下游架构,而是旨在通过学习更健壮和有意义的医学知识图谱表示及其聚合来单独展示性能改进。
心力衰竭该任务已在 CGL(Lu et al.,2021a)、Chet(Lu et al.,2022)和 Sherbet(Lu et al.,2021b)中进行了基准测试;他们对先前的工作进行了广泛的基准测试。我们运行他们提供的预处理并提取使用的目标代码集以及计算的患者分裂。使用分数和接收器操作员曲线 AuROC 下的面积来评估二分类。
对于药物推荐,我们采用了尚等人(2019)使用的历史上的平均池化方案。对于所有其他任务,我们使用 Lu 等人(2021a)提出的基于 RNN 的模型。更多细节见附录 A.3.1。
诊断类似于之前的心力衰竭任务我们与Chet 和 Sherbet 的结果进行比较。我们通过在每个存储库中运行提供的预处理来提取目标代码集和患者分裂,以确保可比性。我们考虑阈值加权评分,并与 Lu 等人(2021a)相媲美。我们考虑他们对的适应计算。通过考虑每个样本的地面实况阳性标签的数量,该变体略微膨胀。这避免了设置阈值的需要,但泄露了评估的基础事实阳性的数量;我们将其称为我们还在前 k 个预测中报告召回(根据模型置信度);称为 R@k(例如 R@20)。
5. 实验设置
我们在 MIMICIII(Johnson 等人,2016 年)数据集(1.4 版)上进行实验。药物使用尚等人(2019 年)共享的方法映射到 ATC 层次结构。对于预训练,我们考虑了各自基线的训练分割以及仅进行一次访问的未使用患者,因此不适合微调序列任务。我们考虑了五个不同的下游任务,所有这些任务都使用(二进制)交叉熵(二进制 / 多标签 / 多类)进行了训练。这些表格显示了在三个种子训练运行中具有标准差的测试集性能,我们以粗体突出显示了最佳结果。在附录 A.1、A.3、A.4 和 A.5 中,我们共享了数据、训练、架构和任务细节。
训练过程建议的预训练与任务无关,并且对于所有下游任务都是相同的。
在预训练之后,概念嵌入的参数(第 4.1 节,知识图谱上的 GNN)没有针对特定任务进行微调。这有助于提高我们方法的效率,因为我们可以实现所有提议的性能增益,而无需针对特定任务重新训练大型知识图谱 GNN。只有特定任务的架构组件和访问编码器(第 4.3 节)被微调。
再入院对于给定的患者病史,我们在时间 t 定义视界 h 的再入院任务,并在时间将目标定义为-(紧急)再入院在临床上高度相关,如苏格兰全国部署此类系统所示(Liley et al.,2021)。我们使用 AuROC 评估性能。
停留时间我们使用包含 10 个类别的多类方法进行停留时间预测(LoS)(Yang et al.(2023))。0 用于 1 天以下的停留,1-7 用于相应天数的停留,8 用于 1 至 2 周的停留,9 用于 2 周以上的停留)。
6. 结果与讨论
药物推荐我们的方法和训练方法可以优于尚等人(2019)先前发表的最先进的结果(见表 1)。我们注意到,来自临床报告的医学概念的多模态方法无法改进这项任务和数据分割(患者在可用临床报告的丰富性方面有很高的差异);另见附录 B.1。
疾病任务在表 2 中,我们展示了两个与疾病相关的任务(第 5 节)的基准测试结果。我们通过考虑三个不同的先前工作实现来训练和评估我们的模型,这些工作实现已经执行了
对以前最先进的方法进行广泛的基准测试。
总体而言,我们可以总结出针对使用预训练方案(Lu et al.,2021b)的方法的改进性能,包括文本数据(Lu et al.,2021a)、双曲嵌入(Lu et al.,2021b)、本体论图(Choi et al.,2017;尚等人,2019;毛等人,2022)、时间本地化图(Lu et al.,2022)、个性化患者图(Yes et al.,2021)和语言模型知识图(江等人,2023)。
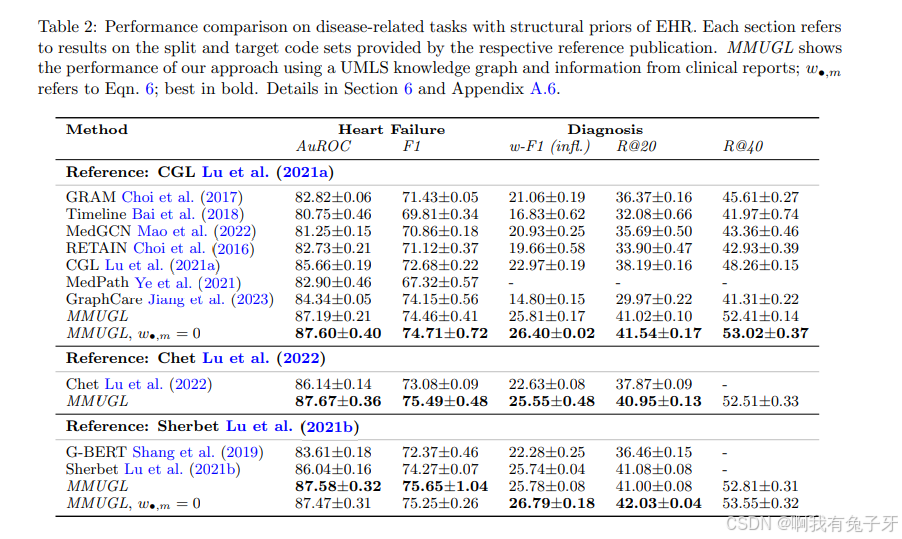
概念嵌入消融在表 3 中,我们显示了不同类型概念嵌入的消融(第 4.1 节)。所有方法都使用我们提议的管道进行训练,并且只替换了概念嵌入模块。我们的 MMUGL 从来自临床报告的更丰富的多模态信息中受益匪浅,因此优于以前的工作(多模态方法还可以增加鲁棒性,包括缺失和错误信息,附录 F)。我们可以通过使用以疾病为中心的预训练来针对下游任务定制预训练来看到进一步的改进(Eqn.6 与)。
我们通过替换 Concept Embedding 4.1 模块并执行相同的建议训练过程,比较了两种没有 GNN 的替代方法来学习概念嵌入。正如 Lee 等人(2021 年)所提出的,我们使用 Node2Vec(Grover 和 Leskovec,2016 年)预训练我们的概念嵌入。其次,我们与 Cui2Vec(Beam 等人,2020 年)进行比较。Cui2Vec 由使用 Word2Vec(Mikolov 等人,2013 年)风格的目标函数在大规模语料库上预训练的医学概念嵌入组成。我们表明,在 100,000 个节点和大约 30,000 名患者的规模上使用我们的图进行预训练,我们可以与使用 6000 万患者顺序的训练数据、2000 万临床笔记和 170 万生物医学期刊文章的方法竞争或优于该方法。
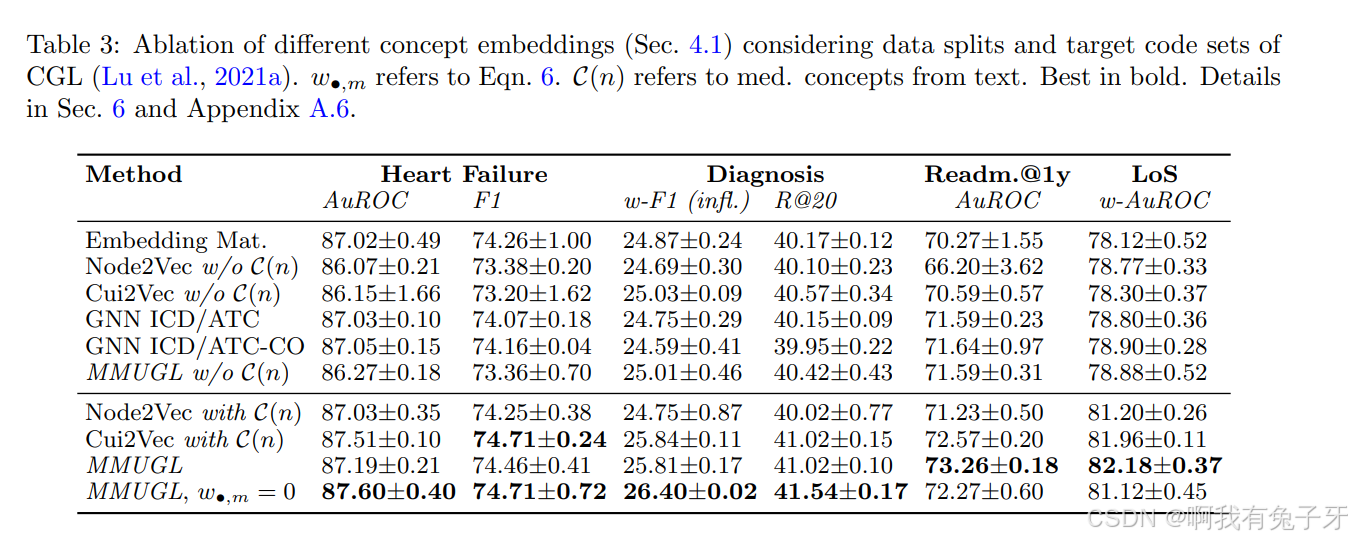
我们的方法使用来自临床报告的更丰富的信息和更大的概念词汇表,而不引入新的参数。此外,我们的方法基于先验知识,并且比以前仅基于个体本体的工作更通用。重新接纳我们在不同的视野中对再入院进行基准测试,并在更大的视野中观察到我们的多模态知识图谱的影响越来越大(图 2)。MMUGL 组合图结构和多模态统一潜在空间因此与长期风险预测越来越相关。
表 3 显示了相关 1 年范围内的性能(Liley 等人,2021 年)。在 15 天的范围内,我们使用语言模型增强知识图(GraphCare,江等人,2023 年)的最新结果,该图在 MIMIC-III 上报告了 69.0 的 AuROC,其中 MMUGL 的平均 AuROC 为 73.69(MMUGL 的平均 AuROC 为 71.93,w/o
)。Park 等人(2022 年)的 MedGTX 是一个大型融合架构,他们报告说,在 30 天的时间范围内,我们以高效的共享潜在空间超越了这一结果,并在 MMUGL 上实现了 45.27(在 MMUGL 上实现了 45.57,没有 C(n))。
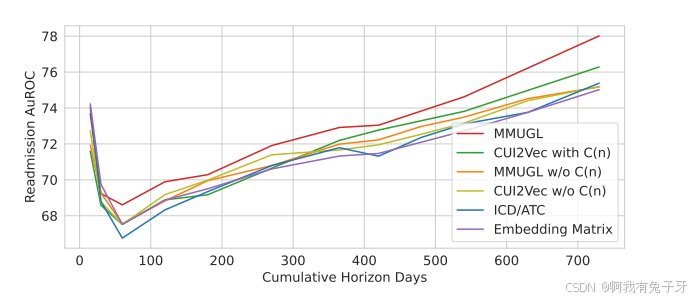
图 2:不同概念嵌入在增加累积视野时的再入院预测。
总结在表 4 中,我们总结了每个基准任务的不同组件的性能优势。我们可以得出结论,预训练(第 4.4.1 节)以及我们提出的知识图谱概念嵌入(第 4.1 节)都提高了所考虑任务集的性能。我们进一步注意到特定疾病预训练对心力衰竭或诊断等任务的相关性。
可解释性在共享潜在空间上使用访问编码器中的转换器(第 4.3 节),我们可以通过分析注意力分数来了解经过训练的模型如何利用不同的模式来执行预测。这些分数可以向临床医生突出使用的相关医学概念对于预测。在附录 E、C 和 F 中,我们展示了这种分析的示例
【
附录 C. 临床报告概念类别分布
我们可以使用注意力机制来解释患者水平上的结果,对诊断和药物进行排名,以及临床报告中的一般医学概念对预测的重要性。这种分析的一个例子在附录 E 中。
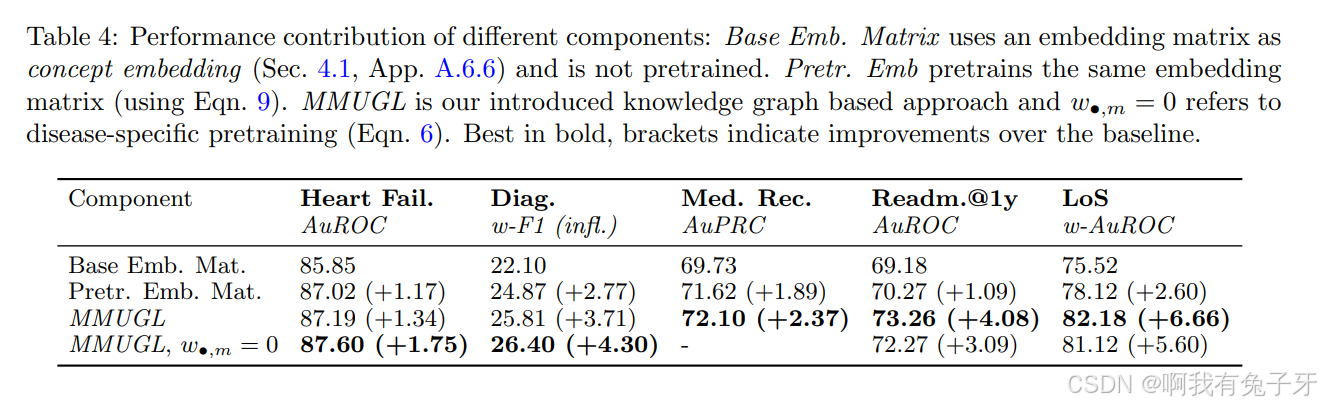
我们还可以执行各种数据集全局分析我们分析从临床报告中提取的医学概念的分布 w. r.t.MIMICIII 报告类型并将结果呈现在图 6(a)中;请注意对数 y 标度(附录 C 也显示了线性标度)。经过预训练,我们可以看到数据集的类型分布发生了非常强烈的转变
朝向出院总结。这是明智的,因为预训练任务是一个自动编码器,本质上是为总结访问而训练。通过对特定任务进行微调,我们可以看到向更具体的报告类型的轻微转变,这有助于为给定任务提供更详细的见解;例如,注意呼吸类别的焦点是如何随着我们对一般诊断进行微调而增加的,但低于心力衰竭预测的预训练水平。
在 MIMIC-III 中,呼吸系统类型的临床报告大多是高度结构化的状态报告,评估患者与呼吸系统的状态。作为结构化报告,有大量匹配的医学概念,这些概念对应于结构化报告的字段名称,以填写患者信息,此外,表格中提供的大多数评估在患者之间没有太大差异。因此,从这些报告中提取的许多医学概念在患者之间没有区别,因此我们观察到对
训练模型后从这些报告中提取的标记。
附录 E. 单个患者的可解释性
在图 7 中,我们展示了如何使用就诊编码器的注意力分数(第 4.3 节)来提供我们预测的可解释性的各种方式。我们在 MIMIC-III(Johnson 等人,2016 年)数据集中提供了患者 1784 访问 121518 的示例分数分析。患者被分配了以下一组代码:
ICD: 519.1、496.0、414.01、401.9、443.9、V45.82
ATC4: N05CD、A02BC、B01AB、A06AD、C07AB、B05CX、G04CA、A07EA
分数可用于突出显示最相关的疾病和药物(图 7(a))。通过对单个代码的分数进行分组并计算每组的聚合(例如分数的第 90 百分位数),我们可以突出显示该患者在给定就诊中最相关的疾病和药物类别。
我们可以通过计算每个报告中所有匹配概念的分数的聚合分数来进一步提取在整个访问期间收集的报告中哪些包含最具预测性的标识符(图 7(a))。
在(图 7(b))中,我们突出显示了注意力得分最高的两个排名最高的报告中的概念。
我们可以看到不同模式的得分是一致的,例如考虑到疾病(ICD)代码的呼吸类别的高分(图 7(a)),以及临床报告中发现的概念的高分(例如注:放射学 0 中的 C0948187(气管软化)或注:放电摘要: 0 中的 C0189436(隆胸重建);图 7(b))与呼吸条件相关。我们可以得出结论,对于这个样本,统一的概念潜在空间促进了模式之间的一致性,并且可以提高可解释性。
附录 F. 稳健性 w. r.t. 缺少信息
在图 8 中,我们显示了一个实验的结果,其中我们逐步屏蔽了更大比例的不同模式的输入令牌。这是通过用掩蔽语言建模风格预训练期间使用的 MASK 令牌替换相应的令牌标识符来完成的。
令牌可以被随机屏蔽,或者我们根据访问编码器中分配给它们的注意力分数对它们进行排序。y 轴显示预训练性能 w. r.t 到 Eqn。5;从任一访问表示中解码到两种模式(疾病、药物)中的任何一种。
结果表明,虽然自动编码目标只制定了 w. r.t. 疾病和药物标记,但附加的文本信息
可以成功地防止更强的性能衰减,并帮助归咎于丢失或不正确的信息。
我们可以进一步看到,根据注意力分数屏蔽令牌会导致性能的整体下降更快,这突出了使用基于注意力的编码器的好处,该编码器可以在编码患者当前状态时专注于相关的医学概念。
】
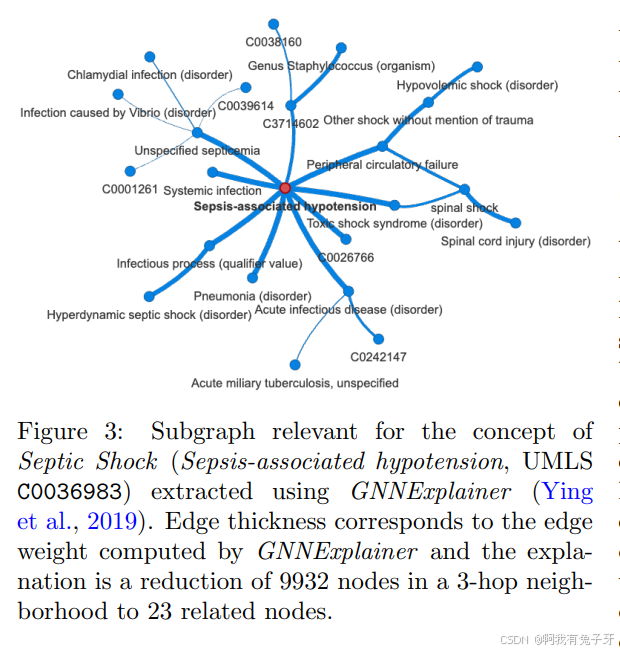
我们可以利用经过训练的知识图谱,为以重要概念为中心的临床医生提供更丰富的解释。例如,败血症休克的概念(UMLS C0036983)连接到 3 跳邻域中的 9932 个节点。使用 GNNExplainer(英等人,2019),我们可以检索相邻矩阵上的软掩码([0,1] 中的条目),它表示一个边缘加权的解释子图。通过对这个掩码进行阈值化,我们可以检索一个显式的子图解释,其中用户(例如临床医生)可以通过调整阈值参数来控制子图的大小。图 3 显示了一个围绕败血症休克的解释图,有 23 个节点。解释子图旨在减少重构在 GNNExplainer 使用的正则化约束下,使用子图或完整知识图的概念嵌入之间的误差。
图 3:使用 GNNExplainer 提取的与败血症休克(败血症相关低血压,UMLS C0036983)概念相关的子图。边缘厚度对应于 GNNExplainer 计算的边缘权重,解释是将 3 跳邻域中的 9932 个节点减少到 23 个相关节点。
【
关于 GNNExplainer(英等人,2019)
- 背景:GNNExplainer 是一种特定的工具或方法,由英等人在 2019 年提出。它主要应用于图神经网络(Graph Neural Networks,简称 GNN)相关领域,其目的是为了对 GNN 的预测结果等进行解释,让用户能够更好地理解 GNN 模型在做决策时所依据的关键信息。
检索相邻矩阵上的软掩码
- 相邻矩阵:在图相关的概念中,相邻矩阵(Adjacency Matrix)是一种用于表示图中节点之间连接关系的矩阵。如果图中有 n 个节点,那么相邻矩阵就是一个 n×n 的矩阵,其中矩阵中的元素(通常是 0 或 1 等)表示相应两个节点之间是否有边相连。例如,若节点 i 和节点 j 之间有边相连,那么相邻矩阵中第 i 行第 j 列(以及第 j 行第 i 列,在无向图情况下)的元素就会被标记为 1(表示相连),否则标记为 0(表示不相连)。
- 软掩码:这里提到的软掩码(Soft Mask)是在相邻矩阵基础上得到的。它是一个矩阵,其中的条目取值范围在 [0, 1] 之间。这个软掩码的意义在于它以一种 “软性” 的方式来表示图中边的重要性或者相关性等信息。与普通相邻矩阵中简单用 0 和 1 表示边是否存在不同,软掩码中的值可以理解为边存在的一种 “程度” 衡量,比如 0.5 可能表示某条边在某种程度上对模型的决策有一定影响,但又不像取值为 1 那样表示是绝对关键的边。通过 GNNExplainer 的相关算法和操作,我们可以从相邻矩阵中检索出这样的软掩码,它实际上是对图中边的一种重新加权和细化的表示,用于后续对模型决策依据的分析。
- 【软掩码具体是如何获得的?
- 通过 GNNExplainer 算法
- 模型训练与特征提取:GNNExplainer 是基于图神经网络(GNN)的架构。首先,图神经网络会对输入的图数据进行训练。在这个过程中,GNN 会学习到图中节点的特征表示以及节点之间边的关系。这些特征和关系是通过对大量的图数据(例如包含多个节点和边的网络结构,可能是社交网络、分子结构等)进行学习得到的。
- 关联计算与软掩码生成:在 GNN 训练完成后,GNNExplainer 利用 GNN 的中间结果来计算软掩码。它会考虑节点特征、边的连接关系以及 GNN 的预测目标(例如对节点分类、图分类等任务的预测结果)之间的关联。
- [我觉得这里可以针对医疗任务做一个定制]
- 具体来说,它可能会通过计算节点特征和边的相关性得分来生成软掩码。例如,对于一条边连接的两个节点,它会根据这两个节点的特征向量在 GNN 中的传播和融合过程,计算这条边对于最终预测结果的潜在贡献程度。这个贡献程度就会被量化为软掩码中的一个值,取值范围在 [0,1] 之间。
- 优化目标导向:软掩码的生成过程通常是有优化目标的。这个优化目标可能是为了最大化解释子图与原始模型预测结果之间的一致性。也就是说,软掩码所确定的子图(即使是经过软加权的子图)应该尽可能地能够反映原始 GNN 模型做出预测的依据。例如,在一个节点分类任务中,软掩码所表示的子图应该能够突出那些对于将某个节点分类到特定类别起关键作用的边和节点。
- 基于信息传播和重要性评估机制
- 信息传播路径分析:在图中,信息(如节点特征)是通过边在节点之间传播的。GNNExplainer 会分析这些信息传播路径,识别出对最终结果有重要影响的路径。对于每条边,它会评估其在信息传播过程中的重要性。例如,在一个分子结构的图中,原子之间的化学键(边)在传递化学性质(节点特征)方面有不同的作用。有些化学键可能对于确定分子的某种活性(预测目标)起着关键的信息传递作用,这些化学键对应的边在软掩码中的值就会比较高。
- 重要性评估方法:可以采用多种方法来评估边的重要性。一种常见的方法是基于梯度计算。在 GNN 模型中,通过计算预测结果对边的参数(例如边的权重)的梯度,来衡量边的重要性。梯度较大的边表示其对预测结果的变化比较敏感,在软掩码中的值可能就会较高。另一种方法是基于扰动分析,即对边进行微小的改变(如删除或修改边的权重),观察对 GNN 模型预测结果的影响。影响较大的边在软掩码中会被赋予较高的值。
- 通过 GNNExplainer 算法
- 】
通过阈值化获取显式子图解释
- 阈值化操作:在得到软掩码后,我们会对这个软掩码进行阈值化处理。阈值化就是设定一个特定的阈值(Threshold),比如 0.3,然后将软掩码中所有大于等于这个阈值的条目保留(通常将其值设置为 1),而将小于这个阈值的条目舍去(通常设置为 0)。这样,通过选择不同的阈值,软掩码就会被转化为一个新的矩阵,这个新矩阵就相当于一个经过筛选和简化的相邻矩阵,它只保留了那些被认为在当前设定阈值下相对重要的边。
- 显式子图解释:经过阈值化处理后的新矩阵,实际上就定义了一个显式的子图(Explicit Subgraph)。这个子图是原始图的一部分,它由那些在阈值化操作后保留下来的边以及这些边所连接的节点组成。这个显式子图就为我们提供了一种关于 GNN 模型决策依据的解释,因为它展示了在特定阈值条件下,哪些边和节点的组合对于模型的决策可能是最为重要的,也就是从原始图中提炼出了一个相对关键的部分来展示模型所依据的信息。
用户可控制子图大小
- 调整阈值参数:这里提到用户(例如临床医生等)可以通过调整阈值参数来控制子图的大小。因为不同的阈值会导致不同的边被保留或舍去,从而形成不同大小的子图。如果阈值设置得比较高,比如 0.8,那么可能只有很少的边能够满足大于等于这个阈值的条件,这样得到的子图就会比较小,只包含那些对模型决策影响非常大的边和节点;相反,如果阈值设置得比较低,比如 0.2,那么会有更多的边满足条件,得到的子图就会比较大,包含了更多相对重要的边和节点。所以用户可以根据自己的需求和对模型理解的深度等因素,灵活地调整阈值参数,从而获取到大小合适、能够更好地帮助自己理解模型决策依据的显式子图解释。
】
7. 结论
我们引入了一种新颖的参数有效的方法来训练来自多个模态的通用医学知识的统一潜在空间。我们通过将我们的表示与来自 UMLS Metathes 库的先验知识接地来证明了下游任务的改进性能。我们扩展的预训练方法和相应的结果强调了其在解决医学领域监督标签稀缺性方面的重要性。更通用的医学概念表示方法可以适应异构多模态 EHR,而无需复杂的融合架构。未来的工作可以探索实验室测试或程序代码的集成。最后,更通用的医学概念嵌入可以消除在不同系统之间执行映射的需要,只要存在到 UMLS 的映射。
我们的研究结果为未来的研究铺平了道路,以弥合就诊内建模(例如,ICU 时间序列模型(Harutyunyan et al.,2019))和跨就诊建模之间的差距,例如我们在这项工作中进行的基准测试。尽管疾病和药物代码通常是在就诊后分配的(用于计费或存档目的),但许多临床报告是在患者住院期间生成的。为了提供更丰富的上下文信息,未来的就诊内模型可能包括患者历史和我们的全球概念表示中捕获的多模式知识。
谢
该项目得到了瑞士联邦理工学院(ETH Domain)战略重点领域 “个性化健康和相关技术(PHRT)” 的赠款 #2022-278 的支持。
此外,我们要感谢 Hugo Y'eche 在修订过程中的反馈。感谢 Jonas Bokstaller 和 Severin Husmann,他们的论文提供了相关的见解。
机构审查委员会(IRB)这项研究在进行的国家不需要 IRB 的批准。
参考文献
艾米丽・阿尔森泽、约翰・墨菲、威廉・博格、翁伟雄、迪・金迪、特里斯坦・瑙曼和马修・麦克德莫特。公开可用的临床 BERT 嵌入。在第二届临床自然语言处理研讨会论文集,第 72-78 页,明尼苏达州明尼阿波利斯,美国,2019 年 6 月。计算语言协会。doi:10.18653/v1/W19-1909。网址 https://aclanthology.org/W19-1909。
叶木超,崔宿涵,王亚庆,罗俊宇,曹晓,马凤龙。Medpath:通过医学知识路径增强健康风险预测。在 2021 年网络会议论文集,WWW'21,第 1397-1409 页,美国纽约,2021 年。国际计算机学会。ISBN9781450383127. doi:10.1145/3442381.3449860。网址https://doi.org/10.1145/3442381.3449860。
Muchao Ye, Suhan Cui, Yaqing Wang, Junyu Luo, Cao Xiao, and Fenglong Ma. Medpath: Augmenting health risk prediction via medical knowledge paths. In Proceedings of the Web Conference 2021, WWW ’21, page 1397–1409, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450383127. doi: 10. 1145/3442381.3449860. URL https://doi.org/ 10.1145/3442381.3449860.
英智涛、迪伦・布尔乔亚、尤佳轩、玛丽卡・齐特尼克和朱尔・莱斯科维克。Gnn 解释者:生成图神经网络的解释。在 H. Wallach、H.Larechelle、A.Beygelzmer、F.d'Alch'e-Buc、E.Fox 和 R.Garnett 中,编辑,《神经信息处理系统进展》,第 32 卷。Curran Associates,Inc.,2019。URL https:// 程序。neurips.cc/paper_files/paper/2019/file/d80b7040b773199015de6d3b4293c8ff-Paper.pdf。
Zhitao Ying, Dylan Bourgeois, Jiaxuan You, Marinka Zitnik, and Jure Leskovec. Gnnexplainer: Generating explanations for graph neural networks. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch´e-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings. neurips.cc/paper_files/paper/2019/file/ d80b7040b773199015de6d3b4293c8ff-Paper. pdf.
常路,田汉,岳宁。基于动态疾病图转移函数的上下文感知健康事件预测。AAAI 人工智能会议论文集,36(4):4567-4574,2022 年 6 月。doi:10.1609/aaai. v36i4。20380。网址Proceedings of the AAAI Conference on Artificial Intelligence文章 / 视图 / 20380。
Chang Lu, Tian Han, and Yue Ning. Contextaware health event prediction via transition functions on dynamic disease graphs. Proceedings of the AAAI Conference on Artificial Intelligence, 36 (4):4567–4574, Jun. 2022. doi: 10.1609/aaai.v36i4. 20380. URL https://ojs.aaai.org/index.php/ AAAI/article/view/20380.
毛玉清和冯建华。使用单词和图嵌入来衡量统一医学语言系统概念之间的语义相关性。美国医学信息学协会杂志,27(10):1538-1546,10 2020。ISSN 1527-974X。doi:10.1093/jamia/ocaa136。URLUse of word and graph embedding to measure semantic relatedness between Unified Medical Language System concepts | Journal of the American Medical Informatics Association | Oxford Academic。
田白,张珊珊,布赖恩・埃格尔斯顿和斯洛博丹・武契奇。通过捕捉疾病随时间的进展来进行医疗保健的可解释表示学习。在第 24 届 ACM SIGKDD 知识发现和数据挖掘国际会议论文集,KDD'18,第 43-51 页,纽约,纽约,美国,2018 年。国际计算机学会。ISBN9781450355520。
Tian Bai, Shanshan Zhang, Brian L. Egleston, and Slobodan Vucetic. Interpretable representation learning for healthcare via capturing disease progression through time. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’18, page 43–51, New York, NY, USA, 2018. Association for Computing Machinery. ISBN 9781450355520.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









