




 本文介绍了LDA主题模型的原理,通过非监督学习从大规模文本中识别潜在主题。LDA将每篇文档视为词频向量,通过随机选择主题和单词生成文档。文中展示了使用LDA提取关键词的步骤,包括数据爬取、清洗、主题提取和可视化,以体育、房地产等领域为例,说明如何构建领域词典。
本文介绍了LDA主题模型的原理,通过非监督学习从大规模文本中识别潜在主题。LDA将每篇文档视为词频向量,通过随机选择主题和单词生成文档。文中展示了使用LDA提取关键词的步骤,包括数据爬取、清洗、主题提取和可视化,以体育、房地产等领域为例,说明如何构建领域词典。
词典构造方法之LDA主题模型
主题模型LDA原理理解
LDA是一种非监督学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
举例来说,假设一个语料库中有三个主题:体育,科技,电影 。一篇描述电影制作过程的文档,可能同时包含主题科技和主题电影,而主题科技中有一系列的词,这些词和科技有关,并且他们有一个概率,代表的是在主题为科技的文章中该词出现的概率。同理在主题电影中也有一系列和电影有关的词,并对应一个出现概率。当生成一篇关于电影制作的文档时,首先随机选择某一主题,选择到科技和电影两主题的概率更高(这三个主题的概率分布决定大小);然后选择单词,选择到那些和主题相关的词的概率更高(主题下面的选的词也是符合一定的概率分布的)。这样就就完成了一个单词的选择。不断选择N个单词,这样就组成了一篇文档。
那么,如果我们要生成一篇文档,它里面的每个词语出现的概率为:
P(word│document)=∑P(word│topic)×P(topic∣document)P(word│document)=∑P(word│topic)×P(topic|document) P(word│document)=∑P(word│topic)×P(topic∣document)
这个其实可以更加形象表示如下:
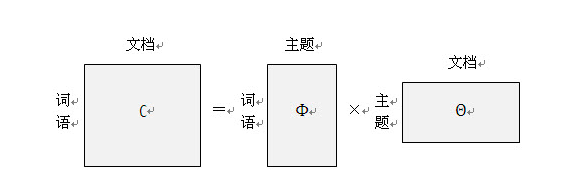
LDA提取关键词和可视化
了解LDA的一些基本原理后,我们可以很轻松就可以利用LDA找出文章的主题词。因为LDA模型每次都可以找到这个主题的单词,我们只要把数据主题数目topic_num确定下来就可以构建这个领域的词典。
其构建词典的步骤可以归纳如下:
(1) 利用八爪鱼 ,Web 爬虫完成数据的爬取,并存储到本地,获取的数据。
(2) 对所获的大宗语料数据进行处理操作,有数据清洗、分词、停用词过滤、词性标注等处理。
(3) 用LDA方法构造基础领域词典,并可视化。
读取文件
数据集选新闻数据10类,事现人工标注好,这样分类的时候可以直接设置topic_num = 10
label都有’时尚’,‘财经’,‘科技’,‘游戏’,‘房产’,‘娱乐’,‘时政’,‘体育’,‘家具’。
import pandas as pd
import numpy as np
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









