










Mixture-of-Partitions: Infusing Large Biomedical Knowledge Graphs into BERT - ACL Anthology
问题
在生物医学领域,由于公共训练语料有限且有噪声,如何将真实世界大规模生物医学知识图谱中的知识融入预训练模型,以提高知识密集型任务的性能。
挑战
- 生物医学知识图谱实体集非常大,例如 UMLS 包含约 4M 个实体,直接从这些大规模知识图谱中注入知识需要高度可扩展的解决方案。
- 现有的许多知识增强语言模型依赖计算昂贵的联合训练,存在灾难性遗忘风险。
- 对于实体级知识注入的常用方法(如实体掩码或预测),在生物医学知识图谱中,由于实体数量巨大,计算所有实体的精确 softmax 在训练和预测时非常昂贵,虽有负采样技术缓解计算问题,但调优负实例集具有挑战性,且预测大量标签可能泛化性差。
创新点
提出了 Mixture-of-Partitions (MoP) 方法,通过将知识图谱划分为较小子图,使用适配器学习子图特定知识,再通过混合层将子图知识整合到下游任务中,避免了对基础 BERT 模型参数的大量调整,有效利用了子图适配器的专业知识,提升了模型性能。
贡献
- 提出一种新的知识注入方法 MoP,能够处理大规模生物医学知识图谱,将其知识融入预训练模型。
- 通过实验证明 MoP 在多个下游任务(如 NLI、QA、分类等)中持续增强了基础 BERT 模型的性能,在五个评估数据集中取得了新的 SOTA 性能。
- 验证了所提出的分区策略有效保留了知识图谱中的丰富信息,并能够扩展到大规模图的训练。
提出的方法
- 知识图谱分区(Knowledge Graph Partitioning)
- 使用 METIS 算法将知识图谱 G 划分为多个子图,以满足保留尽可能多事实知识、平衡分区节点、高效处理大规模 KG 等目标。
- METIS 算法(Karypis 和 Kumar,1998 年)
【
METIS 算法是一种用于图分区的算法,在处理大规模图数据时具有重要作用,特别是在论文提出的 Mixture-of-Partitions (MoP) 方法中用于知识图谱的分区操作。
- 算法特点与功能
- METIS 算法能够处理亿级规模的图,其核心功能是将图的节点集划分为互斥的组,这对于 MoP 方法至关重要,因为它需要对知识图谱的知识三元组进行合理且自动的聚类,以支持数据并行性并控制计算量1。
- 该算法旨在满足以下目标:一是最大化保留结果知识三元组的数量,从而尽可能多地保留事实知识;二是平衡不同分区中的节点,减少不同实体预测头的总体参数;三是在处理大规模知识图谱时保证效率1。
- 工作原理
- METIS 算法通过连续地将大图粗化为较小的图,对这些较小的图进行快速处理,然后将分区投影回较大的图,以此来近似求解图分区问题。这种方式在保证分区质量的同时,有效地提高了处理大规模图数据的效率1。
- 应用场景
- 在论文的研究中,METIS 算法被用于将大规模生物医学知识图谱(如 SFull 和 S20Rel)划分为多个较小的子图,使得后续能够通过适配器在每个子图上学习特定知识,并通过混合层将这些子图知识整合到下游任务中,从而提升模型性能。此外,该算法在许多其他任务中也有广泛应用,如 Cluster - GCN 用于训练深度和大型图卷积网络等任务中(Chiang et al., 2019; Defferrard et al., 2016; Zheng et al., 2020)1。
】
- 使用适配器进行知识注入(Knowledge Infusion with Adapters)
- 对于每个子图,将其三元组转换为形式,使用 ADAPTER 模块通过最小化交叉熵损失来训练预测尾实体,在下游任务微调时,同时更新 ADAPTER 和预训练 LM 的参数。
- 混合层(Mixture Layers)
- 使用 AdapterFusion 混合层,通过 softmax 注意力层学习适配器的上下文混合权重,将不同适配器的知识组合用于下游任务预测,最终层用于预测任务标签。
指标
在不同下游任务中使用了多种指标评估模型性能,如问答任务(PubMedQA、BioAsq7b、BioAsq8b、MedQA)使用准确率(Accuracy),文档分类任务(HoC)使用平均微 F1 值(average micro F1),自然语言推理任务(MedNLI)使用准确率。
模型结构
- 整体结构包括知识图谱分区、使用适配器注入知识、收集预训练适配器和通过混合层组合适配器知识四个主要部分(如图 1 所示)。
- 具体而言,对于每个子图,在 Transformer 层间插入 ADAPTER 模块,通过特定方式处理子图三元组进行训练;在下游任务中,通过 AdapterFusion 混合层根据学习到的权重组合不同适配器输出,最终得到任务预测结果。
结论
提出的 MoP 方法通过将知识图谱分区并利用适配器和混合层,能有效利用子图知识提升下游任务性能,在多个任务和数据集上得到验证,且分区策略保留了知识图谱信息并可扩展训练。
剩余挑战和未来工作
- 虽然 MoP 在处理大规模生物医学知识图谱方面取得一定成果,但仍需进一步探索如何更好地处理更大规模、更复杂的知识图谱。
- 未来计划使用一些通用领域知识图谱基于通用领域任务评估该方法的有效性,探索其在不同领域的适用性和扩展性。
数据集
- 生物医学知识图谱
- SFull:从 UMLS 中提取,包含 302,332 个实体、229 种关系和 4,129,726 个三元组,具有完整的关系和实体。
- S20Rel:是 SFull 的子集,包含 263,808 个实体、20 种关系和 1,750,677 个三元组,仅包含最频繁的 20 种关系(排除反向关系)。
- 下游任务数据集
- PubMedQA:问答数据集,包含研究问题、参考文本及答案标注(yes/maybe/no),有 450/50/500 个问题的训练 / 开发 / 测试集,评估指标为准确率,实验中取 10 次运行的平均值。
- BioAsq7b 和 BioAsq8b:均为 yes/no 问答任务数据集,由生物医学专家标注,每个问题配有参考文本和答案,分别有 670/75/140 和 729/152/152 的训练 / 开发 / 测试集,评估指标为准确率,实验中取 10 次运行的平均值。
- MedQA:大规模多选项问答数据集,来自专业医学委员会考试,本文仅采用英语集,使用 Elasticsearch 系统为每个问题 - 选项对检索上下文,评估指标为准确率,由于数据集大,所有模型仅报告 3 次运行的平均准确率。
- HoC:文档分类数据集,从 1852 篇 PubMed 出版物摘要中提取,根据癌症特征分类法手动标注类别标签,本文考虑十个顶级类别,使用公开的训练 / 开发 / 测试集,评估指标为平均微 F1 值,报告五次运行的平均值。
- MedNLI:自然语言推理数据集,从 MIMIC - III 临床数据库中提取句子对,任务是判断假设是否能从前提中推断出来,有三个标签(entailment、contradiction、neutral),使用相同的训练 / 开发 / 测试集,评估指标为准确率,报告三次运行的平均值。
抽象
将事实知识注入预训练模型是许多知识密集型任务的基础。在本文中,我们提出了 Mixture-of-Partitions (MoP),这是一种注入方法,可以通过将非常大的知识图谱 (KG) 划分为更小的子图,并使用轻量级适配器将其特定知识注入各种 BERT 模型来处理。为了利用目标任务的整体事实知识,这些子图适配器通过混合层与底层 BERT 一起进一步微调。我们使用三个生物医学 BERT (SciBERT、BioBERT、PubmedBERT) 在六个下游任务 (包括 NLI、QA、分类) 上评估我们的 MoP,结果表明,我们的 MoP 在任务性能方面持续增强底层 BERT,并在五个评估数据集上实现了新的 SOTA 性能。1
1 引言
利用事实知识来增强预训练的语言模型对于知识密集型任务(例如问答和事实核查)至关重要(Petroni et al., 2021)。特别是在公共培训语料库有限且嘈杂的生物医学领域,值得信赖的生物医学 KG 对于得出准确的推断至关重要(Li et al., 2020;Liu et al., 2021)。然而,从现实世界的生物医学 KG 中注入知识,其中实体集非常大(例如 UMLS,Bodenreider 2004,包含 ∼4M 实体)需要高度可扩展的解决方案。
尽管已经提出了许多常识增强语言模型,但其中大多数都依赖于底层掩码语言模型 (MLM) 的计算成本高昂的联合训练以及知识注入目标函数,以最大限度地降低灾难性遗忘的风险(Xiong et al., 2019;Zhang等人,2019 年;王
等人,2021 年、2020 年;Peters et al., 2019;Yuan等人,2021 年)。或者,实体掩码(或实体预测)已成为将实体级知识注入预训练模型中的最流行的自我监督训练目标之一(Sun et al., 2019;Zhang等人,2019 年;Yu et al., 2020;He et al., 2020)。然而,由于生物医学 KG 中的实体数量众多,因此计算所有实体的精确 softmax 对于训练和预测来说非常昂贵(De Cao et al., 2021)。尽管负采样技术可以缓解计算问题(Sun et al., 2020),但调整一组适当困难的负实例可能具有挑战性,并且预测大量标签的泛化效果可能很差(Hinton et al., 2015)。
为了应对上述挑战,我们提出了一种新颖的知识注入方法,称为分区混合 (MoP),将基于分区 KG 的事实知识注入到预训练模型中(BioBERT、Lee 等人,2020 年;SciBERT, Beltagy 等人,2019 年;和 PubMedBERT, Gu et al. 2020)。更具体地说,我们首先使用 METIS 算法(Karypis 和 Kumar,1998 年)将一个 KG 划分为几个子图,每个子图包含其实体的不相交子集,然后是 Transformer ADAPTER 模块(Houlsby等人,2019 年;Pfeiffer et al., 2020b) 用于从每个子图中学习可移植的知识参数。特别是,使用 ADAPTER 模块注入知识不需要对底层 BERT 的参数进行微调,在避免灾难性遗忘问题的同时,更加灵活和高效。为了利用从子图适配器中独立学习的知识,我们引入了混合层,以自动将这些适配器中的有用知识路由到下游任务。图 1 说明了我们的方法。
我们的结果和分析表明,我们的 “分而治之” 分区策略有效地保留了 UMLS 的两个生物医学 KG 中呈现的丰富信息,同时使我们能够在这些非常大的图表上扩大训练规模。此外,我们观察到,虽然单个适配器专注于子图特定知识,但 MoP 可以有效地利用他们的个人专业知识来提高我们测试的生物医学 BERT 在六个下游任务上的性能,其中五个任务实现了新的 SOTA 性能。
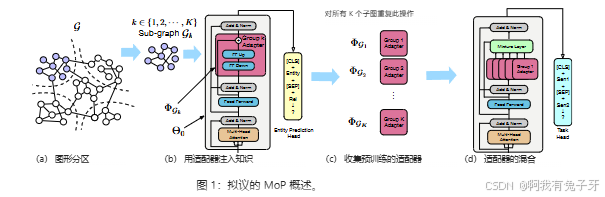
2 分区混合 (MoP)
我们将 KG 表示为有序三元组 tE 8,rE R),其中 ε 和 R 分别是实体和关系的集合。所有实体和关系都与其文本表面形式相关联,这些表面形式可以是单个单词(例如 fever)、一个化合物(例如 sars-cov-2)或一个短语(例如 has finding site)。
给定一个预训练模型 ,我们的任务是根据输入知识图谱 G 学习 ,以便它封装了 9 中的知识。训练目标 可以通过多种方式实现,例如关系分类(Wang et al., 2020)、实体链接(Peters et al., 2019)、下一句预测(Goodwin and Demner-Fushman, 2020)或实体预测(Sun et al., 2019)。在本文中,我们重点介绍了实体预测,这是使用最广泛的目标之一,并将其他目标的探索留给未来的工作。
如前所述,对所有实体的精确 softmax 非常昂贵(Mikolov 等人,2013 年;De Cao et al., 2021)进行分配,因此我们采用“分而治之”的原则,并提出了一种称为 Mixture-ofPartition (MoP) 的新方法。具体来说,我们的 MoP 首先将一个大的 KG 划分为更小的子图(即 , §2.1),并分别学习每个子图上的子图特定参数(即 , §2.2)。然后,这些子图参数通过混合层进行微调,以路由特定于
知识添加到目标任务中 (§2.3)。
2.1 知识图谱分区
图形分区(即将节点集划分为互斥的组)是我们方法的关键步骤,因为我们需要正确和自动地对知识三元组进行聚类,以支持数据并行性和控制计算。特别是,它必须满足以下目标:(1) 最大化结果知识三元组的数量,以保留尽可能多的事实知识;(2) 平衡分区上的节点以减少不同实体预测头之间的总体参数;(3) 处理大型 KG 的大规模效率。事实上,(1) 和 (2) 的精确解被称为平衡图分区问题,即 NP 完备。我们使用 METIS (Karypis and Kumar, 1998) 算法作为近似值,同时满足上述所有三个要求。METIS 可以通过连续将大图粗化为小图,快速处理它们,然后将分区投影回更大的图上来处理十亿级图,并已用于许多任务(Chiang et al., 2019;Defferrard et al., 2016;Zheng et al., 2020)。
2.2 使用适配器进行知识灌注
对大型知识图进行分区后,我们使用 ADAPTER 模块通过为每个子图训练实体预测目标,将事实知识注入预训练的 Transformer 模型中。适配器(Houlsby等人,2019 年;Pfeiffer et al., 2020b)是插入预训练模型的 Transformer 层之间的新初始化模块。ADAPTER 的训练不需要微调预训练模型的现有参数。相反,仅更新 ADAPTER 模块中的参数。在
在本文中,我们使用了 Pfeiffer 等人 (2020a) 配置的 ADAPTER 模块,如图 1 (b) 所示。特别是,给定一个子图 ,我们删除了每个三元组 nd 将三元组转换为标记列表的尾部实体名称:。特定于子图的 ADAPTER 模块经过训练,使用 [CLS] 标记的表示来预测尾部实体,并通过最小化交叉熵损失来优化参数 。在下游任务的微调过程中,ADAPTER 和预训练 LM 的参数都会被更新。[CLS] h [SEP] r [SEP]'$。特定于子图的 ADAPTER 模块经过训练,使用 [CLS] 标记的表示来预测尾部实体,并通过最小化交叉熵损失来优化参数 2ef73573-3b00-45a0-b71c-648e9200d88a。在下游任务的微调过程中,ADAPTER 和预训练 LM 的参数都会被更新。
2.3 混合层
给定一组知识封装的适配器,我们使用 AdapterFusion 混合层来组合来自不同适配器的知识,以执行下游任务。AdapterFusion 是最近提出的一个模型 (Pfeiffer et al., 2020a),它学习通过 softmax 注意力层组合来自一组任务适配器的信息。它使用 softmax 权重的注意来学习第 l 层适配器上的上下文混合权重:,其中 用于混合要传递到下一层的适配器输出,最后一层 L 用于预测任务标签 y:,其中 f 是目标任务预测头。与我们的密切相关的是稀疏门控的 Mixture-ofExperts 层(Shazeer et al., 2017)。或者,可以使用更灵活的机制,例如 GumbelSoftmax(Jang et al., 2017)来获得更多离散 / 连续的混合物重量。但是,我们发现这两种替代方案都表现不佳 AdapterFusion(请参阅附录进行比较)。
我们在两个 KG 上评估我们提出的 MoP,名为 SFull 和 S20Rel,它们是从 SNOMED CT, US Edition 词汇表下的大型生物医学知识图谱 UMLS(Bodenreider,2004)中提取的。SFull KG 包含 SNOMED2 的完整关系和实体,而 S20Rel KG 是 SFull 的子集,仅包含前 20 个最常见的关系。请注意,由于 SFull 中的一些关系是相同实体对的反向映射,例如 “A 有病原体和的病原体,因此对于 S20Rel,我们排除了前 20 个关系中的那些反向关系。表 2 显示了两个 KG 的统计数据,并在附录中列出了 S20Rel 的使用的 20 个关系。
3.2 评估的任务和数据集
我们在各种下游任务的六个数据集上评估我们的 MoP,包括四个问答(即 PubMedQA,jin 等人 2019 年;BioAsq7b,Nentidis 等人 2019 年;BioAsq8b,Nentidis 等人 2020 年;MedQA,jin 等人 2020 年),一个文档分类(HoC,Baker 和 Korhonen 2017 年)和一个自然语言推理(MedNLI,Romanov 和 Shivade 2018 年)数据集。虽然 HoC 是多标签分类,MedQA 是多选预测,但其余的可以表述为
二进制 / 多类分类任务。有关这些任务及其数据集的详细描述,请参阅附录。
3.3 使用基本模型进行预训练
我们实验了三个生物医学预训练模型,即 BioBERT(Lee et al.,2020)、SciBERT(Beltagy et al.,2019)和 PubMedBERT(Guu et al.,2020),作为我们的基本模型,它们在生物医学文本挖掘任务中显示出强劲的进展。我们首先将我们的 KG 划分为不同数量的子图(即 {5,10,20,40}),然后对于每个子图,我们通过最小化交叉熵损失来训练加载了新初始化的 ADAPTER 模块(压缩率)的基本模型 1-2 个时期。AdamW(LoshChilov and Hutter,2018)被用作我们的训练优化器,所有子图的学习率都固定为 1e−4,如(Pfeiffer et al.,2020b)所建议的那样。除非另有说明,否则所有报告的性能都基于 20 个子图的分区,因为这对于任务性能是最佳的(有关不同数量分区的性能,请参阅第 3.7 节。)。
3.4 任务分区评估
在图 2 中,我们报告了知识注入 PubMedBERT 在分区 SFull 上的两个 QA 数据集上的平均性能(10 次运行)。我们可以看到分区的贡献程度不同,而有些分区(例如 #5)的好处可以忽略不计。然而,
贡献最小的分区的作用不能被丢弃,因为我们通过只保留前 10 个执行分区来重复下游任务,并观察到结果仍然比在所有 20 个分区上训练的模型差(即 PubMedQA 上的准确度下降 2.7,BioASQ7b 上的准确度下降 1.4)。3 这突出了自动学习分区贡献权重的重要性。
表 3:不同混洗比率下的训练三元组数。0% 混洗率表示 METIS 20 个分区子图,100% 是完全随机生成的分区。
3.5 MoP 对任务的评估
表 1 显示了我们部署在 SciBERT、BioBERT 和 PubMedBERT 预训练模型上的 MoP 的整体性能。我们看到,在 SFull KG 上预训练的 MoP 对所有任务都改进了 BioBERT 和 PubMedBERT 模型,而 SciBERT 模型也可以在 6 个任务中的 4 个任务上得到改进。结果表明,使用 S20Rel KG 预训练的 MoP 在 4 个任务上实现了新的 SOTA 性能。这表明进一步修剪知识三元组通过降低噪声来提高任务性能,是未来探索的一个有希望的方向。
3.6 METIS 分区质量
我们设计了一个受控的随机分区方案来测试 METIS 是否可以产生高质量的分区用于训练。我们为 METIS 产生的 20 个分区结果固定实体大小,并在所有子图上随机洗牌一个百分比(范围从 0%100%)的实体。表 3 显示了不同洗牌比率下训练三元数的数量。在图 3 中我们报告了 BioASQ7b 和 PubMedQA 在不同洗牌速率下的结果。我们可以看到 MoP 在两个数据集上的性能随着洗牌速率的增加而显著下降,这突出了所产生分区的质量。
.7 性能与分区数
表 4 显示了在 SFull 知识图上训练的 PubMedBERT+MoP 在不同数量分区上的性能。我们可以清楚地看到,在 20 个分区下,PubMedBERT+MoP 在 BioASQ7b 和 PubMedQA 数据集中表现最好,子图的平均实体大小为 15k-30k 通常会产生比其他更好的性能。
3.8 案例研究
在图 4 中,我们展示了来自 BioASQ8b 的六个例子(为了简洁起见,省略了上下文),并比较了 PubMedBERT+MoP(SFull)模型推断的最后一层 [CLS] 标记的混合权重。我们看到每个问题都引出了不同的混合权重,这表明 MoP 可以根据目标示例利用不同子图的专业知识。我们还将单词云绘制在六组子图上,这些子图根据实体名称的 TF-IDF 由 k-means 聚类
这些子图的特征。我们可以观察到 MoP 为每个示例识别了最相关的子图(例如 Q2 在子图 [1,13,14] 上有更多的权重,子图专门研究 “肿瘤” 知识)。这验证了我们的 MoP 在跨适配器平衡有用知识方面的有效性。
子图 [9.10]
子图 [16,17,18,19] 可移动实体
1
第 12 层令牌 [CLS] 的混合重量
图 4:顶部:从 20 个子图聚集的 6 组单词云。中间:在 6 个问题上混合 MoP 权重。底部:来自 BioASQ8b 的 6 个问题。
4 结论和未来工作
在本文中,我们提出了 MoP,这是一种通过将知识图划分为更小的子图来注入知识的新方法。我们表明,虽然 knowledge-encapsulated 适配器在不同的子图上表现非常不同,但我们提出的 MoP 可以自动利用和平衡这些适配器之间的有用知识来增强各种下游任务。将来,我们将根据一些通用领域任务使用一些通用领域 KG 来评估我们的方法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









