










IOS Press Ebooks - Aggregating UMLS Semantic Types for Reducing Conceptual Complexity
问题
领域的概念复杂性使得信息系统用户难以理解和与系统中的知识进行交互,UMLS 语义网络虽能降低复杂性,但对于某些目的,可能需要更粗粒度的语义类型分组12。
挑战
- 部分概念逻辑上属于多个语义组,如腺瘤既是解剖异常(可能需手术切除)又是疾病(有预后和潜在并发症)。
- 由于错误或不一致的语义类型分配,如 “肾小球滤过率” 被错误分配了 “生理功能” 和 “诊断程序” 两种语义类型,导致其同时属于 “生理学” 和 “程序” 语义组。
- 语义类型之间的既定关系在适当分组时也会造成问题9。
创新点
提出一种基于六项原则聚合 UMLS 语义类型的方法,将 134 种语义类型聚合成 15 组,以创建更粗粒度、更易于理解和使用的语义分组134。
贡献
- 提供了一种降低领域概念复杂性的方法,通过聚合语义类型,使信息系统中的知识更易于理解和交互。
- 提出的语义分组可用于多种目的,如可视化数据、创建词汇表的高级概况、发现领域表示中的不一致性等1410。
提出的方法
- 方法概述:基于六项原则聚合语义类型,包括语义有效性(组内语义连贯)、简约性(组数尽可能少)、完整性(覆盖整个领域)、排他性(每个概念仅属于一组)、自然性(领域专家可接受的表征方式)和实用性(对某些目的有用)。
- 具体操作:检查 1990 年原始语义分组对这些原则的遵循情况,根据分析结果对分组进行调整。在评估语义有效性时,考虑组内类型的层次关系以及语义类型参与的关系;在测试排他性原则时,分析概念被分配到多个语义类型的情况345。
-
这 15 个组是人工划分的。研究人员基于六项原则(语义有效性、简约性、完整性、排他性、自然性和实用性)对 UMLS 的 134 种语义类型进行了审查和调整,从而将其聚合为 15 个组。论文中提到的划分人员主要是 Alexa T. McCray、Anita Burgun 和 Olivier Bodenreider。他们来自美国马里兰州贝塞斯达的美国国立医学图书馆(National Library of Medicine),并且他们的邮箱地址为(mecray,burgun,olivier)@nlm.nih.gov。这些研究人员在论文中详细阐述了他们对于 UMLS 语义类型聚合分组的研究成果,包括提出的原则、方法以及在划分过程中遇到的问题和解决方式等,为降低领域概念复杂性和改进知识表示做出了贡献。
指标
- 语义有效性指标:评估组内类型层次关系及语义类型参与关系的一致性和正确性。
- 排他性指标:确保领域被完全划分,组间无重叠,分析概念在多个语义类型分配下是否违反排他性原则。
模型结构
文中未提及传统意义上的模型结构,主要是对 UMLS 语义类型进行分组,形成一种新的组织结构,如将 134 种语义类型聚合成 15 个语义组,每个语义组包含不同数量的语义类型,涵盖了如活动与行为、解剖学、化学与药物等不同领域概念6。
结论
- 提出的方法能够在一定程度上对 UMLS 进行有效分组,15 个组几乎实现了对 UMLS 的完全划分,大部分概念能被归入唯一一组。
- 语义分组在不同应用场景下具有实用性,如通过对比 UMLS 和 PDQ 中概念分布,展示了语义组可用于创建词汇表的高级概况。
- 该方法可作为一种审核 UMLS 数据正确性和一致性的方式7119。
剩余挑战和未来工作
- 剩余挑战:部分概念的多语义组归属问题难以解决,部分原因是意义本身的性质以及语义类型分配的错误或不一致。
- 未来工作:在 UMLS 背景下进一步研究语义分组如何用于发现领域表示中的不一致性等问题9。
数据集
使用了 UMLS(Unified Medical Language System)数据集,包括其 2000 年发布版本中的 730,155 个概念及其相关语义类型信息,用于评估和构建语义分组。同时提及了 PDQ(Physician Data Query Online System)数据集,用于对比测试语义分组的实用性78。
抽象
一个领域的概念复杂性会使信息系统的用户很难理解这些系统中嵌入的知识并与之交互。Unijfeed 医学语言系统(UMLS)目前集成了来自 50 多个生物医学词汇的 730,000 多个生物医学概念。UMLS 语义网络通过根据分配给它们的语义类型对概念进行分组来降低这种结构的复杂性。然而,出于某些目的,更小的和更粗粒度的语义类型分组集可能是可取的。在本文中,我们讨论了我们创建这样一个集合的方法。我们提出了六个基本原则,然后应用这些原则将现有的 134 种语义类型聚合成一组 15 个分组。我们介绍了我们遇到的一些困难以及我们做出的决定的后果。我们讨论了语义组的一些可能用途,并提出了对实际工作的影响。
关键词:
统一医学语言
系统;知识表示,医学信息学
导言
领域的概念复杂性会使信息系统的用户难以理解这些系统中嵌入的知识并与之交互 [1]。UMLS 语义网络是组织生物医学领域 [2] 中大量概念的高级结构。因此,它有助于阐明领域的结构,这是本体的一个重要属性。Chandrasekaran 指出 [3:21]:
给定一个领域,本体论是该领域任何知识表示系统的核心。没有本体论,或者作为知识基础的概念化,就不可能有词汇
表示知识… Tpo ontoloey 捕获了领域的内在概念结构。
除了允许计算机应用程序对领域中的概念进行推理之外,显式和格式良好的本体论还可以用于各种其他目的。例如,Pratt [4] 已经尝试使用 UMLS 语义类型显示文献搜索结果,皮萨内利等人 [5] 认为本体论可以支持医学中更有效的知识共享,根据分配给每个概念的语义类型对 UMLS 进行划分。顾等人 [6] 和陈等人 [7] 指出,虽然 UMLS 是一种有价值的知识资源,但它的大小和复杂性使其难以理解和可视化。他们开发了划分 UMLS 概念空间的方法来帮助理解。UMLS 知识来源的第一个版本包括 UMLS 语义网络,以及语义类型的广泛分组,以便在名为 MetaCard [8:79,9] 的 HyperCard 应用程序中更容易地显示 MEDLINE 共现信息。下面,我们讨论了我们对这种原始语义类型分组的回顾,包括我们开发的一组原则,以帮助分析和验证。基于这些原则,我们创建了一组经过修订的语义分组,可能对各种目的有用。
方法
我们开发了一个基于以下一般原则将语义类型聚合为少量组的方法论:
1. 语义有效性 —— 组必须在语义上连贯
2. 节约 —— 团体数量应尽可能少
3. 完整性 —— 组必须涵盖整个领域
4. 排他性 —— 领域中的每个概念必须只属于一个组
衡量语义有效性的一种方法是评估一个组中的类型在何种程度上相互关联。这是如此,因为层次结构中的父母和孩子共享基本属性。例如,在下面的图 1 中,任何包含解剖异常的分组,至少作为第一个假设,预计也包括先天异常和后天异常。此外,属于网络不同和遥远分支的语义类型不应该聚集在一起。然而,在某些情况下,这样的分组确实会导致有效的分类。例如,严格来说,语义类型 “身体位置或区域” 是一个概念概念,被归类为 “空间概念” 的子类型。由于身体位置与解剖概念共享许多语义特征,因此 “身体位置或区域” 语义类型实际上与其他解剖类型一起分组。类似地,属于语义网络的同一分支甚至具有相同父级的语义类型可能更好地聚类到不同的语义组中。例如,虽然语义类型 “基因或基因组” 和 “身体部分、器官或器官组件” 都是 “完全形成的解剖结构” 的子类型,但只有前者与语义组 “解剖” 相关联,而后者被放在 “基因和分子序列” 组中。图 1 说明了这种划分。
5. 自然性 —— 群体必须以领域专家可以接受的方式描述领域的特征
6. 效用 —— 这些组必须对某些目的有用 1990 年最初的语义分组被检查以评估它们对六项一般原则的遵守情况。由于创建组的主要动机是在应用程序中可视化数据,效用原则立即得到满足。一旦缓存语义类型被分配到其中一个语义组,完整性原则也自动满足整个 UMLS,因为每个 UMLS 概念都被分配了至少一个来自 network.In 的语义类型,自然性原则得到满足,因为这些分组在应用程序的上下文中被领域专家仔细理解,没有任何额外的留档或培训。最初的集合由 131 个语义类型的少量分组(14 个)组成,因此简约原则也适用。我们仔细审查了分组以遵守剩下的两个原则,语义有效性和排他性,我们根据分析结果对分组进行了一些更改。
语义类型代表内涵或定义知识,而分配给这些类型的 UMLS 概念代表扩展知识。在回顾语义组的成员时,我们不仅查看了
语义类型的定义,以及在 UMLS [10] 2000 版本中分配给这些类型的概念。例如,语义类型 “教育活动” 被定义为 “与教育的组织和提供。然而,在实践中,诸如 “家庭血液透析培训” 之类的概念被分配到这一类型。诸如此类的概念实际上是各种生物医学程序,因此根据语义有效性原则,最好与其他程序聚集在一起。
语义有效性也可以通过分析语义组参与的关系来衡量。例如,当考虑这些概念参与的关系时,将解剖概念组合在一起的结果可以证明具有语义有效性。我们回顾了组内每种语义类型的陈述关系,然后评估了组内和组间关系集的一致性和正确性。例如,一个解剖结构可以连接到另一个解剖结构,它可以是紊乱的位置。这些事实有助于验证将所有解剖结构组合在一起,也可以单独将所有紊乱组合在一起。排他性原则意味着域是完全划分的,组之间没有重叠。UMLS 的划分不仅必须提供不相交的语义类型组,还必须提供不相交的概念组。我们测试了全套 730,000 个概念是否符合排他性原则,并分析了概念被分配到多个语义类型的情况。在许多情况下,多个语义类型不会导致违反排他性原则,因为语义类型被归类在同一组中。例如,大多数化学物质都被分配了结构和功能语义类型。前者与化学品的基本特性有关,后者与它们所扮演的角色有关。(关于这种区别的一些讨论,见 [2 和 11]。)由于结构和功能化学类型被归类在 “化学品和药物” 组中,这并不代表违反排他性 principle.In 在某些情况下,一个概念的多个类型确实会导致该概念被分配到多个语义组。其中一小部分情况无法解决,将在下面讨论。
结果
语义组列表如表 1 所示,以及每个组中 UMLS 概念的数量和百分比。
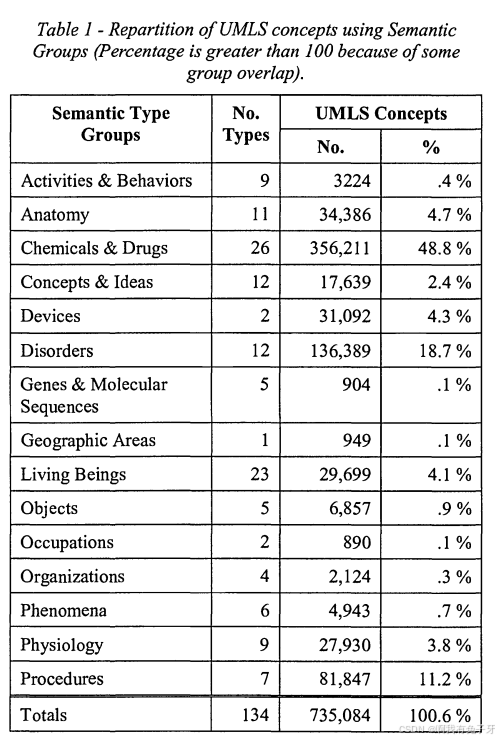
每组概念的数量从 “基因和分子序列” 的 904 个到 “化学品和药物” 的 356,211 个不等。由于少数概念属于多个语义组,表中显示的概念总数超过了 UMLS 中当前的概念数量(730,155 个),总百分比略高于 100%。
这 15 个组几乎实现了 UMLS 的完全划分,因为 2000 年发布的 UMLS 中的 730,155 个概念中有 725,242 个被归类为一个且只有一个组。在剩下的 4913 个概念中,大多数被分配到两组,只有 16 个概念被分配到三组。例如,“染色质” 被分配了 3 种语义类型,“细胞成分” 属于 “解剖学” 组,“遗传功能” 属于 “生理学” 组,“氨基酸、肽或蛋白质” 属于 “化学品和药物” 组。没有一个概念属于 3 个以上的语义组。
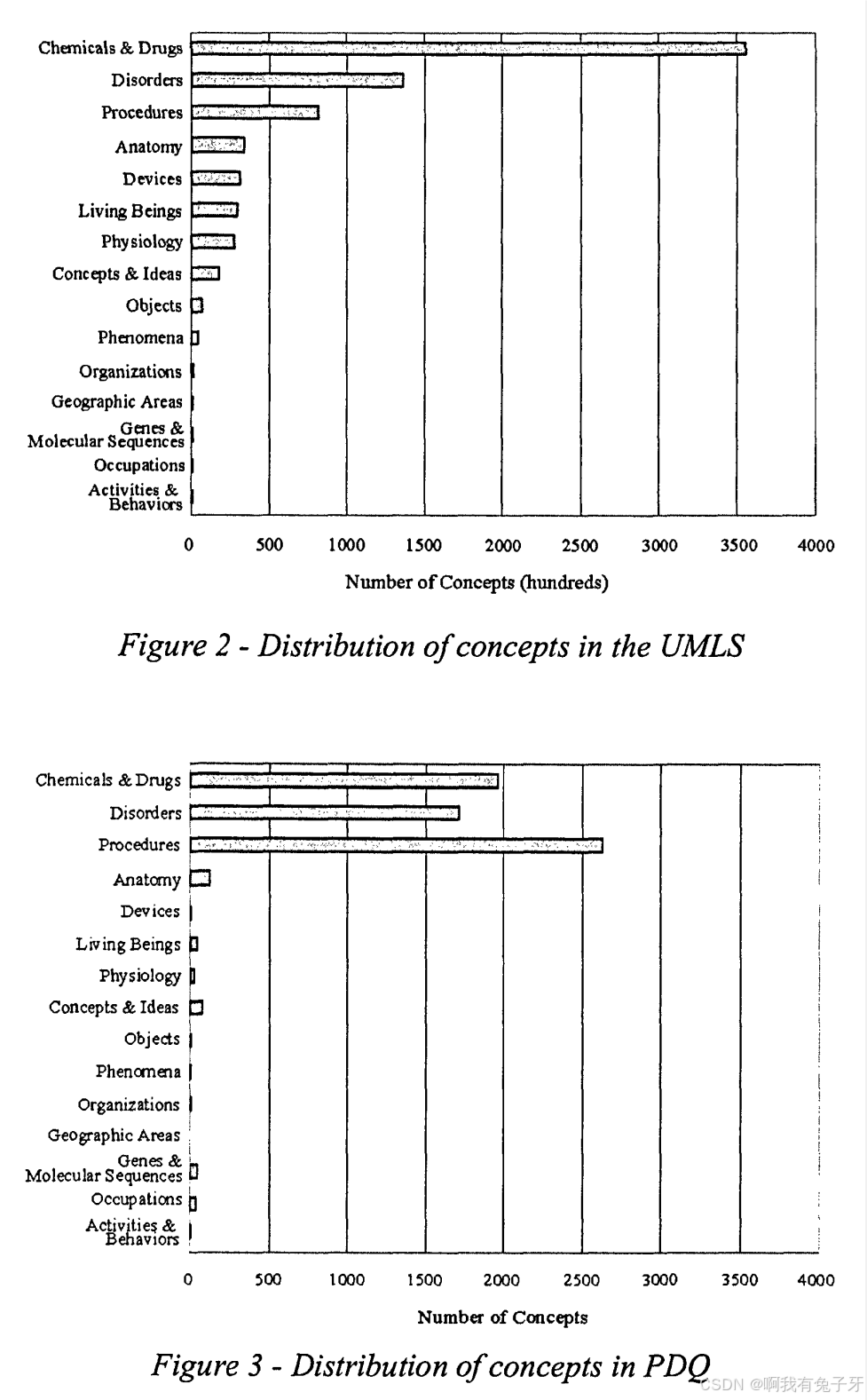
为了测试分组的效用,我们将 UMLS 中概念的分布作为一个整体与
概念在单个词汇表中的分布(PDQ 医生数据查询在线系统)。将图 2 与图 3 进行比较,我们可以一目了然地看到化学品和
在完整的 UMLS 中,药物代表了最大的一类概念,其次是疾病和程序;而在 PDQ 中,程序代表了最大的类别,其次是化学物质和药物,然后是疾病。这表明语义组可以很容易地用于创建一个词汇的高级概况,补充对该词汇的完整语义学的更详细分析。
结论
在某些情况下,我们试图创建一个连贯的、语义上有效的分组集时,不可能解决异常。这部分是因为意义本身的性质。一些概念在逻辑上属于多个语义组。例如,腺瘤可能同时被认为是解剖异常(可能必须通过手术切除)和疾病(有预后和潜在并发症)。在其他情况下,异常的出现是因为将语义类型分配给 UMLS 概念的错误或不一致。错误的例子包括错误地引用生理功能和分析该功能的程序的概念。例如,“肾小球过滤率” 被分配给 “生理学” 和 “程序语义组”,因为它被错误地分配了两种语义类型,“器官或组织功能” 和 “诊断程序”。,在少数情况下,语义类型之间的陈述关系也导致了适当分组语义类型的问题。因此,这里描述的方法提供了另一种 “审计” UMLS 数据的正确性和一致性的方法。(有关其他语义审计方法,请参阅 [12]。)在处理大型领域时,希望降低概念复杂性的原因有很多。我们提出了一种这样做的方法。由此产生的语义组可以用于显示目的;它们可以提供概念空间的广泛概述,例如术语系统中的表示;它们可能被用来发现该领域表示中的不一致之处。我们未来的工作将在 UMLS 的背景下研究其中的一些。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









